

新網絡安全軍備競賽場:對抗樣本防護
責編:gltian |2019-03-04 11:20:23在《對抗樣本對人工智能應用的威脅》一文中,我們主要對當前人工智能技術中的對抗樣本現象進行了實驗和簡單原理分析。而為了使人工智能系統在對抗樣本下更具魯棒性(Robust),研究人員對對抗樣本的防護同樣展開了廣泛研究。

對抗樣本防護技術,一般可分為主動防護方式和被動防護方式。主動防護方式是指通過技術加固,把神經網絡本身的對抗樣本防護能力進行提升;而被動防護方式則是獨立于神經網絡,通常置于神經網絡輸入之前,起到針對對抗樣本的防護作用。
關于對抗樣本的主動防護方式,目前前沿的研究方向又可以分為網絡蒸餾、對抗訓練、分類器魯棒化等。
網絡蒸餾:
如圖1所示,網絡蒸餾技術原本被用于降低神經網絡的復雜度,Papernot等人在其論文《Distillationas a defense to adversarial perturbations against deep neural networks》中將該技術用于對抗樣本的防護。具體做法是將第一個深度神經網絡輸出的分類可能性結果輸入到第二個網絡中進行訓練。通過這種方式,網絡蒸餾可以從原有神經網絡中提取知識來增進網絡的魯棒性。通過這種技術處理,降低了模型對小擾動的敏感度從而提升了對對抗樣本的抵抗能力。該技術在MNIST 和CIFAR-10分別進行了試驗,達到了對于對抗樣本的防護效果。
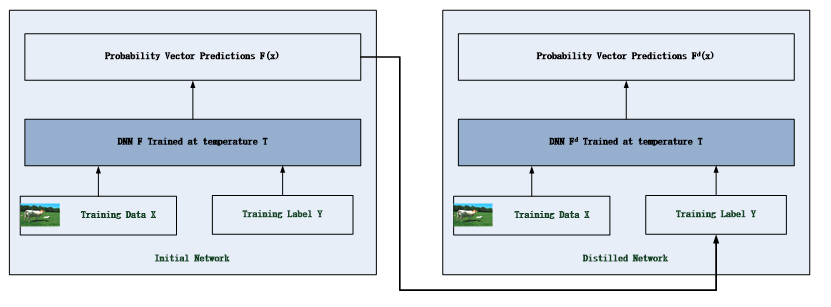
圖1
對抗訓練:
使用對抗樣本進行訓練也是一種主動防護方式,主要原理是將對抗樣本同樣作為訓練數據對神經網絡進行訓練。
Goodfellow在其論文《Explaining and harnessingadversarial example》、Ruitong Huang在其論文《Learning witha strong adversary》里在模型的訓練過程中同時生成對抗樣本,然后將生成的對抗樣本添加到訓練集中,以此方式進行對抗訓練,在MNIST數據集上實現了防護。Kurakin和Goodfellow在其論文《Adversarial machinelearning at scale》中使用一半的原始訓練集圖片和一半的對抗樣本進行訓練,在ImageNet數據集上體現了良好的防護效果。Tramèr等人在其論文《Ensemble adversarial training: Attacks and defenses》中將來自使用不同訓練方法得到的訓練樣本作為輸入,來對抗黑盒對抗樣本攻擊的可遷移性。
分類器魯棒化:
該技術的主要依據為,對抗樣本基本作用方式是使得分類器對微小擾動的判斷結果不確定性增強。
Bradshaw在其論文《Adversarialexamples, uncertainty, and transfer testing robustness in gaussianprocess hybrid deep networks》中構建了基于徑向基核函數的高斯過程來應對對抗樣本的不確定性。Abbasi在其論文《Robustness to adversarial examples throughan ensemble of specialists》中認為對抗樣本通常將神經網絡的分類結果引導為一個類別子集中去,將分類結果分為若干子類集合,然后通過投票的方式去得到最終的結果,通過這種方式來抵御不確定性的發生。
關于對抗樣本的被動防護方式,當前前沿的研究方向又可以主要分為對抗樣本檢測、輸入重構、網絡驗證等。
對抗樣本檢測:
該類型的做法是通過串聯一個檢測器在神經網絡來檢測輸入的合法性。其通常做法是通過尋找對抗樣本和正常樣本的區別點來建立一個二元分類器,分類器輸出結果為該樣本是否是對抗樣本。
Tianyu Pang等人在論文《Towards robust detection of adversarial examples》中使用反向交叉熵訓練了一個神經網絡來區分對抗樣本和正常樣本。Weilin Xu等人在其論文《Feature Squeezing:Detecting Adversarial Examples in Deep Neural Networks》中發現對抗樣本數據輸入神經網絡得到的結果和經過“Feature Squeezing”后的對抗樣本數據再輸入神經網絡的結果通常偏差大于正常樣本經過相同處理后的偏差。利用上述性質,可以在訓練階段在正常數據的訓練數據集中得到正常樣本的閾值,然后在測試階段使用該閾值判斷一個數據是否為對抗樣本,如圖2 所示。

圖2
輸入重構:
輸入重構是將惡意的對抗樣本數據轉化為非惡意數據,即經過轉化后的數據將無法再對模型的分類結果產生誤導。
Yang Song在其論文《Pixeldefend: Leveraging generative models to understand and defend againstadversarial examples》中提出了Pixeldefend方法。該方法使用PixelCN網絡將對抗樣本圖片重構為符合訓練圖片的分布狀態。清華大學廖方舟使用神經網絡的方法來對對抗樣本進行降噪處理,具體做法為將損失函數直接加在網絡高層的特征層上,從而在輸出的結果上防止分類誤差的放大,并使用該方法取得了NIPS 2017對抗樣本攻防賽冠軍。
網絡驗證
網絡驗證(Network verification)是通過確定目標神經網絡的性質,然后判斷輸入符合或者違反網絡的性質。由于該類方法對目前尚未出現的對抗樣本攻擊方式也有潛在的檢測效果,因此網絡驗證是一種受關注的防御方式。
Katz在其論文《Reluplex:An efficient smt solver for verifying deep neural networks》中提出了使用可滿足性模理論并利用ReLU激活函數來驗證神經網絡的方法來防護對抗樣本。但是該方法效率較慢,通常用于檢測擁有幾百個節點的神經網絡。在Katz的另一篇論文中提出,可以通過排出節點優先級和使用驗證知識共享的方式來提升檢測效率。
自此,我們對幾類防護技術進行了分類梳理。上述防護技術分別在各自的數據集和神經網絡模型下進行了實驗,取得了不錯的防護成功率。
為了從根本上解決對抗樣本問題,也有越來越多的研究者正試圖從對抗樣本的內在成因之中找到答案。對于成因的解釋主要有模型魯棒邊界、樣本復雜度、計算復雜度三個方向。
1. 魯棒性邊界方向
Fawzi在其論文《Adversarial Vulnerability for any Classifier》中從分類器的魯棒性方向進行了分析,在論文中提出了擾動條件下任意分類器所能達到的基本上界,即在給定數據集的情況下任意分類器所能達到的最高魯棒性是存在最大值的。其指出當數據潛在空間在高緯空間時,任意分類器均面臨對抗樣本風險。并且發現了魯棒性和分類器在潛在空間中線性度的緊密相關性。該論文還給出了在不同分類器同時起作用的對抗樣本的數據分布區間,于是解釋了有些對抗樣本的可遷移性。
2. 樣本復雜度方向
Ludwig Schmidt在其論文《Adversarially Robust Generalization Requires More Data》中提出訓練一個可抵御對抗樣本的模型所需的數據樣本顯著地高于標準的數據樣本集合。這個集合體量的間隙是基于信息論的,而與訓練算法和模型的種類無關。并且提出可以確定一個下限來給出一個在確定擾動強度下所需要的最低數據樣本復雜度。作者認為該數據樣本復雜度下限的存在意味著對抗樣本的存在并不是某一個分類模型的缺陷。
3. 計算復雜度方向
Sebastien Bubeck在其論文《Adversarial examples from computational constraints》中提出對抗樣本的出現不是由于信息論下模型或者數據集的局限,而是由于計算復雜度上的局限造成。為了證明他的觀點,作者首先闡明,存在基于較小的訓練樣本集進行對抗樣本魯棒學習的方式。然后通過實驗證明即便針對一個簡單的網絡模型,在進行為了抵御對抗樣本而進行的學習時,計算復雜度也是在Kearns SQ(統計查詢模型)下難以計算的。
這三種解釋方向目前雖尚無定論,卻都展現了當前技術發展狀態下可抵御對抗樣本的“robust learning”的訓練難度要遠遠大于標準的訓練難度,甚至在當前技術條件下尚無法“完全”達到。
在本文中,我們把對抗樣本防護相關的前沿研究成果進行了梳理。通過分析我們可以得出以下結論:
對于人工智能對抗樣本問題的防護目前還沒有找到可以使我們一勞永逸的“銀彈”。也正因為如此我們判斷,和傳統互聯網、移動互聯網以至物聯網安全一樣,人工智能對抗樣本領域將同樣存在著新型的攻防軍備競賽。而其競爭的焦點將集中在訓練模型、計算能力、樣本量的積累等方面。
所以,作為第一個提出認知安全概念的網絡安全廠家,我們建立了高性能的實驗平臺,對前沿的對抗樣本生成和防護的訓練模型進行了一一實驗和分析,積累了大量的對抗樣本數據并使用GAN等方式擴展訓練數據空間。在相關領域我們從沒有停止前進的腳步,希望用我們的努力換來一個更安全可靠的智能世界。