

DEFCON CHINA議題解讀 | 對深度學習系統的數據流攻擊
責編:gltian |2018-05-14 09:51:35本次的DEFCON China上,360智能安全團隊負責人李康博士分享了一個關于深度學習系統數據流攻擊的議題——“Beyond Adversarial Learning-Data Scaling Attacks in Deep Learning Applications”,展示了如何讓人工智能人臉識別系統將李冰冰的照片誤認為趙本山的攻擊形式。

李康博士的研究團隊所發現的數據流攻擊是通過對輸入數據的維度特性進行改變,可以針對深度學習的數據處理環節進行攻擊,對深度學習圖像識別等應用造成逃逸攻擊以及數據污染攻擊等效果。相比于現有的深度學習系統對抗樣本生成方法,該攻擊方式不依賴于具體的深度學習模型,并在對Caffe、Tensorflow等當前主流深度學習框架有效。
一、背景——深度學習系統中的數據預處理
1.1為什么需要數據預處理?
一般而言,深度學習系統主要包括數據采集、數據預處理、深度學習模型以及決策執行四個環節,其中數據預處理的作用是依據模型輸入要求將采集到的原始數據進行格式、大小等屬性的調整。接下來就以基于深度學習在圖像識別的應用為例進行說明。
目前多數圖像識別系統都是基于預先訓練好的網絡模型,這就帶來一個很大的限制——輸入層大小固定。在NVIDIA提供的多個無人駕駛模型中,模型的輸入圖片尺寸都被要求為226*66。而NVIDIA提供的推薦攝像頭尺寸范圍是320*240至1928*1208等多種圖片大小,但是200*66并不屬于此范圍內,這就要求在使用模型時必須將原始圖片統一縮放至200*66的標準尺寸。此外經調研發現,不同的深度學習視覺應用模型所要求的輸入尺寸多種多樣,這使得圖片縮放這一數據預處理環節在實際應用中不可或缺。
2.2數據預處理做了什么?
如前所言,計算機視覺領域的數據預處理主要指Scaling/Resizing操作,即對圖像尺寸進行調整的過程。該過程主要由插值算法實現,主要包括最近鄰插值、雙線性插值、三次插值等。下圖簡單展示了用最近鄰插值將4*4大小圖片壓縮到2*2大小的過程,其它的算法會有相對復雜的公式。
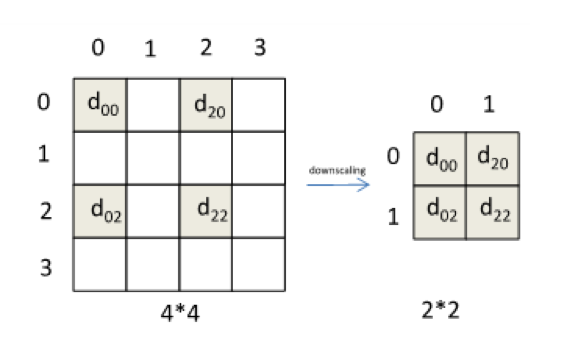
可以看到,壓縮的過程中伴隨著有效信息的丟失。不幸的是,在許多深度學習框架所采用的數據預處理環節,并沒有考慮到這些信息丟失可能會帶來的安全威脅。接下來李康博士將展示他們如何利用這些被丟棄掉的有效信息,來對如下的深度學習系統進行數據流攻擊。

二、數據流維度攻擊
數據流維度攻擊,顧名思義,是指對數據尺度變換的過程開展的攻擊。在本例中,通過對輸入圖片插入惡意偽造信息,在深度學習系統對圖片進行縮放后使其對于模型的輸入發生變化,造成人與機器對于同一輸入圖片的“認知代溝”。
2.1 攻擊原理
以下為針對圖像識別系統的自動化數據流維度攻擊的原理圖。
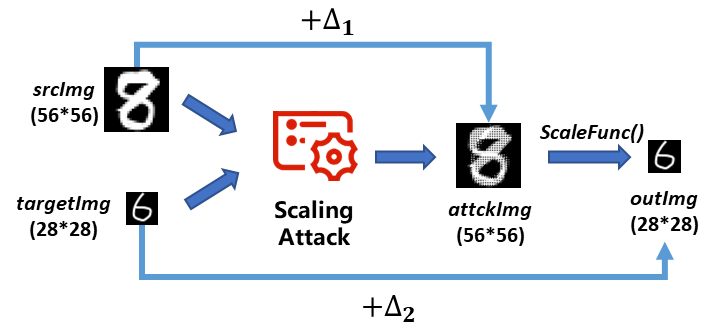
在此給出自動化攻擊的模型。假設攻擊者給定一張m*n大小的原始圖片srcImg(Sm*n)和一張希望機器預處理之后得到的m’*n’大小的目標圖片targetImg(Tm’*n’)。最終經過自動化Scaling Attack后,在Sm*n上引入變化量△1,生成攻擊樣本attackImg(Am*n),經過機器預處理后輸出圖片為outImg(Dm’*n’),其與目標圖片的差異度為△2。
理想的攻擊效果是人類無法區分原始圖片以及偽造樣本,而機器無法區分目標圖片以及偽造樣本的輸出圖片。因此我們希望變化△1和△2能夠盡可能小。由此可以得出指導我們進行自動化攻擊的數學模型。
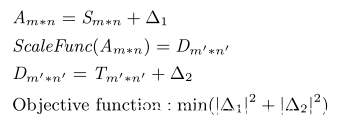
通過對該二次優化問題進行求解,最終可以實現自動化的Scaling attack。
2.2 攻擊效果展示
該團隊對主流深度模型的圖像變換算法進行了調研,據此對選取典型的圖像預處理函數進行了攻擊,并在此展示部分攻擊效果。
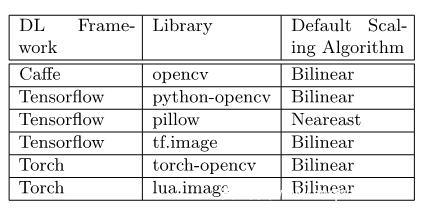
1.對MNIST手寫識別數據集的攻擊
攻擊輸入:
![]()
預處理輸出:
![]()
攻擊輸入:
 預處理輸出:
預處理輸出:
![]()
2.對人像的掩蓋攻擊
攻擊輸入:

預處理輸出:

攻擊輸入:

預處理輸出:

三、防御手段
針對上述攻擊,李康博士向大家介紹了幾種可行的防御措施。
1.過濾并丟舍棄與深度學習模型輸入大小不匹配的樣本。
該手段可以從根本上消除維度攻擊帶來的危害,但僅僅適用于數據傳感器可以受用戶控制和調整的情況,等多的時候該方法無異于“傷敵一千,自損八百”。限定輸入數據大小會極大降低深度學習系統的通用性,破壞深度學習系統在不同硬件平臺上的可移植性。
2.使用更加健壯的數據變換算法
在數據預處理環節開發者應該選用表現更加穩定的數據變化算法,如雙三次方插值。這類插值算法在進行數據縮放時會引入更多的樣本點之間的相關性信息,這會增加攻擊模型求解的難度和最終的求解效果。此外,開發人員還可以考慮對于數據變化因子引入隨機化方法,不確定的數據變換方式會導致攻擊者針對的數據變換算法與實際處理算法的差異,從而對抗相應的攻擊。
3.對預處理前后的數據變化進行檢測。
第三類方法是對數據預處理產生的結果與原始輸入進行相似度比對。通過對數據分布、樣本點相關性等特征進行比對,可以檢測數據預處理前后信息的變化情況,從而對數據預處理環節進行可靠性評估。
四、小結
數據流維度攻擊是對深度學習應用一種新型攻擊方法,主要影響對任意圖片進行識別的深度學習應用程序。 李康團隊的工作旨在提醒公眾和研究人員,在擁抱人工智能熱潮的同時,需要持續關注深度學習系統中的安全問題。