

通過灰盒Fuzzing技術來發現Mac OS X安全漏洞
責編:admin |2015-07-17 13:50:51通過灰盒Fuzzing技術來發現Mac OS X安全漏洞
原文地址:security.di.unimi.it/~joystick/pubs/eurosec14.pdf
注:部分不太重要的沒有翻譯。
內核是所有操作系統的核心,它的安全性非常重要。任何地方一個漏洞,都足以危害整個系統的安全。非特權用戶如果找到這樣的漏洞可以輕松的使整個系統 崩潰,也或者取得管理員權限。可見,內核對攻擊者來說更具吸引力,內核漏洞的數量也在以一個不安的趨勢在上升。因為太復雜。在內核層挖掘漏洞是一件讓人畏懼的事情。的確,現代內核是非常的復雜還含有很多子系統,有些是第三方開發的。通常,第三方開發的內核擴展組件沒有內核本身那樣安全。因為第三方組件不是 開源的,也缺乏足夠的測試。另外,內核有太多的用戶數據接口。系統調用,文件系統和網絡連接等允許用戶提交數據到重要的代碼路徑。如果在其中找到一個 bug,足以威脅到系統安全。測試用戶層到內核的接口十分重要,因為它能夠實現提權攻擊。這是現在大多數攻擊者想做的。
Windows和Linux系統的內核接口已經被深入的分析,并且有很多工具用來進行檢測。但在Mac OS X上,內核提供給擴展的接口交互方法相對來說還沒有被廣泛深入的分析。另外,OS X系統的市場份額正在穩步提升,它將吸引更多的網絡犯罪分子的注意力。本文中,筆者闡述了一個自動在內核擴展中發現漏洞的framework。 LynxFuzzer的設計和實現。其可以自動加載Mac OS X的內核組件。OS X內核擴展稱作Kext。使用蘋果公司提供的IOKit framework來進行開發。LynxFuzze使用灰盒fuzzing技術動態的生成測試數據。其機理是自動從內核擴展中提取數據,并使用它們來動態 生成輸入數據。進一步說,筆者在LynxFuzzer中實現了3種不同的fuzzing引擎:簡單數據引擎的是根據內核擴展定義來產生偽隨機輸入數據。突 變引擎是根據嗅探到的合法數據來進行變異來生成輸入數據。最后一個是進化引擎,根據進化算法,使用代碼覆蓋率來作為主要的驗證特征。
筆者決定在開源的,通過硬件輔助的虛擬化內核調試器HyperDbg的基礎上開發LynxFuzzer。主要是因為Mac OS X在現有的虛擬化軟件中運行會遇到很多困難。實際上蘋果公司一向以其定制化硬件出名。并不能被普通的調試器模擬。這個缺點阻礙了LynxFuzzer測試 一些OS X上的驅動。另外,一個硬件輔助環境可以保證在系統崩潰時,收集到關于機器的動態信息。總的來說筆者的工作做出了一下幾點成果:
筆者設計了LynxFuzzer來自動發現內核擴展的漏洞,比如動態的加載內核模塊。筆者解決了幾個實際困難來實現這一有效的fuzzing系統。
筆者發明了一些有效的透明的技術來自動生成fuzzing輸入,從而減少輸入的搜尋范圍,提高對Mac OS X用戶態和內核交互接口fuzzing的效率。
筆者擴展了一種fuzzing系統。并且在一些擴展上做了實踐。筆者的實驗發現了6個bug。在筆者分析的17個擴展之中。其中兩個已經在OS X 10.9種被修補。其CVE編號為CVE-2013-5166和CVE-2013-5192。
01 IOKit基礎
在這一節中,筆者將要簡要介紹IOKit framework。這是理解LynxFuzzer的基礎。
Mac OS X是蘋果公司開發的操作系統,用于蘋果電腦。在它的眾多組件中,IOKit是對筆者來說是特別重要的。IOKit是一個系統框架,庫,工具和其他資源的集 合。用來在OS X上開發設備驅動。它提供了一個面向對象的編程環境,和一些使得開發內核組件更加簡單,用戶體驗更好的抽象對象。在下面結合筆者的工作來做一些闡述。
任何一個OS的基本組件就是用戶態與內核空間的交互通信組件。Windows和Linux通過系統調用system call和特殊的虛擬文件(例如:/dev/urandom)。IOKit支持這兩種技術,但是還新增了一種新奇的更加復雜的機制,叫做設備接口 (DevieceInterface)。

為了實現這種機制,內核擴展定義了一系列的可以在用戶態被調用的方法。這些方法返回的參數的數量和數據的類型是被限制的。這些方法的列表和參數的限 制都都存貯在被極度重要的結構體里面:這就是分派表(dispatch table)。每一個kext都可以定義一個或多個分派表。每個表都是一組結構體。每一個都包含了一個函數指針,允許的輸入值和輸出值,還有該方法允許接 收或返回的值的數量和大小。如果輸入結構體的大小不需要在輸入前檢驗,可以將大小在表中聲明為ffffffff,然后由接收函數進行檢驗。任何驅動都 可以擁有一個以上的分派表。IOKit允許擴展在同一時刻提供給用戶空間程序以多個接口。每個kext都必須為每一個接口定義一個UserClient的 子類。這些子類的實例隨后與kext一起加載到內核內存(圖2)。每一個UserClient對象都包含一個與它提供接口對應的分派表。
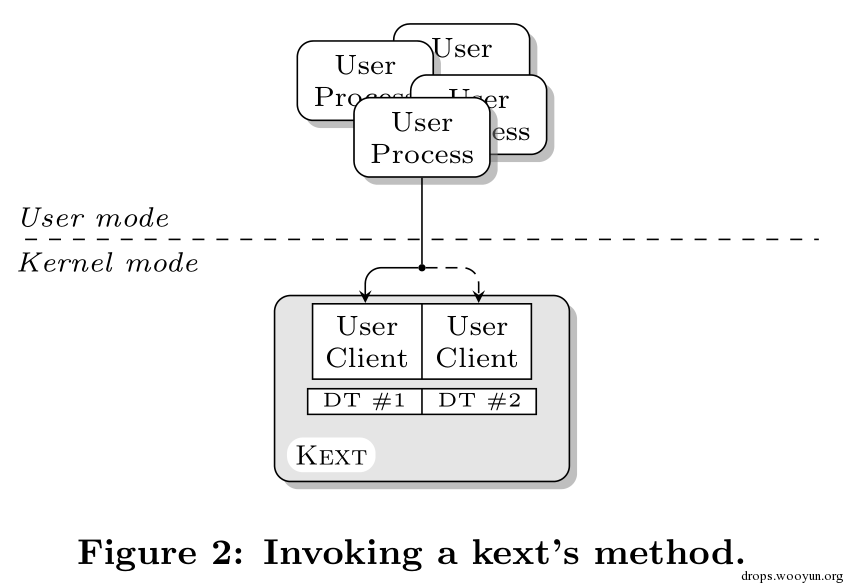
用戶態程序可以通過IoConnectCallMethod()來調用kext的方法,前提是這個方法已經在kext分派表中。當然,用戶態程序需 要必須先找到目標實例。想解釋這一過程,筆者首先需要介紹一個IOKit抽象類:IOService。每一個IOKit設備驅動都是繼承于它的對象,一個 kext可以同時擁有不同的IOService對象。舉例說明,具有代表性的就是同時有幾個USB設備連接到電腦,每個都需要它自己的驅動。這些驅動都被 包含在IOUSBFamily kext中,每一個都是一個特殊的IOService的子類。當一個用戶態程序想要和一個設備交互時,像前面提到的一樣,它會與IOKit建立一個 mach連接,然后尋找合適的服務來適應設備。這個過程叫做Device Matching。
如果找到服務成功,交互通道也成功建立,用戶態程序就會使用IoConnectCallMethod()來調用目標方法。在真正執行目標函數之前, 程序會將控制權交給IOKit framework,由IOKit framework執行一系列操作。首先,它查詢UserClient對象的分派表入口。入口地址隨后被傳送給externalMethod()函數,同 時還有其他被執行調用kext方法所允許的參數。只有參數符合分派表要求的情況下,方法才會被調用,不然就會被阻止。
相對于一般的機制,如ioctl,整個IOKit輸入控制機制提供了一個保護層。參數檢查會在由用戶層進入驅動層之前進行。顯而易見,這些約束都使 得fuzzing工作變得更加復雜。使用完全隨機的參數大小來對kext的函數進行fuzz幾乎是無效的。絕大多數的調用請求都會被IOKit檢查并丟棄 掉。筆者在下一節會看到,筆者fuzzer的重要一個特性就是能自動從目標中提取到參數限制,之后動態適應限制,讓fuzzing更加的高效。
02 LynxFuzzer
筆者fuzzer的目的是在能被用戶態程序調用到的kext code中發現bugs。一個可以從用戶態激發的bug可以讓非特權用戶崩潰掉整個系統的。也甚至是執行任意內核代碼。從而達到提權攻擊。所以,筆者決定 將筆者的注意力集中到設備接口跨界機制(DeviceInterface boundary-crossing mechanism),因為它是OS X內核擴展機制中用戶層和內核交互的標準。
在上一節中,需要指出的是在調用一個kext方法時,很多的約束必須得到考慮。對于每個kext來說是不同的。知道分派表中的約束能減小筆者 fuzzing工作量。提高fuzzing的效率。所以筆者設計的LynxFuzzer能夠全自動的提取信息,然后自動的進行fuzz。當然,筆者的 fuzzing基礎設計的自動化功能不止于此。事實上,筆者能提取到在用戶態和內核態組件非人工交互的合法有效輸入向量。這些輸入可以經過精心使用來加強 筆者的fuzzing策略。
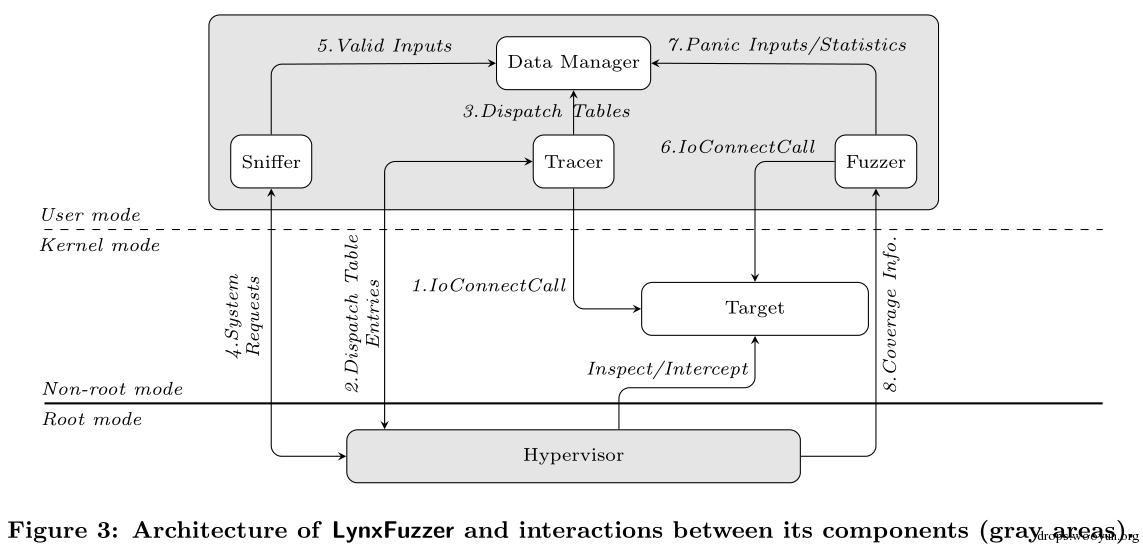
LynxFuzzer的基本結構可以從圖3中看到,框架擁有兩個主要的組件:一個在用戶態,有4個子組件構成。另一個構建在調試器分析框架上。圖3 中還說明了LynxFuzzer內部組件的主要交互行為。tracer和調試器(hypervisor)交互得到目標分派表。一旦發現,調試器就從內核內 存中取回分派表的地址,返回給tracer,tracer將其保存到data manager中以待后面使用。sniffer使用這些信息來攔截非人工的IoConnectCall()調用,收集到一些有效的輸入。最后fuzzer 組件開始使用自定義的參數來調用目標方法。等待最后的異常。fuzzer可以使用之前存貯的數據生成新的輸入數據或者使用覆蓋突變方法來生成輸入,這取決 于fuzzer引擎的選擇。
2.1 Tracer
tracer是LynxFuzzer的第一個運行的組件,它的任務是找到fuzz的目標。舉例,它必須確定目標的哪個方法是能夠被調用的。這些信息 包含在目標kext的分派表中。然而,定位一個kext的分派表并不簡單,因為IOKIt使用很多抽象層來對用戶層隱藏信息。筆者的解決方案是:任何時候 用戶態程序調用IoConnectCallMethod(),IOKit將會調用它的externalMethod()函數,筆者對此進行監視。通過以下 方法來實現,LynxFuzzer調試器對externalMethod()函數下一個斷點,截斷對它的調用。一旦這個陷阱(trap)被設置 好,tracer就對目標kext發起一個請求,其selector參數為0。當調試器截斷externalMethod(),就提取分派表的基地址。然 后dump整個分派表,將它返回給tracer。最終,tracer存貯分派表到data maanger,分享給其它組件使用。
分派表的大小事先是不知道的。也不在被截斷函數的參數里面。為了解決這個問題,LynxFuzzer分析分派表的結構推斷出其擁有多少個入口,然后 dump下來。事實上,每個表的入口由一個指針,該指針必須在目標的內存范圍內。和4個連續的整數,其中兩個必須在0-15之間。
2.2 Sniffer
除了IOKit的檢查,kext自己可以實現對輸入的約束。所以LynxFuzzer包含了一個sniffer組件。該組件用來截斷目標方法的執 行,提取到它們的參數。為了實現這個筆者再次利用LynxFuzzer的調試器,它可以透明的無縫的截斷筆者感興趣的函數,通過檢查目標kext的內存來 dump它的參數。
特別的,調試器對于externalMethod()函數來說是透明的。該函數的參數包含了足夠的信息來獲取有效的輸入。事實上,調試器用 dispatch參數來區分出是哪一個kext是這次截斷的目標。用selector參數來確定是哪一個方法被調用。 IOExternalMethodArguments結構中包含了真正的傳遞進來的參數。這種結構中還包含了參數的數量和大小。它們都將會被保存到 data manager。
2.3 Fuzzer
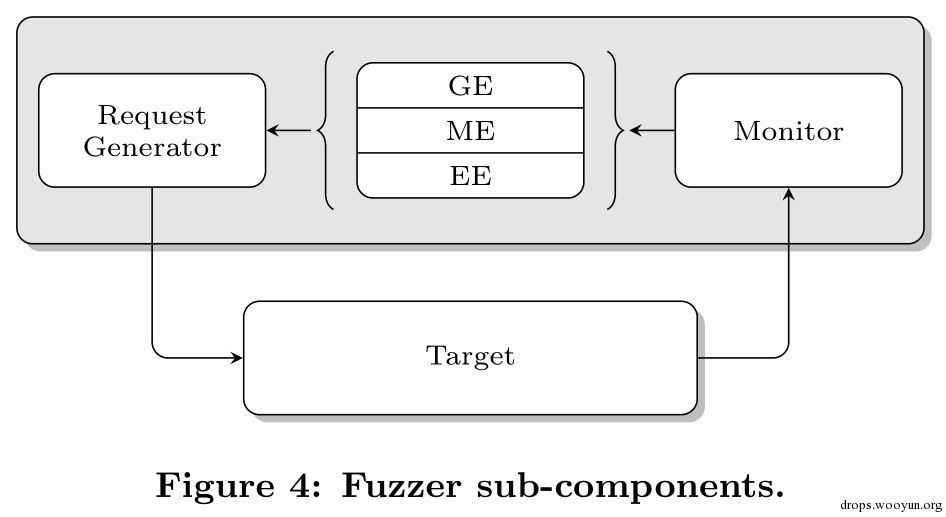
fuzzer是LynxFuzzer的主要組件。當tracer盒sniffer獲取了足夠的輔助信息可以進行fuzz一個kext 時,fuzzer生成對kext方法的測試集,然后通過IOKit設備接口來調用方法。圖4顯示了該組件的結構:一個請求生成器,一組fuzzing引擎 和一個監視器。 請求生成器是一個通用的組件:它必須獨立于目標kext和選擇的fuzzing引擎來運轉。在一次典型的執行中,它從fuzzing引擎中接收到測試數據 之后,檢查數據是否符合分派表中聲明目標方法的要求,適當的調整以符合最后在kext中執行目標方法的IoConncetCallMethod()函數. 如果測試數據沒有導致崩潰,kext發出一個回應,由monitor來接收。monitor根據接收到的放回數據和當前的fuzzing引擎來決定是否繼 續使用當前的引擎。所以后一個測試基于前一個測試反饋的。突變引擎和進化引擎都會使用該模式。
LynxFuzzer實現了基于會話的fuzzing:筆者不多余操作,只需要發出尋找bug的請求。但是筆者要從每個fuzzing會話開始記錄 每一個請求。這種方法很常見,特別是在fuzzing基于狀態的網絡協議的時候,在這種情景下也是適用的。事實上kext也擁有一種狀態。這種狀態會隨著 大量不同的fuzzing請求而變化,直到進入非正常的狀態,一個bug被觸發。出于這種原因,使用基于會話的記錄,代替單個的請求會極大的保證一個 bug的可重現性。記錄fuzzer和目標kext之間的交互會話,每一個請求都被存貯在data manager中,最終fuzzer對輸入數據的生成也是由影響的。LynxFuzzer三種不同引擎的細節筆者馬上給出。
2.3.1 隨機引擎(Generation Engine)
這是最簡單快速的引擎。它的生成過程可以簡述如下,第一步,它生成可以包含輸入數據到目標方法的數據結構。第二步,生成偽隨機數據來填充這個結構體。最后,將數據通過IoConnectCallMethod()發送給目標。如果系統沒有崩潰就繼續反復這一過程。
2.3.2 突變引擎(Mutation Engine)
這種fuzzing方法遵循一個原則就是站在前者數據的對立面:每一個新的輸入數據都是從sniffer組件收集到的有效輸入數據變化生成。 fuzzing的過程也比較簡單:使用不同的突變函數將sniffer收集到的有效輸入數據進行變異,然后使用突變后的數據進行請求。如果系統沒有崩 潰,monitor會檢查kext給出的返回值。盡可能的將會導致kext返回error的輸入值排除在下一個突變生成之外。這極大的提高了fuzzer 的效率。特別是在輸入結構時可變大小的時候,因為它逐步去除了那些在目標方法中被檢查非法的輸入。這個引擎使用的突變函數有:位翻轉,字節翻轉,字節交換 和大小改變。
2.3.3 進化引擎(Evolution Engine)
進化引擎試圖突破其他引擎的限制。盡量少的使用偽隨機。利用進化算法來生成新的輸入數據。
任何進化算法的核心就是適應函數(fitness function)。它定義了生成器使用的最佳元素。在LynxFuzzer里,筆者開發了兩種適應函數:一個測量輸入向量的代碼的覆蓋率。另一個測量輸 入和最佳輸入向量(導致崩潰的輸入)的差距。在第一種情況中,筆者極力去生成一組輸入向量來給筆者最佳的代碼覆蓋率。第二種情況在筆者想在定制一個給定向 量(比如一個會觸發bug的向量)的時很有用。
代碼覆蓋率分析。筆者的代碼覆蓋率分析方法如下:在開始調用kext方法之前,fuzzer組件告知調試器kext的代碼范圍。調試器將相應代碼內 存段的可執行屬性在EPT(Extended Page Tables)入口中移除。這樣只要kext執行相應頁的代碼時就會觸發一個EPT違規。調試器跟蹤到導致違規的指令。為了繼續,調試器重新將不可執行夜 標志為可執行,同時讓程序單步執行。當調試器由于調試異常而重新獲得控制權,它再將這個可執行權限移除,所以下一個指令還是會產生執行違規。當被fuzz 的方法返回,fuzzer發出調用來解除跟蹤。調試器存貯收集到的信息到fuzzer的一塊空間中,讓用戶空間的組件來計算相應調用的代碼覆蓋率。

03 實驗評估
本節介紹下筆者測試LynxFuzzer效率的的實驗。筆者測試了17個同的內核擴展。找到了6個bug。其中2個已經在OS X 10.9中得到了修復。已經被蘋果公司定義為CVE-2013-5166和CVE-2013-5192。剩下的4個還沒有被修復。也許會在以后版本中修 復。
所有的的實驗都是在安裝來Mac OS X 10.8.2系統的蘋果電腦(Intel i5 CPU 12G RAM)上進行的。由于蘋果內核的安全機制。筆者找到的漏洞沒有一個可以簡單溢出進行提權的攻擊的。
評價fuzzer效率的的其中一個指標就是代碼覆蓋率水平。這個指標也許不是那么的絕對:一個fuzzer也許代碼覆蓋率達到100%也獲取不了一個bug。但是通常都會報告這一指標,所以筆者統計了LynxFuzzer的代碼覆蓋率。
雖然筆者的調試器可以輕松的追蹤每一條指令。但是給出一個精確的覆蓋率還是相當不容易的。筆者通過靜態動態混合分析技術來估算出可以有分派表達到的 代碼總量。首先,筆者靜態的計算導出方法的指令數。塞選出所有控制轉移指令CTI(control transfer instrction)。然后,對于每個CTI,如果跳轉目標是同一個kext的另一個方法,筆者就將其統計到總數中。
不幸的是這還是有不足之處。由于內核的面相對象特性,kext包含很多間接CTI,無法靜態跟蹤。對于這類指令,筆者采用動態分析:筆者改進了 LynxFuzzer代碼覆蓋率分析模型,讓它dump每一條kext中每一條CTI指令的目標。如果目標在靜態分析中沒有被檢測到,筆者還是將這個指令 計算到總數中。
表1顯示了一部分代碼覆蓋率的實驗結果。在覆蓋率欄筆者顯示了3種不同的覆蓋率百分比:導出方法的指令數,混合分析的指令數,kext中指令總數。
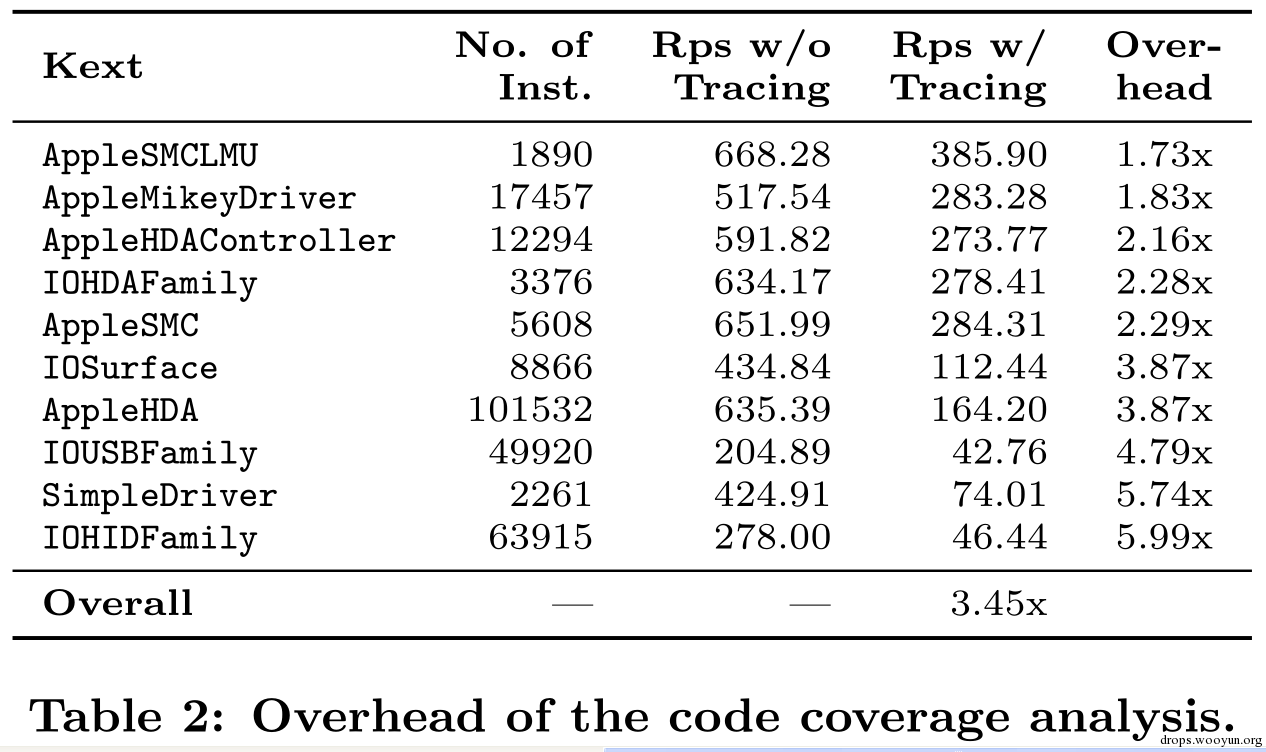
筆者還估算了在3.3中描述的代碼覆蓋率方法的開銷。為此,筆者在10個不同kext上運行隨機引擎fuzz每個方法。將代碼覆蓋率統計模塊分別開 啟和關閉,統計kext每秒可以處理的請求數。出于精確性,筆者在每個模塊上進行了10次重復。結果取平均值。平均開銷是3.45x,最優和最差分別是 1.73x和5.99x。表2給出了細節。筆者可以看到,筆者為獲取高精度,在沒有優化目標時付出了較大的代價,但是相對其他技術來說也算是很低了。
最后,評估了引擎的效率,特別指出,通過不同配置的筆者的引擎都能用于發現bug,但是基于代碼覆蓋率的進化引擎是最快的,隨機引擎最慢。