

DEFCON CHINA議題解讀 | 對深度學(xué)習(xí)系統(tǒng)的數(shù)據(jù)流攻擊
責(zé)編:gltian |2018-05-14 09:51:35本次的DEFCON China上,360智能安全團(tuán)隊(duì)負(fù)責(zé)人李康博士分享了一個關(guān)于深度學(xué)習(xí)系統(tǒng)數(shù)據(jù)流攻擊的議題——“Beyond Adversarial Learning-Data Scaling Attacks in Deep Learning Applications”,展示了如何讓人工智能人臉識別系統(tǒng)將李冰冰的照片誤認(rèn)為趙本山的攻擊形式。

李康博士的研究團(tuán)隊(duì)所發(fā)現(xiàn)的數(shù)據(jù)流攻擊是通過對輸入數(shù)據(jù)的維度特性進(jìn)行改變,可以針對深度學(xué)習(xí)的數(shù)據(jù)處理環(huán)節(jié)進(jìn)行攻擊,對深度學(xué)習(xí)圖像識別等應(yīng)用造成逃逸攻擊以及數(shù)據(jù)污染攻擊等效果。相比于現(xiàn)有的深度學(xué)習(xí)系統(tǒng)對抗樣本生成方法,該攻擊方式不依賴于具體的深度學(xué)習(xí)模型,并在對Caffe、Tensorflow等當(dāng)前主流深度學(xué)習(xí)框架有效。
一、背景——深度學(xué)習(xí)系統(tǒng)中的數(shù)據(jù)預(yù)處理
1.1為什么需要數(shù)據(jù)預(yù)處理?
一般而言,深度學(xué)習(xí)系統(tǒng)主要包括數(shù)據(jù)采集、數(shù)據(jù)預(yù)處理、深度學(xué)習(xí)模型以及決策執(zhí)行四個環(huán)節(jié),其中數(shù)據(jù)預(yù)處理的作用是依據(jù)模型輸入要求將采集到的原始數(shù)據(jù)進(jìn)行格式、大小等屬性的調(diào)整。接下來就以基于深度學(xué)習(xí)在圖像識別的應(yīng)用為例進(jìn)行說明。
目前多數(shù)圖像識別系統(tǒng)都是基于預(yù)先訓(xùn)練好的網(wǎng)絡(luò)模型,這就帶來一個很大的限制——輸入層大小固定。在NVIDIA提供的多個無人駕駛模型中,模型的輸入圖片尺寸都被要求為226*66。而NVIDIA提供的推薦攝像頭尺寸范圍是320*240至1928*1208等多種圖片大小,但是200*66并不屬于此范圍內(nèi),這就要求在使用模型時(shí)必須將原始圖片統(tǒng)一縮放至200*66的標(biāo)準(zhǔn)尺寸。此外經(jīng)調(diào)研發(fā)現(xiàn),不同的深度學(xué)習(xí)視覺應(yīng)用模型所要求的輸入尺寸多種多樣,這使得圖片縮放這一數(shù)據(jù)預(yù)處理環(huán)節(jié)在實(shí)際應(yīng)用中不可或缺。
2.2數(shù)據(jù)預(yù)處理做了什么?
如前所言,計(jì)算機(jī)視覺領(lǐng)域的數(shù)據(jù)預(yù)處理主要指Scaling/Resizing操作,即對圖像尺寸進(jìn)行調(diào)整的過程。該過程主要由插值算法實(shí)現(xiàn),主要包括最近鄰插值、雙線性插值、三次插值等。下圖簡單展示了用最近鄰插值將4*4大小圖片壓縮到2*2大小的過程,其它的算法會有相對復(fù)雜的公式。
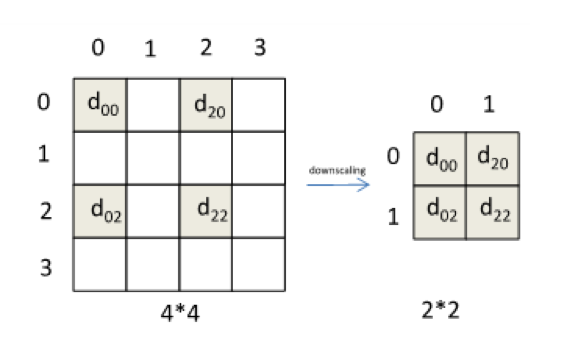
可以看到,壓縮的過程中伴隨著有效信息的丟失。不幸的是,在許多深度學(xué)習(xí)框架所采用的數(shù)據(jù)預(yù)處理環(huán)節(jié),并沒有考慮到這些信息丟失可能會帶來的安全威脅。接下來李康博士將展示他們?nèi)绾卫眠@些被丟棄掉的有效信息,來對如下的深度學(xué)習(xí)系統(tǒng)進(jìn)行數(shù)據(jù)流攻擊。

二、數(shù)據(jù)流維度攻擊
數(shù)據(jù)流維度攻擊,顧名思義,是指對數(shù)據(jù)尺度變換的過程開展的攻擊。在本例中,通過對輸入圖片插入惡意偽造信息,在深度學(xué)習(xí)系統(tǒng)對圖片進(jìn)行縮放后使其對于模型的輸入發(fā)生變化,造成人與機(jī)器對于同一輸入圖片的“認(rèn)知代溝”。
2.1 攻擊原理
以下為針對圖像識別系統(tǒng)的自動化數(shù)據(jù)流維度攻擊的原理圖。
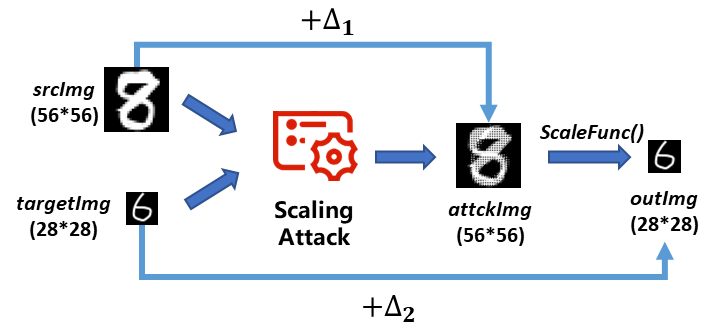
在此給出自動化攻擊的模型。假設(shè)攻擊者給定一張m*n大小的原始圖片srcImg(Sm*n)和一張希望機(jī)器預(yù)處理之后得到的m’*n’大小的目標(biāo)圖片targetImg(Tm’*n’)。最終經(jīng)過自動化Scaling Attack后,在Sm*n上引入變化量△1,生成攻擊樣本attackImg(Am*n),經(jīng)過機(jī)器預(yù)處理后輸出圖片為outImg(Dm’*n’),其與目標(biāo)圖片的差異度為△2。
理想的攻擊效果是人類無法區(qū)分原始圖片以及偽造樣本,而機(jī)器無法區(qū)分目標(biāo)圖片以及偽造樣本的輸出圖片。因此我們希望變化△1和△2能夠盡可能小。由此可以得出指導(dǎo)我們進(jìn)行自動化攻擊的數(shù)學(xué)模型。
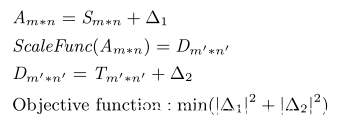
通過對該二次優(yōu)化問題進(jìn)行求解,最終可以實(shí)現(xiàn)自動化的Scaling attack。
2.2 攻擊效果展示
該團(tuán)隊(duì)對主流深度模型的圖像變換算法進(jìn)行了調(diào)研,據(jù)此對選取典型的圖像預(yù)處理函數(shù)進(jìn)行了攻擊,并在此展示部分攻擊效果。
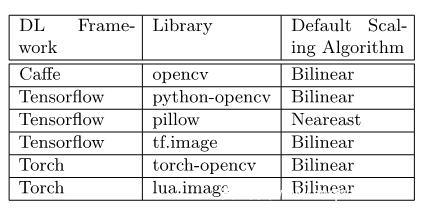
1.對MNIST手寫識別數(shù)據(jù)集的攻擊
攻擊輸入:
![]()
預(yù)處理輸出:
![]()
攻擊輸入:
 預(yù)處理輸出:
預(yù)處理輸出:
![]()
2.對人像的掩蓋攻擊
攻擊輸入:

預(yù)處理輸出:

攻擊輸入:

預(yù)處理輸出:

三、防御手段
針對上述攻擊,李康博士向大家介紹了幾種可行的防御措施。
1.過濾并丟舍棄與深度學(xué)習(xí)模型輸入大小不匹配的樣本。
該手段可以從根本上消除維度攻擊帶來的危害,但僅僅適用于數(shù)據(jù)傳感器可以受用戶控制和調(diào)整的情況,等多的時(shí)候該方法無異于“傷敵一千,自損八百”。限定輸入數(shù)據(jù)大小會極大降低深度學(xué)習(xí)系統(tǒng)的通用性,破壞深度學(xué)習(xí)系統(tǒng)在不同硬件平臺上的可移植性。
2.使用更加健壯的數(shù)據(jù)變換算法
在數(shù)據(jù)預(yù)處理環(huán)節(jié)開發(fā)者應(yīng)該選用表現(xiàn)更加穩(wěn)定的數(shù)據(jù)變化算法,如雙三次方插值。這類插值算法在進(jìn)行數(shù)據(jù)縮放時(shí)會引入更多的樣本點(diǎn)之間的相關(guān)性信息,這會增加攻擊模型求解的難度和最終的求解效果。此外,開發(fā)人員還可以考慮對于數(shù)據(jù)變化因子引入隨機(jī)化方法,不確定的數(shù)據(jù)變換方式會導(dǎo)致攻擊者針對的數(shù)據(jù)變換算法與實(shí)際處理算法的差異,從而對抗相應(yīng)的攻擊。
3.對預(yù)處理前后的數(shù)據(jù)變化進(jìn)行檢測。
第三類方法是對數(shù)據(jù)預(yù)處理產(chǎn)生的結(jié)果與原始輸入進(jìn)行相似度比對。通過對數(shù)據(jù)分布、樣本點(diǎn)相關(guān)性等特征進(jìn)行比對,可以檢測數(shù)據(jù)預(yù)處理前后信息的變化情況,從而對數(shù)據(jù)預(yù)處理環(huán)節(jié)進(jìn)行可靠性評估。
四、小結(jié)
數(shù)據(jù)流維度攻擊是對深度學(xué)習(xí)應(yīng)用一種新型攻擊方法,主要影響對任意圖片進(jìn)行識別的深度學(xué)習(xí)應(yīng)用程序。 李康團(tuán)隊(duì)的工作旨在提醒公眾和研究人員,在擁抱人工智能熱潮的同時(shí),需要持續(xù)關(guān)注深度學(xué)習(xí)系統(tǒng)中的安全問題。
原文:https://www.anquanke.com/post/id/144837
- ISC.AI 2025正式啟動:AI與安全協(xié)同進(jìn)化,開啟數(shù)智未來
- 360安全云聯(lián)運(yùn)商座談會圓滿落幕 數(shù)十家企業(yè)獲“聯(lián)營聯(lián)運(yùn)”認(rèn)證!
- 280萬人健康數(shù)據(jù)被盜,兩家大型醫(yī)療集團(tuán)賠償超4700萬元
- 推動數(shù)據(jù)要素安全流通的機(jī)制與技術(shù)
- RSAC 2025前瞻:Agentic AI將成為行業(yè)新風(fēng)向
- 因被黑致使個人信息泄露,企業(yè)賠償員工超5000萬元
- UTG-Q-017:“短平快”體系下的高級竊密組織
- 算力并網(wǎng)可信交易技術(shù)與應(yīng)用白皮書
- 美國美中委員會發(fā)布DeepSeek調(diào)查報(bào)告
- 2024年中國網(wǎng)絡(luò)與信息法治建設(shè)回顧