

LLM vs. SAST:對GPT4高級數(shù)據(jù)分析的代碼缺陷檢測技術(shù)分析
責編:gltian |2025-06-26 14:44:02基本信息
原文標題:LLM vs. SAST: A Technical Analysis on Detecting Coding Bugs of GPT4-Advanced Data Analysis
原文作者:Madjid G. Tehrani, Eldar Sultanow, William J. Buchanan, Mahkame Houmani, Christel H. Djaha Fodja
作者單位:
- The George Washington University, Washington DC, USA
- Blockpass ID Lab, Edinburgh Napier University, Edinburgh, UK
- Capgemini Deutschland GmbH, Nuremberg, Germany
關(guān)鍵詞:LLM, GPT-4, 靜態(tài)應(yīng)用安全測試(SAST), 安全漏洞檢測, 代碼安全, 零日漏洞, AI安全性, DevSecOps
原文鏈接:https://arxiv.org/abs/2506.15212
開源代碼:https://github.com/Sultanow/vulnerability-detector-llm
論文要點
論文簡介:隨著自然語言處理的飛速發(fā)展,大語言模型(LLM),如GPT-4,在諸多領(lǐng)域得到了廣泛應(yīng)用,包括安全漏洞掃描。本論文聚焦于LLM(以GPT-4 Advanced Data Analysis為代表)在軟件漏洞檢測中的效能,并與傳統(tǒng)的靜態(tài)應(yīng)用安全測試(SAST)工具進行系統(tǒng)對比。研究通過對32類常見可利用軟件安全缺陷的對照實驗,量化了二者在準確率上的表現(xiàn)。
結(jié)果顯示,GPT-4 ADA在漏洞檢測中準確率高達94%,顯著優(yōu)于SAST工具。作者進一步討論了LLM引入的新型安全風險,并強調(diào)了“安全即設(shè)計/默認”(security by design/default)等AI系統(tǒng)安全最佳實踐的重要性。該研究既為自動化漏洞檢測帶來前沿技術(shù)的實證依據(jù),也為AI時代安全檢測工具的融合與演進提供了洞見。
研究目的:本文立足于當前軟件生態(tài)中零日漏洞仍具巨大威脅、傳統(tǒng)SAST工具漏洞挖掘存在盲區(qū)的現(xiàn)實,意在探究機器學習輔助方式——尤其以GPT-4驅(qū)動的LLM方案——是否能夠提升甚至超越現(xiàn)有靜態(tài)代碼分析方法的漏洞檢測能力。作者以“LLM(GPT-4 ADA)的準確率能否優(yōu)于主流SAST工具”為核心科學問題,圍繞代碼實際樣本展開實驗對比,旨在驗證LLM是否具備更強的漏洞發(fā)現(xiàn)能力,并為行業(yè)推動自動化、智能化代碼安全檢測提供決策參考。在此基礎(chǔ)上,論文亦關(guān)注LLM自身引入的新安全挑戰(zhàn),以及在業(yè)界落地推廣中的相關(guān)最佳實踐需求。
研究貢獻:
1. 首次以系統(tǒng)實驗的方式,對比評估了GPT-4 Advanced Data Analysis與兩個主流SAST工具(SonarQube和CloudDefence)的綜合漏洞檢測能力。
2. 基于32種常見并具威脅性的代碼漏洞案例,構(gòu)建了科學的評測框架和檢驗流程,確保結(jié)果具有較強的代表性與可重復性。
3. 實證表明,GPT-4 ADA在軟件漏洞檢測的準確率上顯著優(yōu)于SAST(達94%),且統(tǒng)計檢驗(McNemar’s test)支持結(jié)論的顯著性,這在自動化安全檢測領(lǐng)域具有突破意義。
4. 剖析了LLM安全檢測方案的新興風險,包括數(shù)據(jù)投毒、模型后門、供應(yīng)鏈攻擊等,呼吁在AI驅(qū)動安全工具開發(fā)與應(yīng)用過程中必須堅持“安全即設(shè)計/默認”等原則。
5. 強調(diào)了開發(fā)高質(zhì)量多樣化數(shù)據(jù)集與資源高效訓練模型的重要性,為未來量子計算輔助的安全AI模型、大規(guī)模聯(lián)邦學習等創(chuàng)新方向提供了研究展望。
引言
隨著軟件基礎(chǔ)設(shè)施在全球范圍的廣泛部署,代碼安全問題已成為關(guān)乎國家與社會安全的重要議題。特別是“零日漏洞”的威脅日益凸顯,此類漏洞因其在系統(tǒng)發(fā)布后長期未被發(fā)現(xiàn)與修補,極易造成嚴重的安全事故,例如著名的Heartbleed事件。盡管許多開發(fā)者注重代碼可用性,但對安全測試的關(guān)注不足,導致大量潛在漏洞流入生產(chǎn)環(huán)境。傳統(tǒng)軟件安全測試方法,尤其是靜態(tài)應(yīng)用安全測試(SAST),長期作為發(fā)現(xiàn)編碼缺陷的主力,但其在應(yīng)對多樣紛繁、安全邏輯復雜的新型攻擊時,能力受到挑戰(zhàn)。
近年來,機器學習,特別是自然語言處理領(lǐng)域的大語言模型(LLM)崛起,為自動化、智能化代碼分析帶來新契機。GPT-4等模型能理解和生成海量多語言編程內(nèi)容,也展現(xiàn)出一定的漏洞分析與修復潛力。但現(xiàn)階段行業(yè)實踐仍不清楚:GPT-4等LLM是否能夠切實提升甚至取代傳統(tǒng)SAST在漏洞發(fā)現(xiàn)上的表現(xiàn)?二者在實際樣本上的系統(tǒng)性對比實驗尚屬空白。
為此,本文聚焦于LLM與傳統(tǒng)SAST在軟件漏洞檢測能力的量化分析,并以GPT-4 Advanced Data Analysis(前身為Code Interpreter)為代表,建立科學對照實驗框架。研究涵蓋32種常見、且極具現(xiàn)實威脅的編碼缺陷,實驗數(shù)據(jù)來源權(quán)威(如GitHub、Snyk),評價指標與統(tǒng)計檢驗方法嚴謹,確保對比結(jié)果的科學性和可解釋性。此外,論文還進一步討論了LLM型安全工具自身可能帶來的額外安全風險,如模型投毒、后門植入、API暴露等,并倡導一系列AI應(yīng)用的安全最佳實踐,如安全即設(shè)計/默認、零信任架構(gòu)、SBOM等。通過這項工作,作者希冀為下一代軟件安全自動化工具的設(shè)計與選型提供堅實的實證依據(jù),同時為行業(yè)應(yīng)對AI引入的安全新挑戰(zhàn)提出啟示和建議。
相關(guān)工作與技術(shù)背景
機器學習在代碼分析與安全檢測領(lǐng)域的應(yīng)用持續(xù)擴展。早期的研究已在自動化漏洞檢測、程序糾錯、靜態(tài)及動態(tài)行為理解等方向取得進展。例如,ChatGPT在軟件自動修復(如QuixBugs基準集)中表現(xiàn)突出,顯示出LLM在部分安全相關(guān)任務(wù)中的潛能。然而,現(xiàn)有文獻也揭示,LLM對代碼的解釋與推理能力仍受限,特別是在動態(tài)語義理解及復雜邏輯推斷方面表現(xiàn)不足,且伴隨“幻覺”現(xiàn)象,需要人為參與進行結(jié)果校驗。
傳統(tǒng)SAST基于靜態(tài)代碼分析算法,可實現(xiàn)對代碼不在運行時環(huán)境中的掃描與檢測。與之對應(yīng),DAST則基于軟件運行時進行分析,二者各有優(yōu)劣。除基礎(chǔ)算法突破,領(lǐng)域?qū)<覍ぞ吒采w的數(shù)據(jù)集與測試集(如MITRE ATT&CK、CWE等標準)高度重視。近年來,LLM(如Codex、GPT-3/4)專門針對代碼語料進行了微調(diào),并在生成、理解、修復等任務(wù)上超越早期模型,明顯提升了代碼處理準確率。與此同時,業(yè)內(nèi)亦建立了開源與企業(yè)級分別的SAST平臺。論文還指出,包括模型投毒、后門、模型竊取、高價值數(shù)據(jù)泄露等AI安全議題日益突出,促使行業(yè)關(guān)注MLSecOps、數(shù)據(jù)集治理和安全MLOps架構(gòu)的建設(shè)。綜合來看,LLM與傳統(tǒng)SAST各具優(yōu)勢,二者的系統(tǒng)性量化對比成為當前領(lǐng)域的關(guān)鍵科學問題。
實驗設(shè)計與方法詳解
本研究選擇SonarQube(久經(jīng)驗證的開源SAST平臺)與CloudDefence.ai(一款新興的SaaS型SAST產(chǎn)品)作為對比工具,確保實驗結(jié)果的行業(yè)代表性與多樣性。為最大化SAST檢測能力,作者采用“雙工具或并”(‘OR’合并),即若任一工具檢測出漏洞則視為SAST整體檢測成功。LLM側(cè)則以GPT-4的Advanced Data Analysis模式為評測對象,實驗均在其Web環(huán)境下獨立運行。
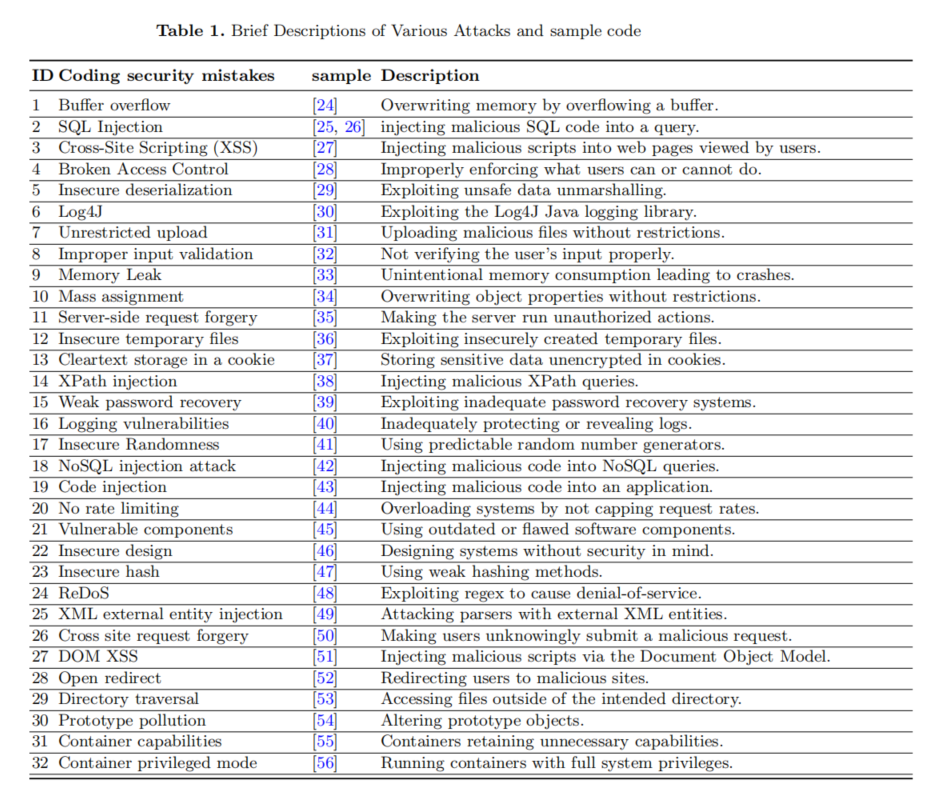
樣例選擇方面,論文利用GitHub和Snyk公開資料,涵蓋32種高危編碼缺陷,細致對齊MITRE ATT&CK與CWE標準,確保場景現(xiàn)實性與威脅全面性。這些漏洞類型包括但不限于緩沖區(qū)溢出、SQL注入、XSS跨站腳本、反序列化、邏輯缺陷、哈希不安全等,代碼涉及多語種主流環(huán)境。每個案例獨立輸入SAST工具與GPT-4,檢測結(jié)果明晰標注為“1”(檢測到)或“0”(未檢測到),全過程數(shù)據(jù)都留存于作者開源庫。
為排除偶然性與實現(xiàn)科學假設(shè)檢驗,作者構(gòu)建2×2列聯(lián)表,以McNemar’s檢驗(適用于相關(guān)聯(lián)的二元分類變量對比)為統(tǒng)計方法。設(shè)置原假設(shè)(H0:GPT-4表現(xiàn)不優(yōu)于SAST)與備擇假設(shè)(H1:GPT-4表現(xiàn)優(yōu)于SAST)。若p值小于0.05,則拒絕原假設(shè),支持GPT-4勝出。該流程保障了可復現(xiàn)性、可驗證性,為跨工具對比提供了科學依據(jù)。
實驗結(jié)果與性能分析
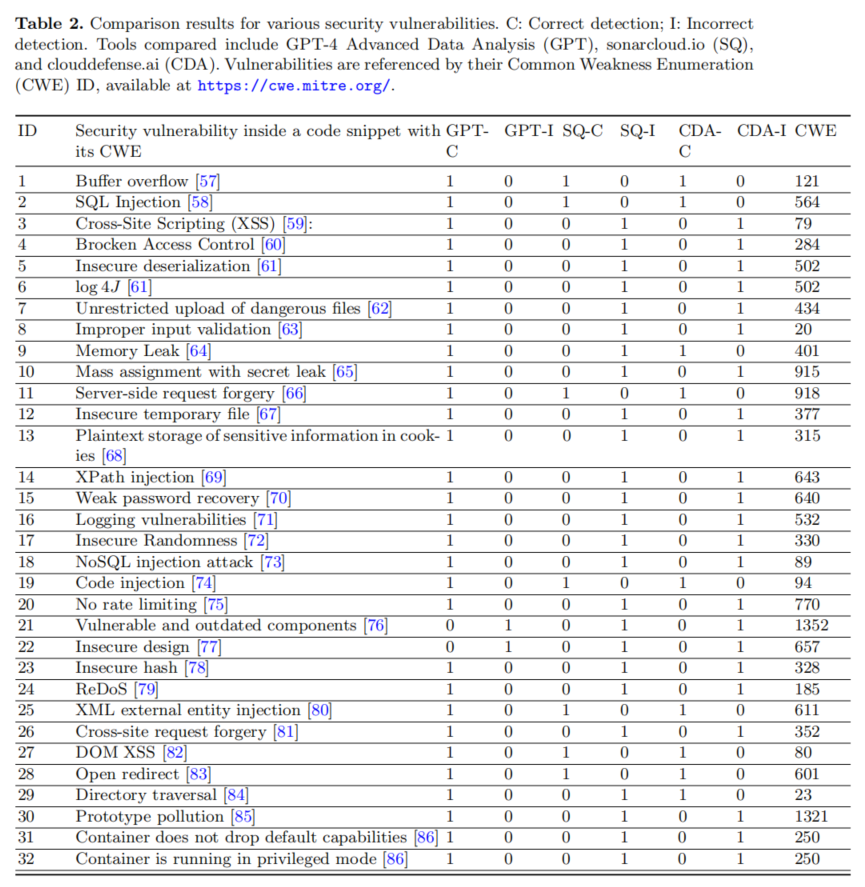
論文的實驗結(jié)果展現(xiàn)了GPT-4 Advanced Data Analysis在新一代自動化漏洞檢測領(lǐng)域的高光表現(xiàn)。具體而言,在涵蓋32類主流高危漏洞的全樣本對比中,GPT-4 ADA的總體檢測準確率高達94%,且在絕大多數(shù)漏洞類型上均實現(xiàn)100%命中,僅在“脆弱組件使用”和“不安全設(shè)計”兩類復雜漏洞上出現(xiàn)漏檢。而SAST工具(SonarQube與CloudDefence聯(lián)合)因各自專注點不同,雖在部分漏洞如傳統(tǒng)SQL注入、緩沖區(qū)溢出上表現(xiàn)優(yōu)良,但整體準確性波動明顯,針對諸如前端XSS、輸入校驗、敏感數(shù)據(jù)泄露等新興威脅存在檢測盲區(qū)。
在結(jié)果統(tǒng)計分析中,作者基于McNemar’s檢驗得出χ2=20.046,p值為0.000007562,遠小于0.05,顯著拒絕了原假設(shè)。即:GPT-4 ADA對比SAST工具在漏洞檢測準確率上具有統(tǒng)計意義上的優(yōu)勢。詳細分解,GPT-4檢測能力覆蓋了SAST遺漏的多數(shù)問題,SAST未能在GPT-4未識別的漏洞上提供補充,顯示二者尚存在能力結(jié)構(gòu)差異。分類型來看,GPT-4在輸入輸出相關(guān)漏洞、Web安全(XSS、CSRF等)、配置管理等維度尤其突出,而對與組件版本、架構(gòu)類問題則尚顯薄弱。整體而言,論文通過詳實數(shù)據(jù)證明LLM在新興安全檢測任務(wù)上的強勁潛力與實用價值,同時提醒行業(yè)關(guān)注其表現(xiàn)差異化與特定場景局限。
討論與未來研究展望
GPT-4在本項實驗中展現(xiàn)出對傳統(tǒng)SAST不可替代的增益作用,尤其體現(xiàn)在覆蓋面、判別精度和分析速度等方面。這預示著未來安全檢測工具將可能以LLM為核心,在漏洞發(fā)現(xiàn)流程中扮演更為積極的角色。與此同時,基于云服務(wù)的GPT-4等模型的使用還面臨成本優(yōu)勢與集成便捷性,為企業(yè)規(guī)模化DevSecOps落地帶來新的可行方案。然而,作者亦明確指出,LLM并非“銀彈”,其根本依賴已有訓練數(shù)據(jù),對于未來的零日漏洞和變種攻擊,仍存在識別不可知的問題。且模型的假陽性、假陰性、可解釋性與企業(yè)合規(guī)性等,均需在實際部署中細致考量。
針對未來研究,論文提出數(shù)點可能拓展方向:一方面,建議擴大SAST對比工具種類,推動行業(yè)范圍內(nèi)更為廣泛的橫向評比;另一方面,呼吁在實際項目開發(fā)、CI/CD流水線場景中實地檢驗GPT-4的實用性和兼容性,以進一步量化其落地價值。此外,作者還設(shè)想開發(fā)安全特定領(lǐng)域微調(diào)的LLM,通過高質(zhì)量、全標注、多語種的數(shù)據(jù)集豐富模型能力,并探索結(jié)合量子計算加速大規(guī)模模型訓練的前沿路徑。此外,論文敏銳關(guān)注AI安全本身的新攻擊面,如模型投毒、API保護、聯(lián)邦學習的隱私泄露、開源供應(yīng)鏈風險等。指出需完善MLSecOps、SBOM等治理機制,倡導聯(lián)邦學習、零信任等架構(gòu),同時建設(shè)權(quán)威、高質(zhì)量、安全可控的訓練與評測數(shù)據(jù)集,以防AI模型反噬正常安全防線。未來,隨著攻擊與防御對抗進入AI驅(qū)動階段,各國和產(chǎn)業(yè)應(yīng)主動開展跨平臺對抗演練,搶占AI安全制高點。
論文結(jié)論
本文通過定量實驗和統(tǒng)計分析,系統(tǒng)證明了GPT-4 Advanced Data Analysis在30余類核心編碼漏洞檢測任務(wù)中,相較于傳統(tǒng)SAST工具表現(xiàn)出更高準確率和更強通用性。這一發(fā)現(xiàn)預示著LLM有望成為自動化代碼安全檢測領(lǐng)域的新主力。然而,論文也慎重指出,LLM的巨大優(yōu)勢并不能完全取代靜態(tài)分析和系統(tǒng)性滲透測試,尤其是在復雜架構(gòu)、業(yè)務(wù)流、未知零日漏洞面前,它依賴于訓練數(shù)據(jù)的固有限制不可忽視。進一步,LLM的引入本身也帶來了如模型投毒、API濫用、后門植入、隱私泄露等新型安全隱患,要求行業(yè)把“安全即設(shè)計/默認”落到實處,加強MLSecOps、DevSecOps實踐,注重訓練數(shù)據(jù)治理、模型審計、自主控制與合規(guī)框架建設(shè)。
未來研究需著眼于開發(fā)更高質(zhì)量、多樣化且權(quán)威的數(shù)據(jù)集,推動AI安全框架一體化落地,并應(yīng)充分評估LLM與SAST等工具的融合潛力。整體來看,LLM和SAST的技術(shù)演進仍是動態(tài)決策題,持續(xù)關(guān)注其相對優(yōu)劣將成為業(yè)界共識,唯有理論、數(shù)據(jù)、實踐三位一體,方能把握AI安全工具化的未來格局。
聲明:本文來自安全極客,稿件和圖片版權(quán)均歸原作者所有。所涉觀點不代表東方安全立場,轉(zhuǎn)載目的在于傳遞更多信息。如有侵權(quán),請聯(lián)系rhliu@skdlabs.com,我們將及時按原作者或權(quán)利人的意愿予以更正。
- IDC最新攻擊面管理報告出爐,360引領(lǐng)ASM智能化新紀元
- 這個MySQL嚴重缺陷逾20年仍未修復
- LLM vs. SAST:對GPT4高級數(shù)據(jù)分析的代碼缺陷檢測技術(shù)分析
- 虛擬現(xiàn)實中的“情緒操控”:認知戰(zhàn)的未來挑戰(zhàn)與應(yīng)對
- 屢屢泄露客戶個人信息,電信巨頭賠償近13億元
- 美國后量子密碼政策解析與歐美技術(shù)全景
- 網(wǎng)安從業(yè)者必須面對的六個殘酷現(xiàn)實
- 高管網(wǎng)絡(luò)安全意識培訓:策略與禁忌
- 開源郵件系統(tǒng)RoundCube漏洞遭利用:竊密器數(shù)據(jù)如何濫用CVE-2025-49113
- 開源人工智能治理的全球?qū)嵺`及路徑選擇