

全球網安巨頭5款產品如何應用大模型
責編:gltian |2025-04-14 16:50:46一、引言
隨著大模型的火爆,各安全廠家對大模型的跟進主要分為兩個方面,一方面是大模型安全方案,結合廠商自身的安全能力,提供大模型的安全防護方案,如Tenable做漏掃則主打ML資產發現與ML漏洞檢測;WIZ做CSPM則主打大模型云服務的SPM,取名為AI-SPM;Akamai做SASE則主打LLM應用的訪問可視化與數據泄露監測;另一方面,則是各個廠家自身的拳頭產品結合大模型,提供更低門檻的交互方式、更自動化的運營方式、更高效的安全閉環,我們今天就主要來看看全球網安巨頭們的產品中,如何應用大模型。

二、Cortex XSIAM&XPANSE
1.XSIAM Copilot
XSIAM是Paloalto在安全運營側的核心產品,大家可以理解成高級的安全運營管理平臺,不僅僅匯聚了告警、日志等關聯分析能力,還集成了XDR/XSOAR/XPANSE/NGFW等產品的能力,檢測、調查、響應一體化都在一個平臺上完成,也是PA的三大平臺戰略之一
XSIAM與大模型的融合體現在XSIAM Copilot,支持大模型與XSIAM的XQL語句結合(XQL語句是XSIAM平臺用來進行日志、告警等平臺信息提取的查詢語句),利用自然語言對話生成XQL,示例如下:
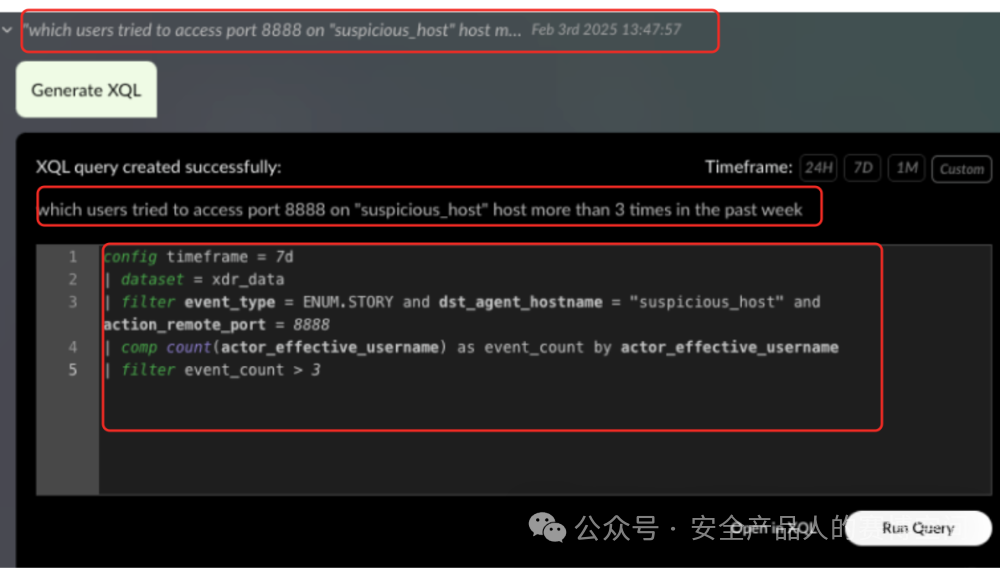
運行Query需要用戶二次點擊,才會運行并給出結果,應該是為了防止大模型構建不準導致的查詢出錯問題,讓用戶人工這里二次確認一下
也支持在對話框中對實體進行查詢調查,實體的概念包括主機,用戶,哈希,域,IP地址和事件等。可以對話框中直接輸入實體名稱,會展示該實體的摘要信息
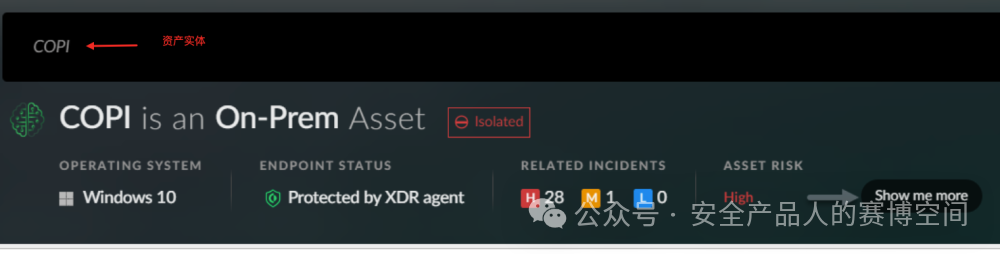
或詢問有關該實體的特定問題,例如“獲取xx實體更詳細的信息”
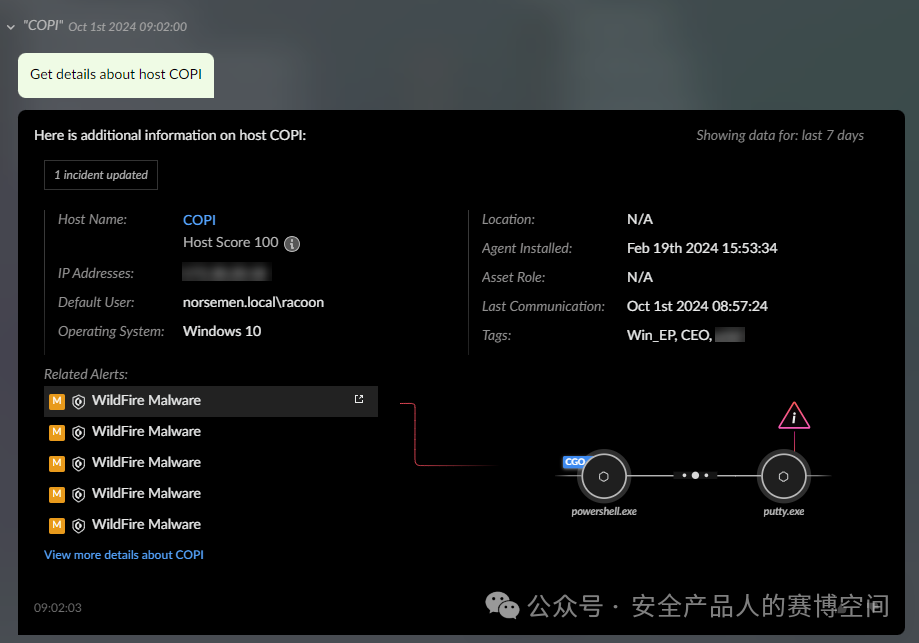
會以交互頁面形式給予返回,同時可點擊跳轉到產品內的頁面,進行詳情的查看。但是目前還僅支持針對XDR的數據源執行以上操作,不是針對每個數據源均可
2.XSIAM BYOM(Bring Your Own ML)
BYOM自定義模型這個能力比較有意思,XSIAM平臺上有對接的所有數據源的日志和告警數據,平臺將這些數據提供給用戶,供用戶訓練自己的機器學習模型
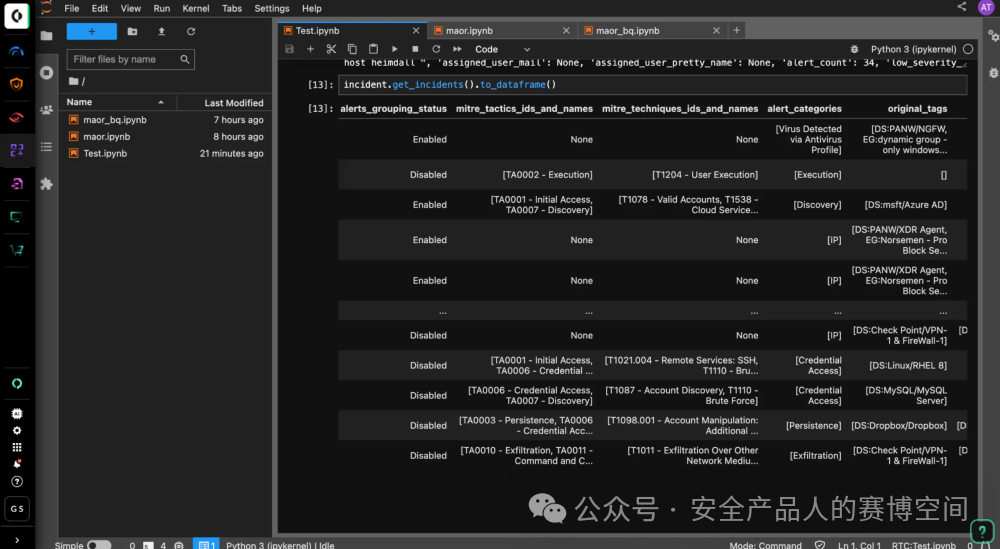
內嵌了開源 Jupyter Notebook 工具,使安全團隊能夠在 XSIAM 之上集成自己的自定義 ML 模型,并執行其環境獨有的數據來驗證模型效果
3.XPANSE Copilot
XPANSE是Cortex產線中的ASM攻擊面管理產品,與大模型的集成也是體現在Copilot上,進行對話調查,生成修復建議
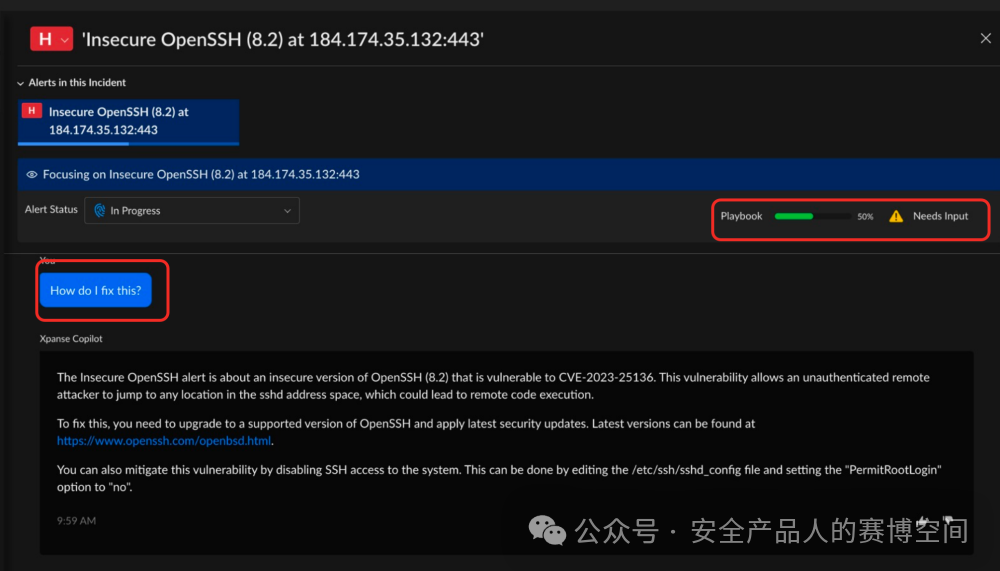
上圖中我們看到右上角有漏洞修復的Playbook(XSOAR能力)進行自動化的修復。但是查閱公開資料后發現,并沒有直接文檔或演示視頻證明Copilot在XPANSE中可以做到用指令調用Playbook進行自動修復,因此這里的自動修復,我們更傾向于XPANSE自帶的Palybook自動修復能力,針對某一類風險,采用某種Playbook,而不是大模型調用工作流去執行修復。也翻到了一些PA對外的PPT中對自動修復Palybook的介紹,僅在關聯資產與所有者/業務上下文中提到AI能力
至此我們總結Cortex產線中,大模型的應用集中體現在Copilot上,主要是對平臺已有告警、日志、風險的調取、總結、詢問建議等,應該說這是大模型嵌入產品的基本用法。那么Paloalto進一步做了的是,一方面在對話界面可以呈現交互式摘要或圖表,按鈕或鏈接可以跳轉到產品的某個具體功能頁面;另一方面提供平臺自身的數據集,通過Jupyter Notebook讓用戶可調試、編寫自己的ML模型。
三、Prisma Cloud
在云原生應用安全保護平臺,PA的大模型落地同樣是Copilot的形式,基礎的能力是支持詢問Prisma Cloud平臺相關的使用問題、產品能力問題等

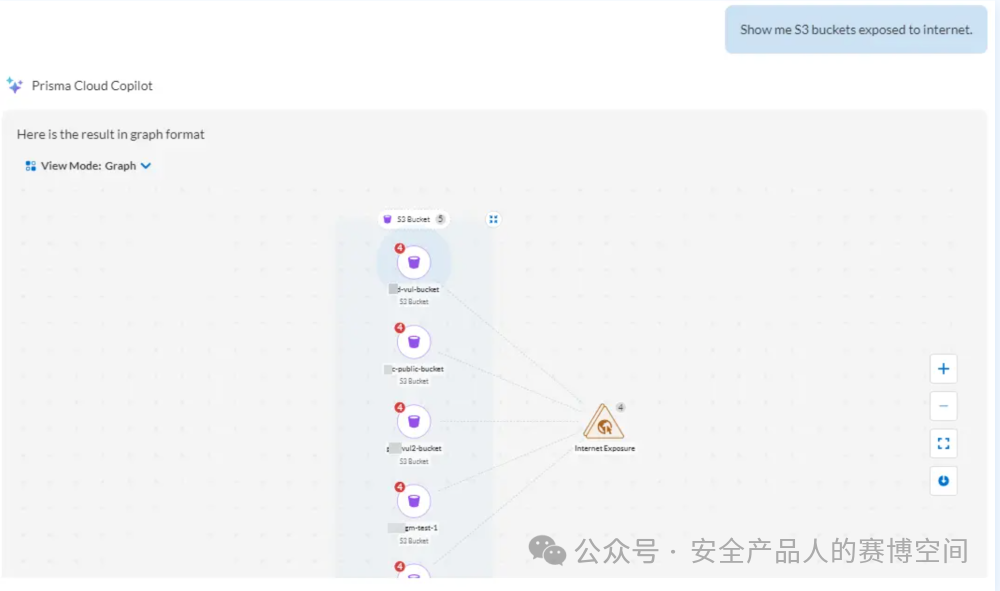
進一步的能力,支持對云風險、漏洞、資產的調查搜索,回答結果也可以呈現圖的形式或表格的形式,支持從圖或表中點擊跳轉到平臺的功能頁面進一步查看,如下圖詢問“哪些S3存儲桶暴露到互聯網上”
同樣也支持從自然語言到RQL查詢語句的轉換(RQL是Prisma Cloud上用于威脅狩獵調查的語句),對風險和資產的相關問題,均是轉換為RQL語句請求本地數據API,再獲得結果展示到頁面上,例如
Do I have instances with the log4j vulnerability?Copilot 會識別 log4j 是一個軟件包,并將與該軟件包關聯的 CVE ID 列表添加到轉化的RQL語句中,這也意味著PA的Copilot有一套自己的提示詞增強邏輯,最終生成RQL查詢語句
asset where asset.class = "Compute" AND WITH : vuln where id IN ( "CVE-2021-44228", "CVE-2021-45046", "CVE-2021-44832", "CVE-2021-45105" )有沒有更多呢?我們翻閱了產品文檔后,在不起眼的地方發現了以下描述

支持修復特定的CVE漏洞、支持某些風險“在代碼中修復”或“幫忙提交JIRA”,在一些PPT中我們也看到有關于自動修復的描述

那是不是由LLM自己完成的修復動作呢?實際上,了解CSPM類產品的同學應該知道,CSPM類產品中很大一部分云風險,在產品功能中會集成“一鍵修復”的功能,對Prisma Cloud也是一樣,因此針對特定漏洞的修復能力、特定云風險的修復能力,應該是產品本身具備的能力,大模型并沒有做進一步的數據分析后自主執行修復,而是根據用戶的自然語言轉化為功能API調用,完成修復
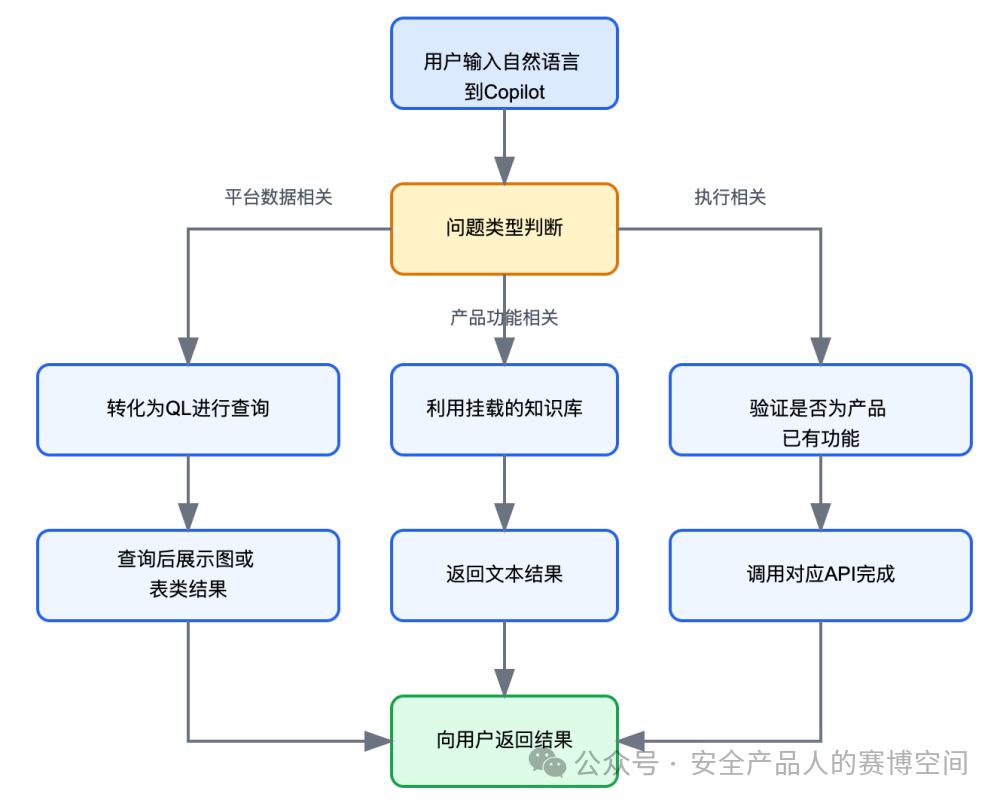
基于以上,我們總結Prisma Cloud中大模型與產品功能的融合與Cortex中類似:風險和資產類問題轉化為RQL,獲得結果以圖或表的形式展現;產品使用類問題利用RAG知識庫(產品文檔)增強,以文本形式回復;要求執行動作類問題,通過調用產品已有功能API形式完成。
Paloalto的Strata Cloud Manager也具備Copilot的能力,但是整體功能與Prisma Cloud和Cortex并無太大區別,因此我們就無需單獨列出講解,PA這幾個產品融合LLM的Copilot能力我們總結如下
四、Microsoft Security Copilot
如標題名,微軟安全產品與大模型的結合呈現,也是Copilot的形式,但是微軟的Copilot,會明顯比PA的要成熟,架構如下圖
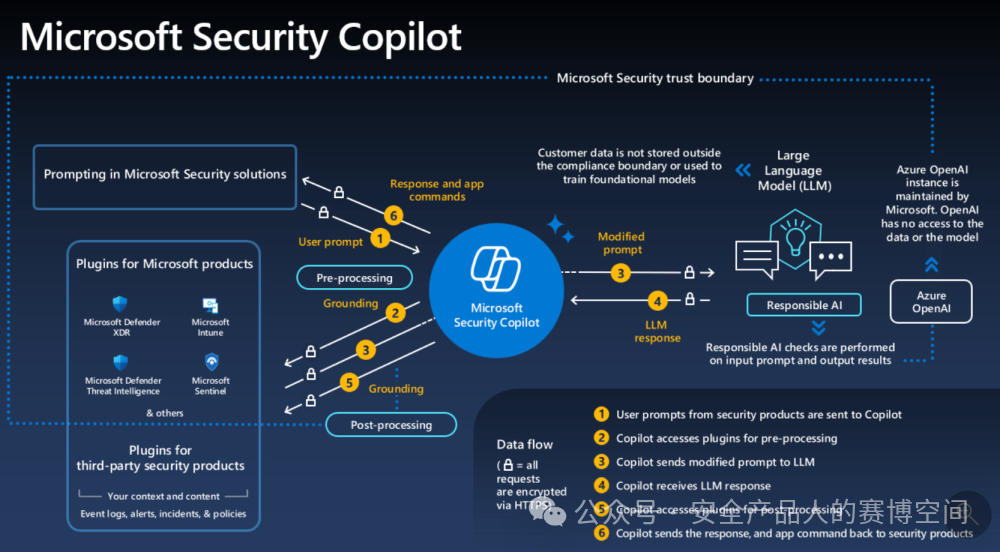
這個架構圖還是比較清晰,應該很好理解,我們展開說說兩個點,Plugins和Responsible AI
Plugins模塊,相當于大模型的數據源,支持微軟自己的安全產品、第三方的安全產品、用戶自定義安全產品,用戶所詢問的問題,會調用插件獲得安全數據,再由大模型給出答案,例如,我們詢問某個IP是否威脅?如果你沒開啟威脅情報插件,那么大模型回答不了這個問題,必須開啟這個插件,才有威脅情報數據,Copilot所支持的一些插件部分截圖如下

Responsible AI,實際上微軟的基座大模型是OpenAI的GPT4,在架構圖中的Azure OpenAI中,Responsible AI則作為中間處理數據、添加提示詞、添加知識上下文的中間服務
Microsoft Security Copilot所支持的功能示例有如下幾種

我們以“安全威脅調查和補救”為例,來看看微軟Copilot的能力
背景:“你的團隊領導給你分配了一個事件,你的工作是確定事件是否確實是惡意的,如果是,盡快解決它”
針對這個需要調查的事件,在事件功能頁面,Copilot已經默認生成了一個摘要
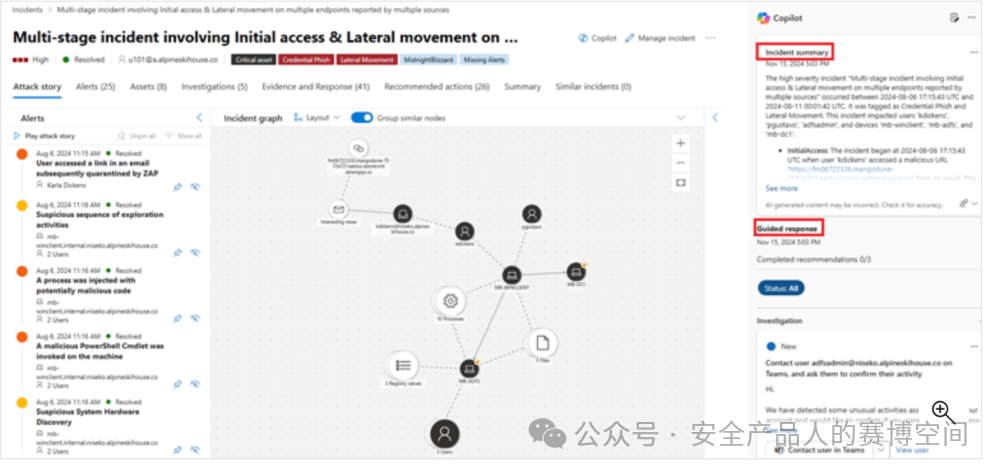
進一步的,可以在Copilot頁面,選中該事件Session,繼續進行調查,例如詢問事件TTPS

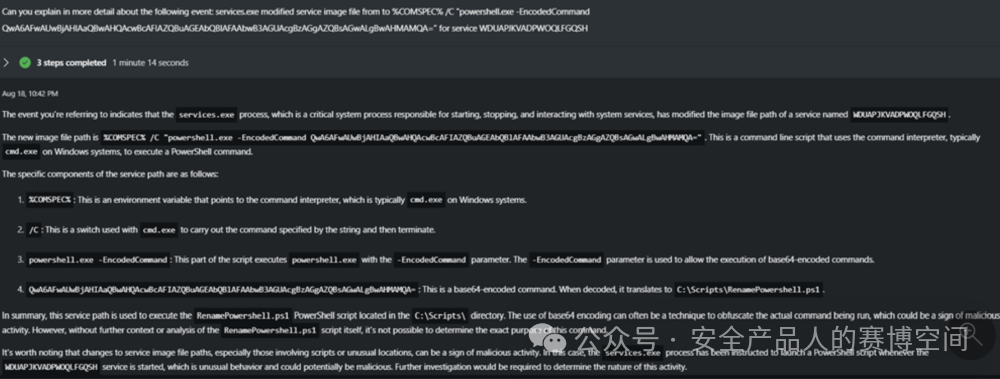
針對攻擊者在事件中所用的payload,讓Copilot解碼并分析
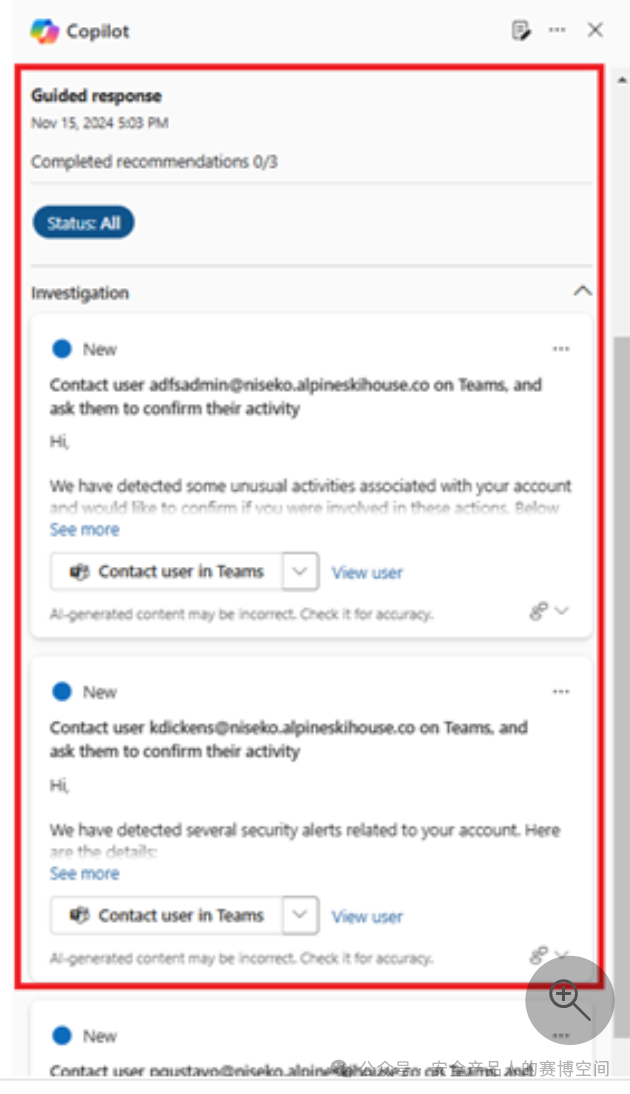
確認該事件后,Copilot給出事件的下一步響應動作建議,可在頁面跳轉到對應功能去執行
我們最終也并沒有看到一些自動修復、自動處置等能力,也就是說微軟的Copilot依然以查詢、調查、給建議的能力為主,不具備安全AI Agents的能力(跟PA一樣),提高安全運營的效率,但做不到自動化安全運營
也許是為了彌補這個問題,微軟Copilot配備了一個與Azure Logic Apps workflow工作流對接的connector,通過connector(可以理解為微軟Copilot對外的一組API服務),可以在workflow中可以調用Copilot

通過workflow在調用Copilot后,基于Copilot的輸出,做下一步執行動作,以此來代替部分安全Agents的能力
另一個有趣的點是,也許擔心用戶不知道如何發問、問哪些有價值的問題,微軟Copilot有一個promptbooks的功能,用戶只需要填寫需要調查的對象,promptbooks中有一系列prompt,幫你一個個問過去,最后形成一份豐富的調查結果,例如在Sentinel中調查事件,只需要填寫事件ID,會一次性幫用戶詢問以下7個問題
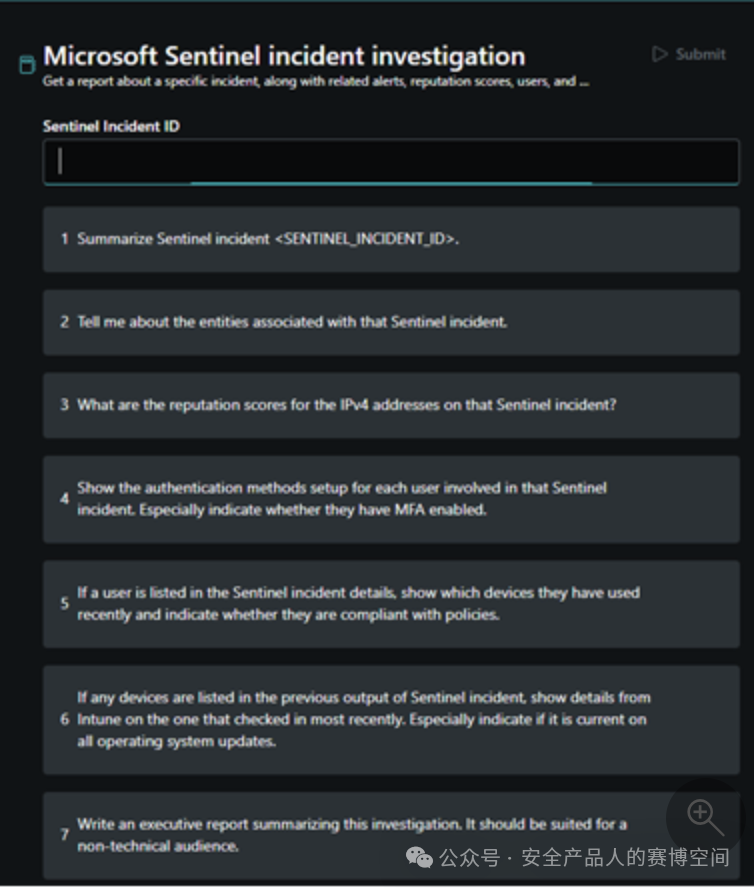
最后,我們大概總結下微軟Copilot,與Paloalto Copilot類似,也可以調用產品內的安全數據,來回答用戶的問題,但是同樣不具備Agents能力,可以提高運營效率,但無法自動化運營過程;通過插件化集成各產品、promptbooks設計、workflow工作流集成,提高了Copilot的靈活性,降低了一點用戶使用成本,這些周邊配套顯得Microsoft Security Copilot成熟度更高一點。
五、CrowdStrike Charlotte AI
CrowdStrike的Charlotte AI本質上跟我們前面介紹的PA和微軟的Copilot是一樣的東西,同樣可以用來對事件、漏洞、攻擊者信息、威脅情報等進行調查,也支持自然語言轉QL語句,promptbooks設計等

這些類似的功能我們就不贅述,翻閱相關視頻和文件資料后,跟Copilot不一樣的地方大概有以下兩個
Detection Triage功能
Charlotte AI會為每個事件,進行分類標記,標記信息有:建議動作、優先級、裁決是否誤報、裁決可信度、分類進度
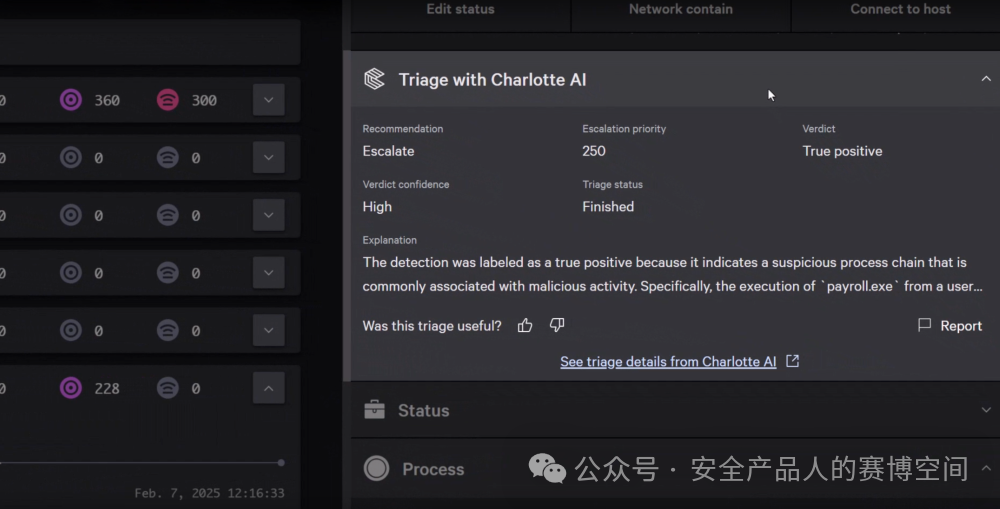
這些信息本質上完成了兩個核心動作,第一是對事件的誤報判斷,通過Charlotte AI幫忙再次確認漏洞是否誤報,并給出置信度,解決噪音淹沒告警問題;第二是對事件的優先級排序,給出的Escalation priority字段能夠幫助用戶優先處理緊急程度更高的事件。并且這個計算是后臺異步完成,完成后給事件附上這一系列的信息,有一個獨立的面板展示Charlotte AI計算triage的統計
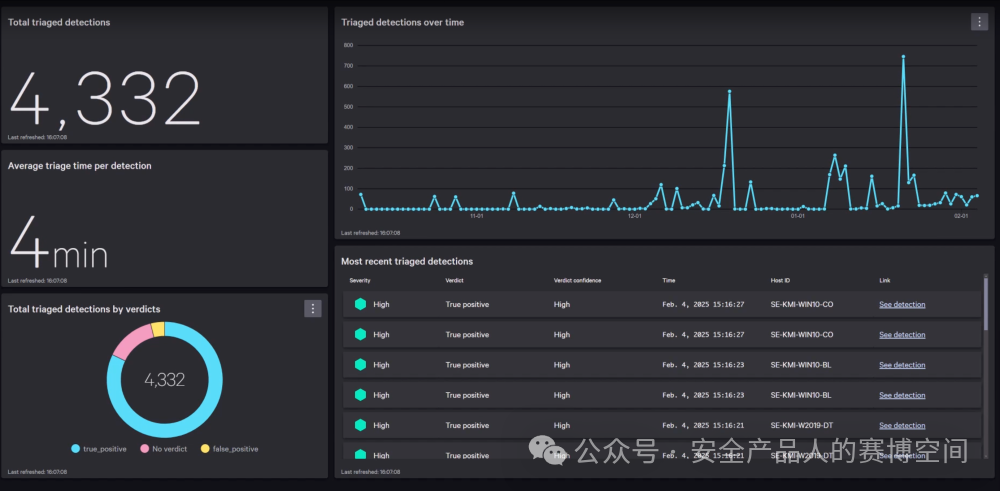
通過Detection triage功能,利用大模型在后臺自動計算更有價值的信息,將該信息直接附加到事件標簽中,用來輔助誤報消除和優先級排序,提供了更豐富的事件判斷條件,這在前面我們講的Copilot中是沒見到的。
另一個功能我們簡單提一下,當你對Charlotte AI進行提問后,Charlotte AI對平臺數據調查后給出回復,同時還會展示Charlotte AI通過什么參數調取的API,如下:

這個功能反映了Charlotte AI的透明度,告訴用戶本次回復執行的API操作,同時基于這些信息,用戶自己也可以學習一些事件調查的流程。
六、總結
看了以上分析后,我們總結下全球網安巨頭們的產品中應用大模型的方式,總體分為兩種
1.Copilot形式的對話輔助
我們根據Copilot與產品結合的深入程度,又可以分為三個層次,第一層,與產品平臺數據無關的問題,利用RAG知識庫即可準確回答,例如產品某某功能的使用方法、配置方法?自然語言轉為威脅狩獵查詢語句等;第二層,需要調用平臺API獲取數據才能回答的問題,例如幫我統計風險TOP10、過去24H內有哪些高危事件?等等,更優的是在對話頁面呈現交互式的摘要回答,摘要中可跳轉到平臺中繼續調查;第三層,需要調用產品功能去執行用戶下發的指令,例如幫我為該事件提交一個tickets、幫我修復這個CVE漏洞等;
當然,目前看來,這些網安大廠的產品中,大模型也沒做到或者很少做到第三層,我們可看到執行用戶指令的少之又少,或許是當下大模型的判斷依然有幻覺問題,讓各廠家不敢將處置執行功能API與大模型結合,但是大模型為整體安全的提效,往往體現在這里。
我們拋出一個提示詞,大家可以拭目以待一下看看多久后有Copilot能夠支持該提示詞“請幫我提取過去24H內發生的安全事件,分析出確認真實的事件,并幫我對這些事件完成處置,給出處置原因”,第一家支持該模式的我一定第一時間寫文章大吹特吹hh
2.大模型為功能輸出附加信息
這種形式就類似我們前面介紹的CrowdStrike的Detection triage功能,利用大模型分析數據后,把大模型思考分析的結論附加到事件、漏洞、風險中,這類信息又更多的為優先級、置信度、重要度等信息,例如:漏洞修復優先級的獲得,有一部分因素需要取決于漏洞所在業務的重要度,業務重要度如果沒有用戶手動打標的話,傳統的規則方式很難分析,那么可以用大模型基于應用功能自行分析,得出業務重要度后進而得出漏洞處置優先級。大模型分析的準確度是需要廠家不斷微調,與人工標記進行比對的,CrowdStrike的Detection triage打標結果與人工比對的擬合度是98%,這背后有大量對模型的訓練工作。
個人認為,大模型幫助輸出更高維度的標簽信息,開發難度不亞于Copilot形式的對話輔助,因為這里是需要預設合理的思維鏈條的,比如事件需要置信度的標簽,那么廠商應該引導大模型從哪些方面去判斷置信度,什么樣的告警組合是更偏向真實事件?看數量?看頻率?看內容?還是都看?是否要獲取多數據源信息?等等,都需要對大模型進行微調和訓練,并且這類標簽信息,很可能是我們上面提到大模型做自動執行的基礎。需要注意的是,這方面的能力很容易渾水摸魚,例如我們認為CrowdStrike的Detection triage的分類準確度為98%,可能我用一個未訓練微調過的LLM,準確度能做到80%,然后我就宣稱擁有了某某能力,但是區別是如果要做進一步的自動執行,我不敢做,必須要做到CrowdStrike一樣98%準確度我才敢加上用大模型做自動執行的功能。
最后,我們還是很期待網安領域的具身智能出現,現在還遠遠沒到,我會保持對大模型在安全產品中前沿應用的趨勢跟進,有眼前一亮的創新第一時間給大家分享!