

微軟安全大模型的應(yīng)用架構(gòu)
責(zé)編:gltian |2024-10-12 16:05:16微軟有最全的安全產(chǎn)品,以云上為主,也就有了最好的數(shù)據(jù)。他們用了OpenAI的模型,最好的,團(tuán)隊(duì),也基本沒有哪個(gè)公司可比。
所以微軟做了Security Copilot非常炫酷,上一篇已經(jīng)介紹過了,可以參考
那么,微軟是如何使用大模型的?本文作一分析。
本文共分四部分
一、大模型基本能力
二、大模型的缺陷
三、微軟的應(yīng)用架構(gòu)
四、總結(jié)
01 大模型的基本能力
我們最常使用大模型的方法,是對(duì)話。另外,還有一種方法,是API調(diào)用,用于基于大模型的軟件開發(fā)。
無論是對(duì)話,還是API調(diào)用,大模型的運(yùn)作是一樣的,就是根據(jù)一個(gè)請(qǐng)求,作出相關(guān)的響應(yīng),就這一個(gè)主要功能。其實(shí)這也是大模型的基本能力。
在API調(diào)用上,對(duì)這個(gè)功能再細(xì)化,有兩個(gè)能力需要重點(diǎn)強(qiáng)調(diào):
- 函數(shù)調(diào)用(Function Calling)
Function Calling(函數(shù)調(diào)用)是大模型與外部系統(tǒng)或API交互的能力。簡單地理解,你有一些函數(shù),用于處理問題。以前的做法,是在代碼里寫死,流程走到哪,調(diào)用哪個(gè)函數(shù),使用什么參數(shù)。
用大模型不一樣了,你可以把函數(shù)描述和要求給到大模型作為請(qǐng)求,大模型會(huì)根據(jù)你的要求,找到合適的函數(shù),并填上適當(dāng)?shù)膮?shù)給你。
函數(shù)可以是多個(gè),大模型會(huì)根據(jù)對(duì)話內(nèi)容,自動(dòng)選擇合適的函數(shù)及參數(shù)。
2.Sql生成
Sql生成和函數(shù)調(diào)用類似。以前需要自己寫Sql,現(xiàn)在不用了,你把數(shù)據(jù)庫的描述和查詢需求給它,述數(shù)據(jù)庫結(jié)構(gòu)和查詢需求同時(shí)給到大模型,它可以生成一個(gè)Sql語句,這個(gè)功能實(shí)際有很多用法,不過深討論。
02 大模型的缺陷
大模型的函數(shù)調(diào)用能力,用于對(duì)外部工具的調(diào)用,是個(gè)非常有價(jià)值的工具。畢竟,相對(duì)原來根據(jù)需求,一行一行寫代碼調(diào)用,現(xiàn)在只要說一句話,它就能調(diào)用哪個(gè)工具,并準(zhǔn)確輸入?yún)?shù),這對(duì)軟件是個(gè)巨大的進(jìn)步。
但它有個(gè)致命的缺陷:大模型并沒有臨時(shí)記憶,就是每次請(qǐng)求,都需要完整地輸入所有的函數(shù)描述。你沒看錯(cuò),是每一次。你跟大模型聊天,看上去大模型記住了你前邊說過的話,實(shí)際上,是瀏覽器每一次都把前邊所有的對(duì)話也發(fā)給了大模型,每一次調(diào)用,都要帶上所有歷史記錄,而大模型本身并沒有會(huì)話的概念,它什么都記不住。
這是個(gè)令人崩潰的事情,一來每次調(diào)用都是巨大的tokens消耗,費(fèi)用巨大,性能非常差。二是針對(duì)大的系統(tǒng),函數(shù)的描述是海量的,而大模型的輸入又有長度限制,很可能prompt放不下。
針對(duì)這個(gè)問題,openai最初給的方案是微調(diào)。微調(diào)就是給出一系列指令,比如說A需求,調(diào)用FA函數(shù),B需求,調(diào)用FB函數(shù)。這個(gè)方案顯然降低了大模型的智能,比傳統(tǒng)寫代碼確實(shí)強(qiáng)點(diǎn),但大模型的智能顯然是沒用好。
最近,OpenAI和Claude又有了一個(gè)相對(duì)優(yōu)化的解決方案,是Prompt caching.
Prompt caching是一種優(yōu)化大型語言模型(LLMs)性能和效率的技術(shù)。這個(gè)概念相對(duì)較新,主要應(yīng)用于需要頻繁使用LLMs的場景。以下是對(duì)prompt caching的詳細(xì)介紹:
概念定義:Prompt caching是指將常用的prompt及其對(duì)應(yīng)的模型輸出存儲(chǔ)起來,以便在后續(xù)相同或相似的查詢中快速檢索和重用。
這個(gè)方案,減少了延遲,降低了成本,但仍然不算最終的理想方案。
這個(gè)問題,繞不過。看看微軟是怎么解決的。
03 微軟的應(yīng)用架構(gòu)
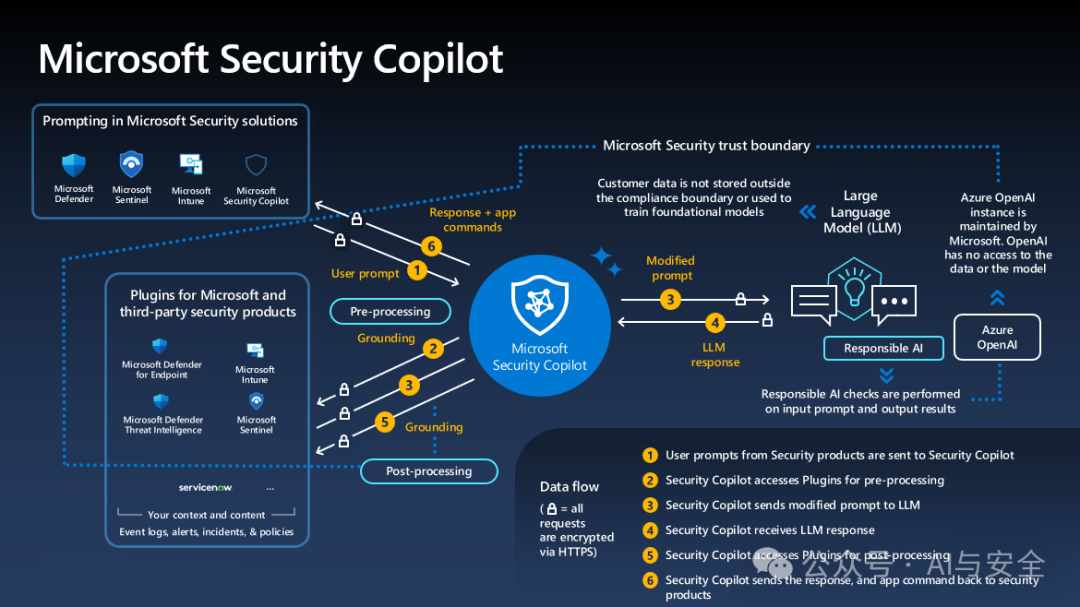
圖一
上圖是微軟的應(yīng)用架構(gòu),重點(diǎn)看copilot周邊的六條數(shù)據(jù)流,黃色數(shù)字標(biāo)識(shí)的部分。
- 用戶輸入提示
- Copilot根據(jù)用戶提供,找到合適的插件(plugin,連接目標(biāo)系統(tǒng),取數(shù)據(jù),函數(shù)表)
- Copilot根據(jù)插件取到的信息,重新修改prompt(增加信息),送給大模型
- 大模型根據(jù)要求,針對(duì)Copilot的請(qǐng)示返回結(jié)果
- Copilot把大模型的返回轉(zhuǎn)給插件,作后處理,比如進(jìn)一步的數(shù)據(jù)處理,函數(shù)調(diào)用要求等
- Copilot 將插件處理的結(jié)果,返回給應(yīng)用,包括響應(yīng),應(yīng)用命令等,由具體的安全進(jìn)行處理,再將結(jié)果返回給用戶。
這里邊,比較關(guān)鍵的點(diǎn)有兩個(gè),一個(gè)是插件(plugin),一個(gè)是Copilot的插件選擇(路由能力)
1.插件(plugin)的原理
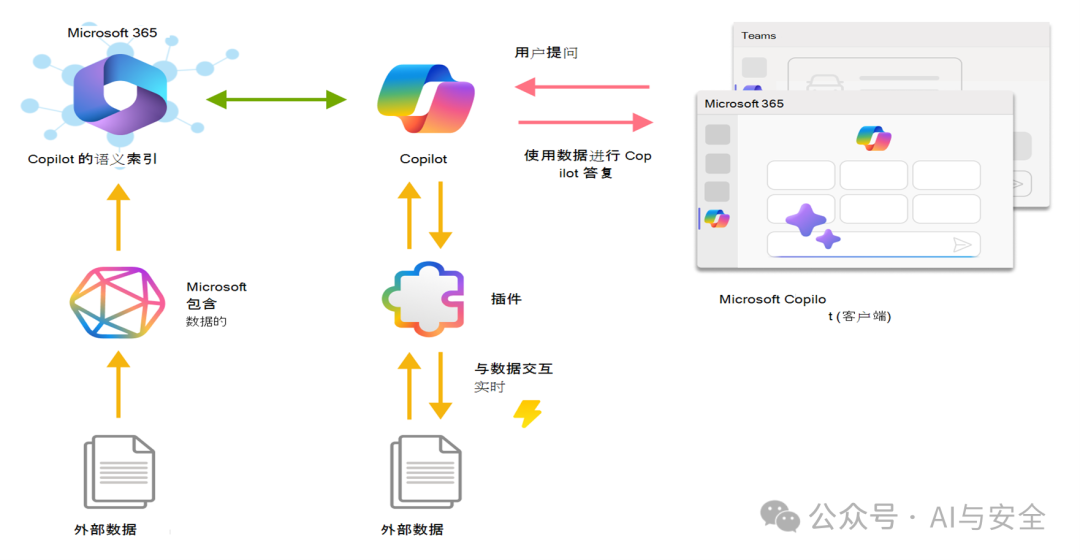
它通過標(biāo)準(zhǔn)接口與copilot對(duì)接,可與外部數(shù)據(jù)進(jìn)行交互。按,每個(gè)安全產(chǎn)品對(duì)應(yīng)一個(gè)插件,可以獲取相關(guān)數(shù)據(jù)。
2.路由
如何根據(jù)用戶的請(qǐng)求(自然語言)找到合適的插件?微軟沒有明確說明。但這個(gè)功能,如果用大語言模型實(shí)現(xiàn)是非常容易的。兩個(gè)方法都可以,一是在進(jìn)行步驟3之前先調(diào)用一下大模型(這與圖示不符),還有一個(gè)辦法是在Copilot里再放一個(gè)小一點(diǎn)的模型。微軟用了openai的模型,但也反復(fù)強(qiáng)調(diào)自身的模型訓(xùn)練,我認(rèn)為后一種可能性更大。這個(gè)方法一般稱為意圖識(shí)別。當(dāng)然,看花容易養(yǎng)花難,理論上好實(shí)現(xiàn),和實(shí)際上實(shí)現(xiàn)好,還是有很大的差距。
CrowdStrike的Charlotte AI也非常強(qiáng)調(diào)路由能力,說的也是這個(gè)意思。
04 總結(jié)
大模型在近兩年的發(fā)展中,表現(xiàn)出無比巨大的能力,但僅有大模型是不夠的,結(jié)合大模型,做必要的外圍開發(fā),形成Agent,具備理解用戶,挖掘分析數(shù)據(jù),外部環(huán)境感知和工具調(diào)用能力,才是應(yīng)用的完整方案。客戶需要的不僅僅是通識(shí)問答,而是結(jié)合客戶自身情況的完整答案,這個(gè)關(guān)鍵在于數(shù)據(jù)獲取能力。
微軟的Security Copilot就是個(gè)非常完整的Agent方案。
如果再具體一點(diǎn),它就是個(gè)RAG(檢索增強(qiáng)生成)方案。目前的方案已經(jīng)表現(xiàn)的很好,相信隨著大模型技術(shù)的發(fā)展,agent能力更多的由大模型承載,未來會(huì)有更強(qiáng)的能力。
聲明:本文來自AI與安全,稿件和圖片版權(quán)均歸原作者所有。所涉觀點(diǎn)不代表東方安全立場,轉(zhuǎn)載目的在于傳遞更多信息。如有侵權(quán),請(qǐng)聯(lián)系rhliu@skdlabs.com,我們將及時(shí)按原作者或權(quán)利人的意愿予以更正。
- ISC.AI 2025正式啟動(dòng):AI與安全協(xié)同進(jìn)化,開啟數(shù)智未來
- 360安全云聯(lián)運(yùn)商座談會(huì)圓滿落幕 數(shù)十家企業(yè)獲“聯(lián)營聯(lián)運(yùn)”認(rèn)證!
- 280萬人健康數(shù)據(jù)被盜,兩家大型醫(yī)療集團(tuán)賠償超4700萬元
- 推動(dòng)數(shù)據(jù)要素安全流通的機(jī)制與技術(shù)
- RSAC 2025前瞻:Agentic AI將成為行業(yè)新風(fēng)向
- 因被黑致使個(gè)人信息泄露,企業(yè)賠償員工超5000萬元
- UTG-Q-017:“短平快”體系下的高級(jí)竊密組織
- 算力并網(wǎng)可信交易技術(shù)與應(yīng)用白皮書
- 美國美中委員會(huì)發(fā)布DeepSeek調(diào)查報(bào)告
- 2024年中國網(wǎng)絡(luò)與信息法治建設(shè)回顧