

實(shí)測(cè):頂級(jí)AI模型未達(dá)到歐盟AI法案標(biāo)準(zhǔn)
責(zé)編:gltian |2024-10-17 16:26:59瑞士初創(chuàng)公司LatticeFlow開(kāi)發(fā)了名為“COMPL-AI”的大型語(yǔ)言模型測(cè)試工具(LLM Checker),旨在測(cè)試AI模型是否能滿足歐盟人工智能法案的合規(guī)性要求,該工具受到歐盟官員的廣泛歡迎。測(cè)試結(jié)果顯示,一些頂級(jí)科技公司的人工智能模型在網(wǎng)絡(luò)安全和防止歧視性輸出等關(guān)鍵領(lǐng)域未能達(dá)到要求。
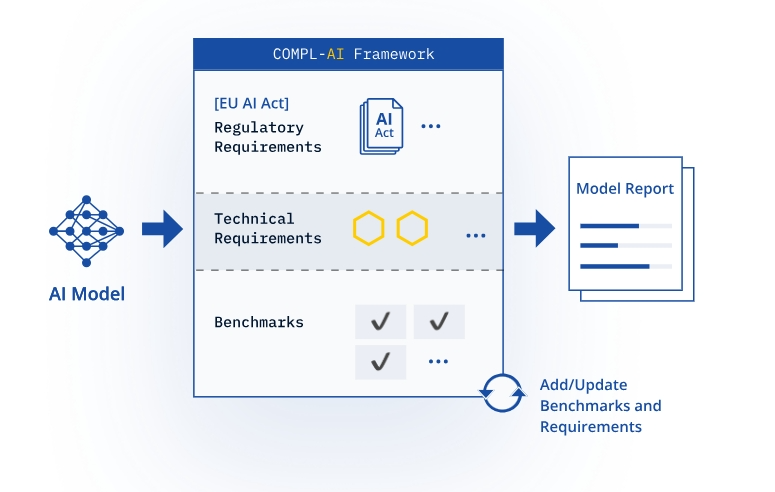
一、測(cè)試結(jié)果
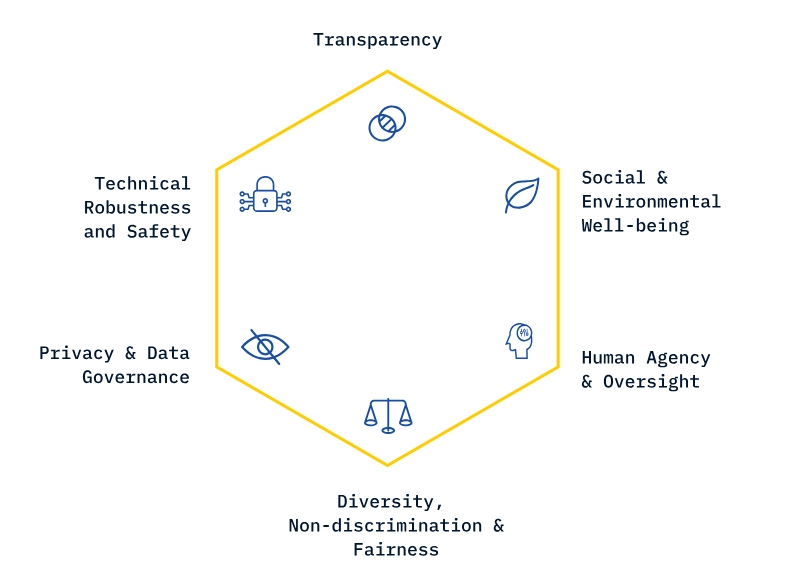
該工具由LatticeFlow與蘇黎世聯(lián)邦理工學(xué)院和保加利亞計(jì)算機(jī)科學(xué)、人工智能和技術(shù)研究所合作設(shè)計(jì),從技術(shù)穩(wěn)健性和安全性,隱私和數(shù)據(jù)治理,透明度,多元化、非歧視和公平,社會(huì)與環(huán)境福祉,人類的主體性與監(jiān)督等方面測(cè)試了OpenAI、Meta、阿里巴巴等頂級(jí)科技公司的AI模型。
這些模型的測(cè)試分?jǐn)?shù)從0到1不等,大多數(shù)測(cè)試的模型平均得分為0.75或更高,例如Anthropic的“Claude 3 Opus”得分為0.89。但在測(cè)試中,一些模型也暴露了重大缺陷。
在測(cè)試歧視性輸出時(shí),OpenAI的“GPT-3.5 Turbo”獲得了0.46的低分,而阿里巴巴的“Qwen1.5 72B Chat”得分更低,為0.37,凸顯了人工智能在性別和種族等領(lǐng)域反映人類偏見(jiàn)的問(wèn)題。
在測(cè)試“提示劫持”時(shí)(一種黑客使用欺騙性提示來(lái)提取敏感信息的攻擊形式),Meta的Llama 2 13B Chat模型得分為0.42,而法國(guó)初創(chuàng)公司Mistral的8x7B Instruct模型得分為0.38。
二、未來(lái)展望
LLM Checker的開(kāi)發(fā)是為了與歐盟人工智能法案不斷變化的要求保持一致,隨著未來(lái)兩年執(zhí)法措施的出臺(tái),該工具預(yù)計(jì)將發(fā)揮更大的作用。LatticeFlow已免費(fèi)提供該工具,允許開(kāi)發(fā)人員在線測(cè)試其AI模型的合規(guī)性,讓他們了解滿足歐盟AI法案要求時(shí)面臨的挑戰(zhàn)。此外,法案的部分要求預(yù)計(jì)將于2025年全面實(shí)施,不遵守AI法案的公司將面臨3500萬(wàn)歐元(3800萬(wàn)美元)或其全球年?duì)I業(yè)額7%的罰款。
LatticeFlow公司的首席執(zhí)行官兼聯(lián)合創(chuàng)始人Petar Tsankov表示,測(cè)試結(jié)果總體上是積極的,能為各公司提供一個(gè)路線圖,供他們根據(jù)法案微調(diào)模型。
歐盟委員會(huì)也一直在密切關(guān)注該工具的發(fā)展,一位發(fā)言人表示,該工具代表了將歐盟人工智能法案轉(zhuǎn)化為技術(shù)合規(guī)要求的“第一步”,這表明更詳細(xì)的執(zhí)法措施正在計(jì)劃中。
聲明:本文來(lái)自上海市人工智能與社會(huì)發(fā)展研究會(huì),稿件和圖片版權(quán)均歸原作者所有。所涉觀點(diǎn)不代表東方安全立場(chǎng),轉(zhuǎn)載目的在于傳遞更多信息。如有侵權(quán),請(qǐng)聯(lián)系rhliu@skdlabs.com,我們將及時(shí)按原作者或權(quán)利人的意愿予以更正。
- ISC.AI 2025正式啟動(dòng):AI與安全協(xié)同進(jìn)化,開(kāi)啟數(shù)智未來(lái)
- 360安全云聯(lián)運(yùn)商座談會(huì)圓滿落幕 數(shù)十家企業(yè)獲“聯(lián)營(yíng)聯(lián)運(yùn)”認(rèn)證!
- 280萬(wàn)人健康數(shù)據(jù)被盜,兩家大型醫(yī)療集團(tuán)賠償超4700萬(wàn)元
- 推動(dòng)數(shù)據(jù)要素安全流通的機(jī)制與技術(shù)
- RSAC 2025前瞻:Agentic AI將成為行業(yè)新風(fēng)向
- 因被黑致使個(gè)人信息泄露,企業(yè)賠償員工超5000萬(wàn)元
- UTG-Q-017:“短平快”體系下的高級(jí)竊密組織
- 算力并網(wǎng)可信交易技術(shù)與應(yīng)用白皮書(shū)
- 美國(guó)美中委員會(huì)發(fā)布DeepSeek調(diào)查報(bào)告
- 2024年中國(guó)網(wǎng)絡(luò)與信息法治建設(shè)回顧