

軟件供應鏈安全威脅:從“奧創紀元”到“無限戰爭”
責編:gltian |2019-03-07 14:01:27在2018年5月到12月,伴隨著阿里安全主辦的軟件供應鏈安全大賽,我們自身在設計、引導比賽的形式規則的同時,也在做著反思和探究,直接研判諸多方面潛在風險,以及透過業界三方的出題和解題案例分享,展示了行業內一線玩家對問題、解決方案實體化的思路
(參見如下歷史文章:
2、阿里軟件供應鏈安全大賽到底在比什么?C源代碼賽季官方賽題精選出爐!
3、『功守道』軟件供應鏈安全大賽·PE二進制賽季啟示錄:上篇
4、『功守道』軟件供應鏈安全大賽·PE二進制賽季啟示錄:下篇
另外,根據近期的一些歷史事件,也做了一些深挖和聯想,考慮惡意的上游開發者,如何巧妙(或者說,處心積慮)地將問題引入,并在當前的軟件供應鏈生態體系中,造成遠比表面上看起來要深遠得多的影響(參見:《深挖CVE-2018-10933(libssh服務端校驗繞過)兼談軟件供應鏈真實威脅》)。
以上這些,拋開體系化的設想,只看案例,可能會得到這樣的印象:這種威脅,都是由蓄意的上游或第三方參與者造成的;即便在最極端情況下,假使一個大型軟件商或開源組織,被發現存在廣泛、惡意的上游代碼污染,那它頂多也不過相當于“奧創”一樣的邪惡寡頭,與其劃清界限、清除歷史包袱即可,雖然可能有陣痛。
可惜,并非如此。
在我們組織比賽的后半程中,對我們面臨的這種威脅類型,不斷有孤立的事例看似隨機地發生,對此我以隨筆的方式對它們做了分析和記錄,以下與大家分享。
Ⅰ. 從感染到遺傳:LibVNC與TightVNC系列漏洞
2018年12月10日晚9:03,OSS漏洞預警平臺彈出的一封漏洞披露郵件,引起了我的注意。披露者是卡巴斯基工控系統漏洞研究組的Pavel Cheremushkin。
一些必要背景
VNC是一套屏幕圖像分享和遠程操作軟件,底層通信為RFB協議,由劍橋某實驗室開發,后1999年并入AT&T,2002年關停實驗室與項目,VNC開源發布。
VNC本被設計用在局域網環境,且誕生背景決定其更傾向研究性質,商用級安全的缺失始終是個問題。后續有若干新的實現軟件,如TightVNC、RealVNC,在公眾認知中,AT&T版本已死,后起之秀一定程度上修正了問題。
目前各種更優秀的遠程控制和分享協議取代了VNC的位置,盡管例如蘋果仍然系統內建VNC作為遠程方式。但在非桌面領域,VNC還有我們想不到的重要性,比如工控領域需要遠程屏幕傳輸的場景,這也是為什么這系列漏洞作者會關注這一塊。
漏洞技術概況
Pavel總結到,在階段漏洞挖掘中共上報11個漏洞。在披露郵件中描述了其中4個的技術細節,均在協議數據包處理代碼中,漏洞類型古典,分別是全局緩沖區溢出、堆溢出和空指針解引用。其中緩沖區溢出類型漏洞可方便構造PoC,實現遠程任意代碼執行的漏洞利用。
漏洞本身原理簡單,也并不是關鍵。以其中一個為例,Pavel在發現時負責任地向LibVNC作者提交了issue,并跟進漏洞修復過程;在第一次修復之后,復核并指出修復代碼無效,給出了有效patch。這個過程是常規操作。
漏洞疑點
有意思的是,在漏洞披露郵件中,Pavel重點談了自己對這系列漏洞的一些周邊發現,也是這里提到的原因。其中,關于存在漏洞的代碼,作者表述:
我最初認為,這些問題是libvnc開發者自己代碼中的錯誤,但看起來并非如此。其中有一些(如CoRRE數據處理函數中的堆緩沖區溢出),出現在AT&T實驗室1999年的代碼中,而后被很多軟件開發者原樣復制(在Github上搜索一下HandleCoRREBPP函數,你就知道),LibVNC和TightVNC也是如此。
為了證實,翻閱了這部分代碼,確實在其中數據處理相關代碼文件看到了劍橋和AT&T實驗室的文件頭GPL聲明注釋,

這證實這些文件是直接從最初劍橋實驗室版本VNC移植過來的,且使用方式是?直接代碼包含,而非獨立庫引用方式。在官方開源發布并停止更新后,LibVNC使用的這部分代碼基本沒有改動——除了少數變量命名方式的統一,以及本次漏洞修復。通過搜索,我找到了2000年發布的相關代碼文件,確認這些文件與LibVNC中引入的原始版本一致。
另外,Pavel同時反饋了TightVNC中相同的問題。TightVNC與LibVNC沒有繼承和直接引用關系,但上述VNC代碼同樣被TightVNC使用,問題的模式不約而同。Pavel測試發現在Ubuntu最新版本TightVNC套件(1.3.10版本)中同樣存在該問題,上報給當前軟件所有者GlavSoft公司,但對方聲稱目前精力放在不受GPL限制的TightVNC 2.x版本開發中,對開源的1.x版本漏洞代碼“可能會進行修復”。看起來,這個問題被踢給了各大Linux發行版社區來焦慮了——如果他們愿意接鍋。
問題思考
在披露郵件中,Pavel認為,這些代碼bug“如此明顯,讓人無法相信之前沒被人發現過……也許是因為某些特殊理由才始終沒得到修復”。
事實上,我們都知道目前存在一些對開源基礎軟件進行安全掃描的大型項目,例如Google的OSS;同時,仍然存活的開源項目也越來越注重自身代碼發布前的安全掃描,Fortify、Coverity的掃描也成為很多項目和平臺的標配。在這樣一些眼睛注視下,為什么還有這樣的問題?我認為就這個具體事例來說,可能有如下兩個因素:
- 上游已死。仍然在被維護的代碼,存在版本更迭,也存在外界的持續關注、漏洞報告和修復、開發的迭代,對于負責人的開發者,持續跟進、評估、同步代碼的改動是可能的。但是一旦一份代碼走完了生命周期,就像一段史實一樣會很少再被改動。
- 對第三方上游代碼的無條件信任。我們很多人都有過基礎組件、中間件的開發經歷,不乏有人使用Coverity開啟全部規則進行代碼掃描、嚴格修復所有提示的問題甚至編程規范warning;報告往往很長,其中也包括有源碼形式包含的第三方代碼中的問題。但是,我們一方面傾向于認為這些被廣泛使用的代碼不應存在問題(不然早就被人挖過了),一方面考慮這些引用的代碼往往是組件或庫的形式被使用,應該有其上下文才能認定是否確實有可被利用的漏洞條件,現在單獨掃描這部分代碼一般出來的都是誤報。所以這些代碼的問題都容易被忽視。
但是透過這個具體例子,再延伸思考相關的實踐,這里最根本的問題可以總結為一個模式:?復制粘貼風險。復制粘貼并不簡單意味著剽竊,實際是當前軟件領域、互聯網行業發展的基礎模式,但其中有一些沒人能嘗試解決的問題:
- 在傳統代碼領域,如C代碼中,對第三方代碼功能的復用依賴,往往通過直接進行庫的引入實現,第三方代碼獨立而完整,也較容易進行整體更新;這是最簡單的情況,只需要所有下游使用者保證僅使用官方版本,跟進官方更新即可;但在實踐中很難如此貫徹,這是下節討論的問題。
- 有些第三方發布的代碼,模式就是需要被源碼形式包含到其他項目中進行統一編譯使用(例如騰訊的開源Json解析庫RapidJSON,就是純C++頭文件形式)。在開源領域有如GPL等規約對此進行規范,下游開發者遵循協議,引用代碼,強制或可選地顯式保留其GPL聲明,可以進行使用和更改。這樣的源碼依賴關系,結合規范化的changelog聲明代碼改動,側面也是為開發過程中跟進考慮。但是一個成型的產品,比如企業自有的服務端底層產品、中間件,新版本的發版更新是復雜的過程,開發者在舊版本仍然“功能正常”的情況下往往傾向于不跟進新版本;而上游代碼如果進行安全漏洞修復,通常也都只在其最新版本代碼中改動,安全修復與功能迭代并存,如果沒有類似Linux發行版社區的努力,舊版本代碼完全沒有干凈的安全更新patch可用。
- 在特定場景下,有些開發實踐可能不嚴格遵循開源代碼協議限定,引入了GPL等協議保護的代碼而不做聲明(以規避相關責任),丟失了引入和版本的信息跟蹤;在另一些場景下,可能存在對開源代碼進行大刀闊斧的修改、剪裁、定制,以符合自身業務的極端需求,但是過多的修改、人員的迭代造成與官方代碼嚴重的失同步,喪失可維護性。
- 更一般的情況是,在開發中,開發者個體往往心照不宣的存在對網上代碼文件、代碼片段的復制-粘貼操作。被參考的代碼,可能有上述的開源代碼,也可能有各種Github作者練手項目、技術博客分享的代碼片段、正式開源項目僅用來說明用法的不完備示例代碼。這些代碼的引入完全無跡可尋,即便是作者自己也很難解釋用了什么。這種情況下,上面兩條認定的那些與官方安全更新失同步的問題同樣存在,且引入了獨特的風險:被借鑒的代碼可能只是原作者隨手寫的、僅僅是功能成立的片段,甚至可能是惡意作者隨意散布的有安全問題的代碼。由此,問題進入了最大的發散空間。
在Synopsys下BLACKDUCK軟件之前發布的《2018 Open Source Security and Risk Analysis Report》中分析,96%的應用中包含有開源組件和代碼,開源代碼在應用全部代碼中的占比約為57%,78%的應用中在引用的三方開源代碼中存在歷史漏洞。也就是說,現在互聯網上所有廠商開發的軟件、應用,其開發人員自己寫的代碼都是一少部分,多數都是借鑒來的。而這還只是可統計、可追溯的;至于上面提到的非規范的代碼引用,如果也納入進來考慮,三方代碼占應用中的比例會上升到多少?曾經有分析認為至少占80%,我們只期望不會更高。
Ⅱ. 從碎片到亂刃:OpenSSH在野后門一覽
在進行基礎軟件梳理時,回憶到反病毒安全軟件提供商ESET在2018年十月發布的一份白皮書《THE DARK SIDE OF THE FORSSHE: A landscape of OpenSSH backdoors》。其站在一個具有廣泛用戶基礎的軟件提供商角度,給出了一份分析報告,數據和結論超出我們對于當前基礎軟件使用全景的估量。以下以我的角度對其中一方面進行解讀。
一些必要背景
SSH的作用和重要性無需贅言;雖然我們站在傳統互聯網公司角度,可以認為SSH是通往生產服務器的生命通道,但當前多樣化的產業環境已經不止于此(如之前libssh事件中,不幸被我言中的,SSH在網絡設備、IoT設備上(如f5)的廣泛使用)。
OpenSSH是目前絕大多數SSH服務端的基礎軟件,有完備的開發團隊、發布規范、維護機制,本身是靠譜的。如同絕大多數基礎軟件開源項目的做法,OpenSSH對漏洞有及時的響應,針對最新版本代碼發出安全補丁,但是各大Linux發行版使用的有各種版本的OpenSSH,這些社區自行負責將官方開發者的安全補丁移植到自己系統搭載的低版本代碼上。
白皮書披露的現狀
如果你是一個企業的運維管理人員,需要向企業生產服務器安裝OpenSSH或者其它基礎軟件,最簡單的方式當然是使用系統的軟件管理安裝即可。但是有時候,出于遷移成本考慮,可能企業需要在一個舊版本系統上,使用較新版本的OpenSSL、OpenSSH等基礎軟件,這些系統不提供,需要自行安裝;或者需要一個某有種特殊特性的定制版本。這時,可能會選擇從某些rpm包集中站下載某些不具名第三方提供的現成的安裝包,或者下載非官方的定制化源碼本地編譯后安裝,總之從這里引入了不確定性。
這種不確定性有多大?我們粗估一下,似乎不應成為問題。但這份白皮書給我們看到了鮮活的數據。
ESET研究人員從OpenSSH的一次歷史大規模Linux服務端惡意軟件Windigo中獲得啟示,采用某種巧妙的方式,面向在野的服務器進行數據采集,主要是系統與版本、安裝的OpenSSH版本信息以及服務端程序文件的一個特殊簽名。整理一個簽名白名單,包含有所有能搜索到的官方發布二進制版本、各大Linux發行版本各個版本所帶的程序文件版本,將這些標定為正常樣本進行去除。最終結論是:
- 共發現了幾百個非白名單版本的OpenSSH服務端程序文件ssh和sshd;
- 分析這些樣本,將代碼部分完全相同,僅僅是數據和配置不同的合并為一類,且分析判定確認有惡意代碼的,共歸納為?21個各異的惡意OpenSSH家族;
- 在21個惡意家族中,有12個家族在10月份時完全沒有被公開發現分析過;而剩余的有一部分使用了歷史上披露的惡意代碼樣本,甚至有源代碼;
- 所有惡意樣本的實現,從實現復雜度、代碼混淆和自我保護程度到代碼特征有很大跨度的不同,但整體看,目的以偷取用戶憑證等敏感信息、回連外傳到攻擊者為主,其中有的攻擊者回連地址已經存在并活躍數年之久;
- 這些后門的操控者,既有傳統惡意軟件黑產人員,也有APT組織;
- 所有惡意軟件或多或少都在被害主機上有未抹除的痕跡。ESET研究者嘗試使用蜜罐引誘出攻擊者,但仍有許多未解之謎。這場對抗,仍未取勝。
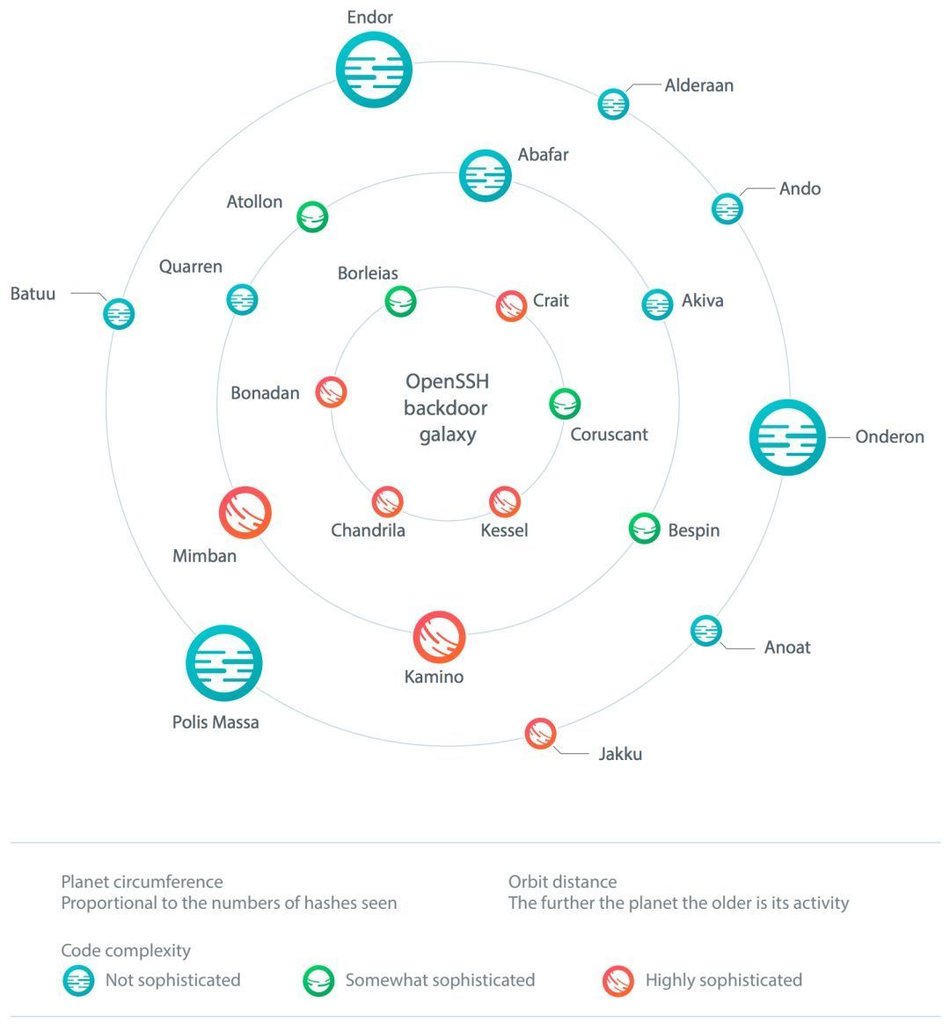
白皮書用了大篇幅做技術分析報告,此處供細節分析,不展開分析,以下為根據惡意程序復雜度描繪的21個家族圖譜:
問題思考
問題引入的可能渠道,我在開頭進行了一點推測,主要是由人的原因切入的,除此以外,最可能的是惡意攻擊者在利用各種方法入侵目標主機后,主動替換了目標OpenSSH為惡意版本,從而達成攻擊持久化操作。但是這些都是止血的安全運維人員該考慮的事情;關鍵問題是,透過表象,這顯露了什么威脅形式?
這個問題很好回答,之前也曾經反復說過:基礎軟件碎片化。
如上一章節簡單提到,在開發過程中有各種可能的渠道引入開發者不完全了解和信任的代碼;在運維過程中也是如此。二者互相作用,造成了軟件碎片化的龐雜現狀。在企業內部,同一份基礎軟件庫,可能不同的業務線各自定制一份,放到企業私有軟件倉庫源中,有些會有人持續更新供自己產品使用,有些由系統軟件基礎設施維護人員單獨維護,有些則可能是開發人員臨時想起來上傳的,他們自己都不記得;后續用到的這個基礎軟件的開發和團隊,在這個源上搜索到已有的庫,很大概率會傾向于直接使用,不管來源、是否有質量背書等。長此以往問題會持續發酵。而我們開最壞的腦洞,是否可能有黑產人員入職到內部,提交個惡意基礎庫之后就走人的可能?現行企業安全開發流程中審核機制的普遍缺失給這留下了空位。
將源碼來源碎片化與二進制使用碎片化并起來考慮,我們不難看到一個遠遠超過OpenSSH事件威脅程度的圖景。但這個問題不是僅僅靠開發階段規約、運維階段規范、企業內部管控、行業自查、政府監管就可以根除的,最大的問題歸根結底兩句話:?不可能用一場戰役對抗持續威脅;不可能用有限分析對抗無限未知。
Ⅲ. 從自信到自省:RHEL、CentOS backport版本BIND漏洞

2018年12月20日凌晨,在備戰冬至的軟件供應鏈安全大賽決賽時,我注意到漏洞預警平臺捕獲的一封郵件。但這不是一個漏洞初始披露郵件,而是對一個稍早已披露的BIND在RedHat、CentOS發行版上特定版本的1day漏洞CVE-2018-5742,由BIND的官方開發者進行額外信息澄(shuǎi)清(guō)的郵件。
一些必要背景
關于BIND
互聯網的一個古老而基礎的設施是DNS,這個概念在讀者不應陌生。而BIND“是現今互聯網上最常使用的DNS軟件,使用BIND作為服務器軟件的DNS服務器約占所有DNS服務器的九成。BIND現在由互聯網系統協會負責開發與維護參考。”所以BIND的基礎地位即是如此,因此也一向被大量白帽黑帽反復測試、挖掘漏洞,其開發者大概也一直處在緊繃著應對的處境。
關于ISC和RedHat
說到開發者,上面提到BIND的官方開發者是互聯網系統協會(ISC)。ISC是一個老牌非營利組織,目前主要就是BIND和DHCP基礎設施的維護者。而BIND本身如同大多數歷史悠久的互聯網基礎開源軟件,是4個UCB在校生在DARPA資助下于1984年的實驗室產物,直到2012年由ISC接管。
那么RedHat在此中是什么角色呢?這又要提到我之前提到的Linux發行版和自帶軟件維護策略。Red Hat Enterprise Linux(RHEL)及其社區版CentOS秉持著穩健的軟件策略,每個大的發行版本的軟件倉庫,都只選用最必要且質量久經時間考驗的軟件版本,哪怕那些版本實在是老掉牙。這不是一種過分的保守,事實證明這種策略往往給RedHat用戶在最新漏洞面前提供了保障——代碼總是跑得越少,潛在漏洞越多。
但是這有兩個關鍵問題。
一方面,如果開源基礎軟件被發現一例有歷史沿革的代碼漏洞,那么官方開發者基本都只為其最新代碼負責,在當前代碼上推出修復補丁。
另一方面,互聯網基礎設施雖然不像其上的應用那樣爆發性迭代,但依然持續有一些新特性涌現,其中一些是必不可少的,但同樣只在最新代碼中提供。
兩個剛需推動下,各Linux發行版對長期支持版本系統的軟件都采用一致的策略,即保持其基礎軟件在一個固定的版本,但對于這些版本軟件的最新漏洞、必要的最新軟件特性,由發行版維護者將官方開發者最新代碼改動“向后移植”到舊版本代碼中,即backport。這就是基礎軟件的“官宣”碎片化的源頭。
講道理,Linux發行版維護者與社區具有比較靠譜的開發能力和監督機制,backport又基本就是一些復制粘貼工作,應當是很穩當的……但真是如此嗎?
CVE-2018-5742漏洞概況
CVE-2018-5742是一個簡單的緩沖區溢出類型漏洞,官方評定其漏洞等級moderate,認為危害不大,漏洞修復不積極,披露信息不多,也沒有積極給出代碼修復patch和新版本rpm包。因為該漏洞僅在設置DEBUG_LEVEL為10以上才會觸發,由遠程攻擊者構造畸形請求造成BIND服務崩潰,在正常的生產環境幾乎不可能具有危害,RedHat官方也只是給出了用戶自查建議。
這個漏洞只出現在RHEL和CentOS版本7中搭載的BIND 9.9.4-65及之后版本。RedHat同ISC的聲明中都證實,這個漏洞的引入原因,是RedHat在嘗試將BIND 9.11版本2016年新增的NTA機制向后移植到RedHat 7系中固定搭載的BIND 9.9版本代碼時,偶然的代碼錯誤。NTA是DNS安全擴展(DNSSEC)中,用于在特定域關閉DNSSEC校驗以避免不必要的校驗失敗的機制;但這個漏洞不需要對NTA本身有進一步了解。
漏洞具體分析
官方沒有給出具體分析,但根據CentOS社區里先前有用戶反饋的bug,我得以很容易還原漏洞鏈路并定位到根本原因。
若干用戶共同反饋,其使用的BIND 9.9.4-RedHat-9.9.4-72.el7發生崩潰(coredump),并給出如下的崩潰時調用棧backtrace:

這個調用過程的邏輯為,在#9 dns_message_logfmtpacket函數判斷當前軟件設置是否DEBUG_LEVEL大于10,若是,對用戶請求數據包做日志記錄,先后調用#8 dns_message_totext、#7 dns_message_sectiontotext、#6 dns_master_rdatasettotext、#5 rdataset_totext將請求進行按協議分解分段后寫出。
由以上關鍵調用環節,聯動RedHat在9.9.4版本BIND源碼包中關于引入NTA特性的源碼patch,進行代碼分析,很快定位到問題產生的位置,在上述backtrace中的#5,masterdump.c文件rdataset_totext函數。漏洞相關代碼片段中,RedHat進行backport后,這里引入的代碼為:

這里判斷對于請求中的注釋類型數據,直接通過isc_buffer_putstr宏對緩存進行操作,在BIND工程中自定義維護的緩沖區結構對象target上,附加一字節字符串(一個分號)。而漏洞就是由此產生:isc_buffer_putstr中不做緩沖區邊界檢查保證,這里在緩沖區已滿情況下將造成off-by-one溢出,并觸發了緩沖區實現代碼中的assertion。
而ISC上游官方版本的代碼在這里是怎么寫的呢?找到ISC版本BIND 9.11代碼,這里是這樣的:
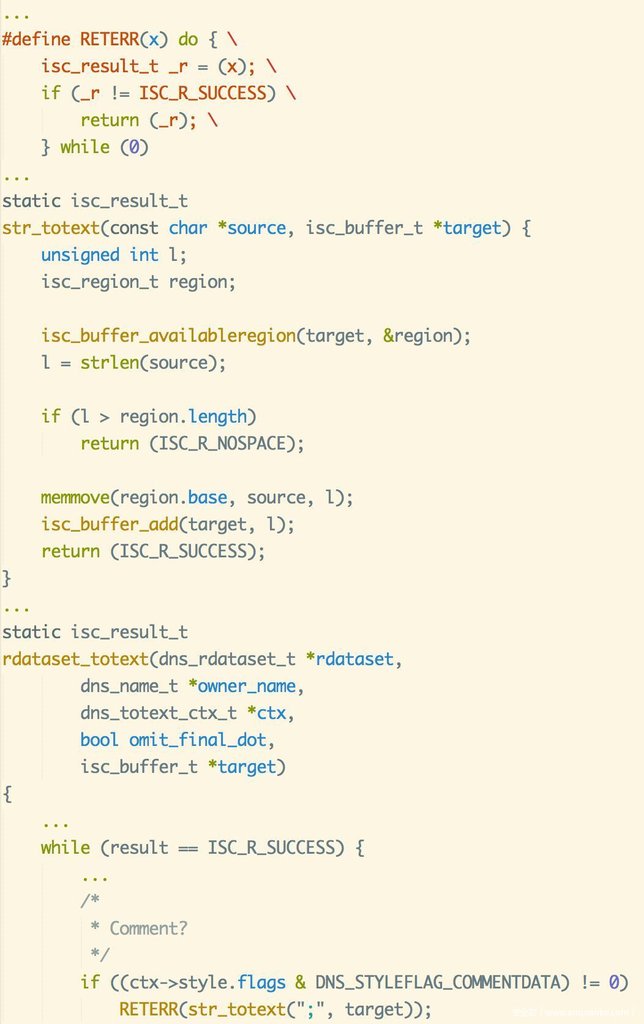
這里可以看到,官方代碼在做同樣的“附加一個分號”這個操作時,審慎的使用了做緩沖區剩余空間校驗的str_totext函數,并額外做返回值成功校驗。而上述提到的str_totext函數與RETERR宏,在移植版本的masterdump.c中,RedHat開發者也都做了保留。但是,查看代碼上下文發現,在RedHat開發者進行代碼移植過程中,對官方代碼進行了功能上的若干剪裁,包括一些細分數據類型記錄的支持;而這里對緩沖區寫入一字節,也許開發者完全沒想到溢出的可能,所以自作主張地簡化了代碼調用過程。
問題思考
這個漏洞本身幾乎沒什么危害,但是背后足以引起思考。
沒有人在“借”別人代碼時能不出錯
不同于之前章節提到的那種場景——將代碼文件或片段復制到自己類似的代碼上下文借用——backport作為一種官方且成熟的做法,借用的代碼來源、粘貼到的代碼上下文,是具有同源屬性的,而且開發者一般是追求穩定性優先的社區開發人員,似乎質量應該有足夠保障。但是這里的關鍵問題是:代碼總要有一手、充分的語義理解,才能有可信的使用保障;因此,只要是處理他人的代碼,因為不夠理解而錯誤使用的風險,只可能減小,沒辦法消除。
如上分析,本次漏洞的產生看似只是做代碼移植的開發者“自作主張”之下“改錯了”。但是更廣泛且可能的情況是,原始開發者在版本迭代中引入或更新大量基礎數據結構、API的定義,并用在新的特性實現代碼中;而后向移植開發人員僅需要最小規模的功能代碼,所以會對增量代碼進行一定規模的修改、剪裁、還原,以此適應舊版本基本代碼。這些過程同樣伴隨著第三方開發人員不可避免的“望文生義”,以及隨之而來的風險。后向移植操作也同樣助長了軟件碎片化過程,其中每一個碎片都存在這樣的問題;每一個碎片在自身生命周期也將有持續性影響。
多級復制粘貼無異于雪上加霜
這里簡單探討的是企業通行的系統和基礎軟件建設實踐。一些國內外廠商和社區發布的定制化Linux發行版,本身是有其它發行版,如CentOS特定版本淵源的,在基礎軟件上即便同其上游發行版最新版本間也存在斷層滯后。RedHat相對于基礎軟件開發者之間已經隔了一層backport,而我們則人為制造了二級風險。
在很多基礎而關鍵的軟件上,企業系統基礎設施的維護者出于與RedHat類似的初衷,往往會決定自行backport一份拷貝;通過早年心臟滴血事件的洗禮,即暴露出來OpenSSL一個例子。無論是需要RHEL還沒來得及移植的新版本功能特性,還是出于對特殊使用上下文場景中更高執行效率的追求,企業都可能自行對RHEL上基礎軟件源碼包進行修改定制重打包。這個過程除了將風險冪次放大外,也進一步加深了代碼的不可解釋性(包括基礎軟件開發人員流動性帶來的不可解釋)。
Ⅳ. 從武功到死穴:從systemd-journald信息泄露一窺API誤用
1月10日凌晨兩點,漏洞預警平臺爬收取一封漏洞披露郵件。披露者是Qualys,那就鐵定是重型發布了。最后看披露漏洞的目標,systemd?這就非常有意思了。
一些必要背景
systemd是什么,不好簡單回答。Linux上面軟件命名,習慣以某軟件名后帶個‘d’表示后臺守護管理程序;所以systemd就可以說是整個系統的看守吧。而即便現在描述了systemd是什么,可能也很快會落伍,因為其初始及核心開發者Lennart Poettering(供職于Red Hat)描述它是“永無開發完結完整、始終跟進技術進展的、統一所有發行版無止境的差異”的一種底層軟件。籠統講有三個作用:中央化系統及設置管理;其它軟件開發的基礎框架;應用程序和系統內核之間的膠水。如今幾乎所有Linux發行版已經默認提供systemd,包括RHEL/CentOS 7及后續版本。總之很基礎、很底層、很重要就對了。systemd本體是個主要實現init系統的框架,但還有若干關鍵組件完成其它工作;這次被爆漏洞的是其journald組件,是負責系統事件日志記錄的看守程序。
額外地還想簡單提一句Qualys這個公司。該公司創立于1999年,官方介紹為信息安全與云安全解決方案企業,to B的安全業務非常全面,有些也是國內企業很少有布局的方面;例如上面提到的涉及碎片化和代碼移植過程的歷史漏洞移動,也在其漏洞管理解決方案中有所體現。但是我們對這家公司粗淺的了解來源于其安全研究團隊近幾年的發聲,這兩年間發布過的,包括有『stack clash』、『sudo get_tty_name提權』、『OpenSSH信息泄露與堆溢出』、『GHOST:glibc gethostbyname緩沖區溢出』等大新聞(僅截至2017年年中)。從中可見,這個研究團隊專門啃硬骨頭,而且還總能開拓出來新的啃食方式,往往爆出來一些別人沒想到的新漏洞類型。從這個角度,再聯想之前刷爆朋友圈的《安全研究者的自我修養》所倡導的“通過看歷史漏洞、看別人的最新成果去舉一反三”的理念,可見差距。
CVE-2018-16866漏洞詳情
這次漏洞披露,打包了三個漏洞:
- 16864和16865是內存破壞類型
- 16866是信息泄露;
- 而16865和16866兩個漏洞組和利用可以拿到root shell
漏洞分析已經在披露中寫的很詳細了,這里不復述;而針對16866的漏洞成因來龍去脈,Qualys跟蹤的結果留下了一點想象和反思空間,我們來看一下。
漏洞相關代碼片段是這樣的(漏洞修復前):

讀者可以先肉眼過一遍這段代碼有什么問題。實際上我一開始也沒看出來,向下讀才恍然大悟。
這段代碼中,外部信息輸入通過*buf傳入做記錄處理。輸入數據一般包含有空白字符間隔,需要分隔開逐個記錄,有效的分隔符包括空格、制表符、回車、換行,代碼中將其寫入常量字符串;在逐字符掃描輸入數據字符串時,將當前字符使用strchr在上述間隔符字符串中檢索是否匹配,以此判斷是否為間隔符;在240行,通過這樣的判斷,跳過記錄單元字符串的頭部連續空白字符。?但是問題在于,strchr這個極其基礎的字符串處理函數,對于C字符串終止字符’\0’的處理上有個坑:’\0’也被認為是被檢索字符串當中的一個有效字符。所以在240行,當當前掃描到的字符為字符串末尾的NULL時,strchr返回的是WHITESPACE常量字符串的終止位置而非NULL,這導致了越界。
看起來,這是一個典型的問題:API誤用(API mis-use),只不過這個被誤用的庫函數有點太基礎,讓我忍不住想是不是還會有大量的類似漏洞……當然也反思我自己寫的代碼是不是也有同樣情況,然而略一思考就釋然了——我那么笨的代碼都用for循環加if判斷了:)
漏洞引入和消除歷史
有意思的是,Qualys研究人員很貼心地替我做了一步漏洞成因溯源,這才是單獨提這個漏洞的原因。漏洞的引入是在2015年的一個commit中:

在GitHub中,定位到上述2015年的commit信息,這里commit的備注信息為:
journald: do not strip leading whitespace from messages.
Keep leading whitespace for compatibility with older syslog implementations. Also useful when piping formatted output to the?logger?command. Keep removing trailing whitespace.
OK,看起來是一個兼容性調整,對記錄信息不再跳過開頭所有連續空白字符,只不過用strchr的簡潔寫法比較突出開發者精煉的開發風格(并不),說得過去。
之后在2018年八月的一個當時尚未推正式版的另一次commit中被修復了,先是還原成了ec5ff4那次commit之前的寫法,然后改成了加校驗的方式:

雖然Qualys研究者認為上述的修改是“無心插柳”的改動,但是在GitHub可以看到,a6aadf這次commit是因為有外部用戶反饋了輸入數據為單個冒號情況下journald堆溢出崩潰的issue,才由開發者有目的性地修復的;而之后在859510這個commit再次改動回來,理由是待記錄的消息都是使用單個空格作為間隔符的,而上一個commit粗暴地去掉了這種協議兼容性特性。
如果沒有以上糾結的修改和改回歷史,也許我會傾向于懷疑,在最開始漏洞引入的那個commit,既然改動代碼沒有新增功能特性、沒有解決什么問題(畢竟其后三年,這個改動的代碼也沒有被反映issue),也并非出于代碼規范等考慮,那么這么輕描淡寫的一次提交,難免有人為蓄意引入漏洞的嫌疑。當然,看到幾次修復的原因,這種可能性就不大了,雖然大家仍可以保留意見。但是拋開是否人為這個因素,單純從代碼的漏洞成因看,一個傳統但躲不開的問題仍值得探討:API誤用。
API誤用:程序員何苦為難程序員
如果之前的章節給讀者留下了我反對代碼模塊化和復用的印象,那么這里需要正名一下,我們認可這是當下開發實踐不可避免的趨勢,也增進了社會開發速度。而API的設計決定了寫代碼和用代碼的雙方“舒適度”的問題,由此而來的API誤用問題,也是一直被當做單純的軟件工程課題討論。在此方面個人并沒有什么研究,自然也沒辦法系統地給出分類和學術方案,只是談一下自己的經驗和想法。
一篇比較新的學術文章總結了API誤用的研究,其中一個獨立章節專門分析Java密碼學組件API誤用的實際,當中引述之前論文認為,密碼學API是非常容易被誤用的,比如對期望輸入數據(數據類型,數據來源,編碼形式)要求的混淆,API的必需調用次序和依賴缺失(比如缺少或冗余多次調用了初始化函數、主動資源回收函數)等。湊巧在此方面我有一點體會:曾經因為業務方需要,需要使用C++對一個Java的密碼基礎中間件做移植。Java對密碼學組件支持,有原生的JDK模塊和權威的BouncyCastle包可用;而C/C++只能使用第三方庫,考慮到系統平臺最大兼容和最小代碼量,使用Linux平臺默認自帶的OpenSSL的密碼套件。但在開發過程中感受到了OpenSSL滿滿的惡意:其中的API設計不可謂不反人類,很多參數沒有明確的說明(比如同樣是表示長度的函數參數,可能在不同地方分別以字節/比特/分組數為計數單位);函數的線程安全沒有任何解釋標注,需要自行試驗;不清楚函數執行之后,是其自行做了資源釋放還是需要有另外API做gc,不知道資源釋放操作時是否規規矩矩地先擦除后釋放……此類問題不一而足,導致經過了漫長的測試之后,這份中間件才提供出來供使用。而在業務場景中,還會存在比如其它語言調用的情形,這些又暴露出來OpenSSL API誤用的一些完全無從參考的問題。這一切都成為了噩夢;當然這無法為我自己開解是個不稱職開發的指責,但僅就OpenSSL而言其API設計之惡劣也是始終被人詬病的問題,也是之后其他替代者宣稱改進的地方。
當然,問題是上下游都脫不了干系的。我們自己作為高速迭代中的開發人員,對于二方、三方提供的中間件、API,又有多少人能自信地說自己仔細、認真地閱讀過開發指南和API、規范說明呢?做過通用產品技術運營的朋友可能很容易理解,自己產品的直接用戶日常拋出不看文檔的愚蠢問題帶來的困擾。對于密碼學套件,這個問題還好辦一些,畢竟如果在沒有背景知識的情況下對API望文生義地一通調用,絕大多數情況下都會以拋異常形式告終;但還是有很多情況,API誤用埋下的是長期隱患。
不是所有API誤用情形最終都有機會發展成為可利用的安全漏洞,但作為一個由人的因素引入的風險,這將長期存在并困擾軟件供應鏈(雖然對安全研究者、黑客與白帽子是很欣慰的事情)。可惜,傳統的白盒代碼掃描能力,基于對代碼語義的理解和構建,但是涉及到API則需要預先的抽象,這一點目前似乎仍然是需要人工干預的事情;或者輕量級一點的方案,可以case by case地分析,為所有可能被誤用的API建模并單獨掃描,這自然也有很強局限性。在一個很底層可信的開發者還對C標準庫API存在誤用的現實內,我們需要更多的思考才能說接下來的解法。
Ⅴ. 從規則到陷阱:NASA JIRA誤配置致信息泄露血案

軟件的定義包括了代碼組成的程序,以及相關的配置、文檔等。當我們說軟件的漏洞、風險時,往往只聚焦在其中的代碼中;關于軟件供應鏈安全風險,我們的比賽、前面分析的例子也都聚焦在了代碼的問題;但是真正的威脅都來源于不可思議之處,那么代碼之外有沒有可能存在來源于上游的威脅呢?這里就借助實例來探討一下,在“配置”當中可能栽倒的坑。
引子:發不到500英里以外的郵件?
讓我們先從一個輕松愉快的小例子引入。這個例子初見于Linux中國的一篇譯文。
簡單說,作者描述了這么一個讓人啼笑皆非的問題:單位的郵件服務器發送郵件,發送目標距離本地500英里范圍之外的一律失敗,郵件就像悠悠球一樣只能飛出一定距離。這個問題本身讓描述者感到尷尬,就像一個技術人員被老板問到“為什么從家里筆記本上Ctrl-C后不能在公司臺式機上Ctrl-V”一樣。
經過令人窒息的分析操作后,筆者定位到了問題原因:筆者作為負責的系統管理員,把SunOS默認安裝的Senmail從老舊的版本5升級到了成熟的版本8,且對應于新版本諸多的新特性進行了對應配置,寫入配置文件sendmail.cf;但第三方服務顧問在對單位系統進行打補丁升級維護時,將系統軟件“升級”到了系統提供的最新版本,因此將Sendmail實際回退到了版本5,卻為了軟件行為一致性,原樣保留了高版本使用的配置文件。但Sendmail并沒有在大版本間保證配置文件兼容性,這導致很多版本5所需的配置項不存在于保留下來的sendmail.cf文件中,程序按默認值0處理;最終引起問題的就是,郵件服務器與接收端通信的超時時間配置項,當取默認配置值0時,郵件服務器在1個單位時間(約3毫秒)內沒有收到網絡回包即認為超時,而這3毫秒僅夠電信號打來回飛出500英里。
這個“故事”可能會給技術人員一點警醒,錯誤的配置會導致預期之外的軟件行為,但是配置如何會引入軟件供應鏈方向的安全風險呢?這就引出了下一個重磅實例。
JIRA配置錯誤致NASA敏感信息泄露案例
我們都聽過一個事情,馬云在帶隊考察美國公司期間問Google CEO Larry Page自視誰為競爭對手,Larry的回答是NASA,因為最優秀的工程師都被NASA的夢想吸引過去了。由此我們顯然能窺見NASA的技術水位之高,這樣的人才團隊大概至少是不會犯什么低級錯誤的。
但也許需要重新定義“低級錯誤”……1月11日一篇技術文章披露,NASA某官網部署使用的缺陷跟蹤管理系統JIRA存在錯誤的配置,可分別泄漏內部員工(JIRA系統用戶)的全部用戶名和郵件地址,以及內部項目和團隊名稱到公眾,如下:

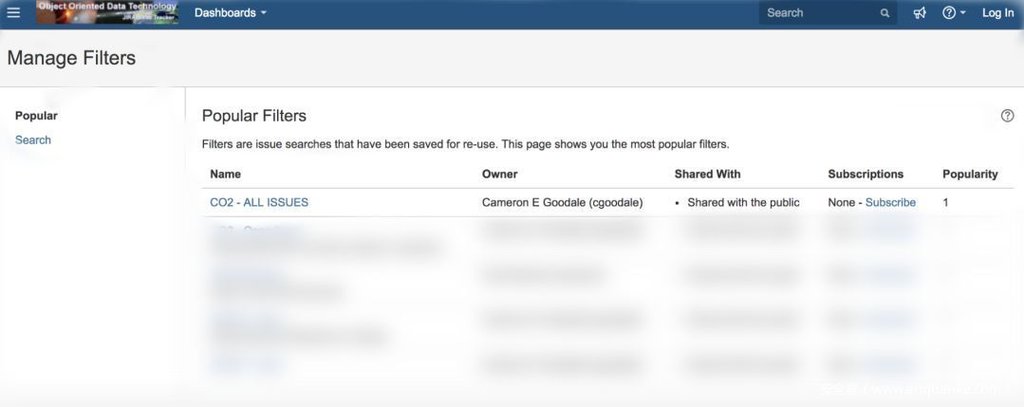
問題的原因解釋起來也非常簡單:JIRA系統的過濾器和配置面板中,對于數據可見性的配置選項分別選定為All users和Everyone時,系統管理人員想當然地認為這意味著將數據對所有“系統用戶”開放查看,但是JIRA的這兩個選項的真實效果逆天,是面向“任意人”開放,即不限于系統登錄用戶,而是任何查看頁面的人員。看到這里,我不厚道地笑了……“All users”并不意味著“All ‘users’”,意不意外,驚不驚喜?
但是這種字面上把戲,為什么沒有引起NASA工程師的注意呢,難道這樣逆天的配置項沒有在產品手冊文檔中加粗標紅提示嗎?本著為JIRA產品設計找回尊嚴的態度,我深入挖掘了一下官方說明,果然在Atlassian官方的一份confluence文檔(看起來更像是一份增補的FAQ)中找到了相關說明:
所有未登錄訪客訪問時,系統默認認定他們是匿名anonymous用戶,所以各種權限配置中的all users或anyone顯然應該將匿名用戶包括在內。在7.2及之后版本中,則提供了“所有登錄用戶”的選項。
可以說是非常嚴謹且貼心了。比較諷刺的是,在我們的軟件供應鏈安全大賽·C源代碼賽季期間,我們設計圈定的惡意代碼攻擊目標還包括JIRA相關的敏感信息的竊取,但是卻想不到有這么簡單方便的方式,不動一行代碼就可以從JIRA中偷走數據。
軟件的使用,你“配”嗎?
無論是開放的代碼還是成型的產品,我們在使用外部軟件的時候,都是處于軟件供應鏈下游的消費者角色,為了要充分理解上游開發和產品的真實細節意圖,需要我們付出多大的努力才夠“資格”?
上一章節我們討論過源碼使用中必要細節信息缺失造成的“API誤用”問題,而軟件配置上的“誤用”問題則復雜多樣得多。從可控程度上討論,至少有這幾種因素定義了這個問題:
- 軟件用戶對必要配置的現有文檔缺少了解。這是最簡單的場景,但又是完全不可避免的,這一點上我們所有有開發、產品或運營角色經驗的應該都曾經體會過向不管不顧用戶答疑的痛苦,而所有軟件使用者也可以反省一下對所有軟件的使用是否都以完整細致的文檔閱讀作為上手的準備工作,所以不必多說。
- 軟件擁有者對配置條目缺少必要明確說明文檔。就JIRA的例子而言,將NASA工程師歸為上一條錯誤有些冤枉,而將JIRA歸為這條更加合適。在邊角但重要問題上的說明通過社區而非官方文檔形式發布是一種不負責任的做法,但未引發安全事件的情況下還有多少這樣的問題被默默隱藏呢?我們沒辦法要求在使用軟件之前所有用戶將軟件相關所有文檔、社區問答實現全部覆蓋。這個問題范圍內一個代表性例子是對配置項的默認值以及對應效果的說明缺失。
- 配置文件版本兼容性帶來的誤配置和安全問題。實際上,上面的SunOS Sendmail案例足以點出這個問題的存在性,但是在真實場景下,很可能不會以這么戲劇性形式出現。在企業的系統運維中,系統的版本迭代常見,但為軟件行為一致性,配置的跨版本遷移是不可避免的操作;而且軟件的更新迭代也不只會由系統更新推動,還有大量出于業務性能要求而主動進行的定制化升級,對于中小企業基礎設施建設似乎是一個沒怎么被提及過的問題。
- 配置項組合沖突問題。盡管對于單個配置項可能明確行為與影響,但是特定的配置項搭配可能造成不可預知的效果。這完全有可能是由于開發者與用戶在信息不對等的情況下產生:開發者認為用戶應該具有必需的背景知識,做了用戶應當具備規避配置沖突能力的假設。一個例子是,對稱密碼算法在使用ECB、CBC分組工作模式時,從密碼算法上要求輸入數據長度必須是分組大小的整倍數,但如果用戶搭配配置了秘鑰對數據不做補齊(nopadding),則引入了非確定性行為:如果密碼算法庫對這種組合配置按某種默認補齊方式操作數據則會引起歧義,但如果在算法庫代碼層面對這種組合拋出錯誤則直接影響業務。
- 程序對配置項處理過程的潛在暗箱操作。這區別于簡單的未文檔化配置項行為,僅特指可能存在的蓄意、惡意行為。從某種意義上,上述“All users”也可以認為是這樣的一種陷阱,通過淺層次暗示,引導用戶做出錯誤且可能引起問題的配置。另一種情況是特定配置組合情況下觸發惡意代碼的行為,這種觸發條件將使惡意代碼具有規避檢測的能力,且在用戶基數上具有一定概率的用戶命中率。當然這種情況由官方開發者直接引入的可能性很低,但是在眾包開發的情況下如果存在,那么掃描方案是很難檢測的。
Ⅵ. 從逆流到暗流:惡意代碼溯源后的挑戰
如果說前面所說的種種威脅都是面向關鍵目標和核心系統應該思考的問題,那么最后要拋出一個會把所有人拉進賽場的理由。除了前面所有那些在軟件供應鏈下游被動污染受害的情況,還有一種情形:你有跡可循的代碼,也許在不經意間會“反哺”到黑色產業鏈甚至特殊武器中;而現在研究用于對程序進行分析和溯源的技術,則會讓你陷入百口莫辯的境地。
案例:黑產代碼模塊溯源疑云
1月29日,獵豹安全團隊發布技術分析通報文章《電信、百度客戶端源碼疑遭泄漏,驅魔家族竊取隱私再起波瀾》,矛頭直指黑產上游的惡意信息竊取代碼模塊,認定其代碼與兩方產品存在微妙的關聯:中國電信旗下“桌面3D動態天氣”等多款軟件,以及百度旗下“百度殺毒”等軟件(已不可訪問)。
文章中舉證有三個關鍵點。
首先最直觀的,是三者使用了相同的特征字符串、私有文件路徑、自定義內部數據字段格式;
其次,在關鍵代碼位置,三者在二進制程序匯編代碼層面具有高度相似性;
最終,在一定范圍的非通用程序邏輯上,三者在經過反匯編后的代碼語義上顯示出明顯的雷同,并提供了如下兩圖佐證(圖片來源:http://bbs.duba.net/thread-23531362-1-1.html):

文章指出的涉事相關軟件已經下線,對于上述樣本文件的相似度試驗暫不做復現,且無法求證存在相似、疑似同源的代碼在三者中占比數據。對于上述指出的代碼雷同現象,獵豹安全團隊認為:
我們懷疑該病毒模塊的作者通過某種渠道(比如“曾經就職”),掌握有中國電信旗下部分客戶端/服務端源碼,并加以改造用于制作竊取用戶隱私的病毒,另外在該病毒模塊的代碼中,我們還發現“百度”旗下部分客戶端的基礎調試日志函數庫代碼痕跡,整個“驅魔”病毒家族疑點重重,其制作傳播背景愈發撲朔迷離。
這樣的推斷,固然有過于直接的依據(例如三款代碼中均使用含有“baidu”字樣的特征注冊表項);但更進一步地,需要注意到,三個樣本在所指出的代碼位置,具有直觀可見的二進制匯編代碼結構的相同,考慮到如果僅僅是惡意代碼開發者先逆向另外兩份代碼后借鑒了代碼邏輯,那么在面臨反編譯、代碼上下文適配重構、跨編譯器和選項的編譯結果差異等諸多不確定環節,仍能保持二進制代碼的雷同,似乎確實是只有從根本上的源代碼泄漏(抄襲)且保持相同的開發編譯環境才能成立。
但是我們卻又無法做出更明確的推斷。這一方面當然是出于嚴謹避免過度解讀;而從另一方面考慮,黑產代碼的一個關鍵出發點就是“隱藏自己”,而這里居然如此堂而皇之地照搬了代碼,不但沒有進行任何代碼混淆、變形,甚至沒有抹除疑似來源的關鍵字符串,如果將黑產視為智商在線的對手,那這里背后是否有其它考量,就值得琢磨了。
代碼的比對、分析、溯源技術水準
上文中的安全團隊基于大量樣本和粗粒度比對方法,給出了一個初步的判斷和疑點。那么是否有可能獲得更確鑿的分析結果,來證實或證偽同源猜想呢?
無論是源代碼還是二進制,代碼比對技術作為一種基礎手段,在軟件供應鏈安全分析上都注定仍然有效。在我們的軟件供應鏈安全大賽期間,針對PE二進制程序類型的題目,參賽隊伍就紛紛采用了相關技術手段用于目標分析,包括:同源性分析,用于判定與目標軟件相似度最高的同軟件官方版本;細粒度的差異分析,用于嘗試在忽略編譯差異和特意引入的混淆之外,定位特意引入的惡意代碼位置。當然,作為比賽中針對性的應對方案,受目標和環境引導約束,這些方法證明了可行性,卻難以保證集成有最新技術方案。那么做一下預言,在不計入情報輔助條件下,下一代的代碼比對將能夠到達什么水準?
這里結合近一年和今年內,已發表和未發表的學術領域頂級會議的相關文章來簡單展望:
- 針對海量甚至全量已知源碼,將可以實現準確精細化的“作者歸屬”判定。在ACM CCS‘18會議上曾發表的一篇文章《Large-Scale and Language-Oblivious Code Authorship Identification》,描述了使用RNN進行大規模代碼識別的方案,在圈定目標開發者,并預先提供每個開發者的5-7份已知的代碼文件后,該技術方案可以很有效地識別大規模匿名代碼倉庫中隸屬于每個開發者的代碼:針對1600個Google Code Jam開發者8年間的所有代碼可以實現96%的成功識別率,而針對745個C代碼開發者于1987年之后在GitHub上面的全部公開代碼倉庫,識別率也高達94.38%。這樣的結果在當下的場景中,已經足以實現對特定人的代碼識別和跟蹤(例如,考慮到特定開發人員可能由于編碼習慣和規范意識,在時間和項目跨度上犯同樣的錯誤);可以預見,在該技術方向上,完全可以期望擺脫特定已知目標人的現有數據集學習的過程,并實現更細粒度的歸屬分析,例如代碼段、代碼行、提交歷史。
- 針對二進制代碼,更準確、更大規模、更快速的代碼主程序分析和同源性匹配。近年來作為一項程序分析基礎技術研究,二進制代碼相似性分析又重新獲得了學術界和工業界的關注。在2018年和2019(已錄用)的安全領域四大頂級會議上,每次都會有該方向最新成果的展示,如S&P‘2019上錄用的《Asm2Vec: Boosting Static Representation Robustness for Binary Clone Search against Code Obfuscation and Compiler Optimization》,實現無先驗知識的條件下的最優匯編代碼級別克隆檢測,針對漏洞庫的漏洞代碼檢測可實現0誤報、100%召回。而2018年北京HITB會議上,Google Project Zero成員、二進制比對工具BinDiff原始作者Thomas Dullien,探討了他借用改造Google自家SimHash算法思想,用于針對二進制代碼控制流圖做相似性檢測的嘗試和階段結果;這種引入規模數據處理的思路,也可期望能夠在目前其他技術方案大多精細化而低效的情況下,為高效、快速、大規模甚至全量代碼克隆檢測勾出未來方案。
- 代碼比對方案對編輯、優化、變形、混淆的對抗。近年所有技術方案都以對代碼“變種”的檢測有效性作為關鍵衡量標準,并一定程度上予以保證。上文CCS‘18論文工作,針對典型源代碼混淆(如Tigress)處理后的代碼,大規模數據集上可有93.42%的準確識別率;S&P‘19論文針對跨編譯器和編譯選項、業界常用的OLLVM編譯時混淆方案進行試驗,在全部可用的混淆方案保護之下的代碼仍然可以完成81%以上的克隆檢測。值得注意的是以上方案都并非針對特定混淆方案單獨優化的,方法具有通用價值;而除此以外還有很多針對性的的反混淆研究成果可用;因此,可以認為在采用常規商用代碼混淆方案下,即便存在隱藏內部業務邏輯不被逆向的能力,但仍然可以被有效定位代碼復用和開發者自然人。
代碼溯源技術面前的“挑戰”
作為軟件供應鏈安全的獨立分析方,健壯的代碼比對技術是決定性的基石;而當腦洞大開,考慮到行業的發展,也許以下兩種假設的情景,將把每一個“正當”的產品、開發者置于尷尬的境地。
代碼仿制
在本章節引述的“驅魔家族”代碼疑云案例中,黑產方面通過某種方式獲得了正常代碼中,功能邏輯可以被自身復用的片段,并以某種方法將其在保持原樣的情況下拼接形成了惡意程序。即便在此例中并非如此,但這卻暴露了隱憂:將來是不是有這種可能,我的正常代碼被泄漏或逆向后出現在惡意軟件中,被溯源后扣上黑鍋?
這種擔憂可能以多種渠道和形式成為現實。
從上游看,內部源碼被人為泄漏是最簡單的形式(實際上,考慮到代碼的完整生命周期似乎并沒有作為企業核心數據資產得到保護,目前實質上有沒有這樣的代碼在野泄漏還是個未知數),而通過程序逆向還原代碼邏輯也在一定程度上可獲取原始代碼關鍵特征。
從下游看,則可能有多種方式將惡意代碼偽造得像正常代碼并實現“碰瓷”。最簡單地,可以大量復用關鍵代碼特征(如字符串,自定義數據結構,關鍵分支條件,數據記錄和交換私有格式等)。考慮到在進行溯源時,分析者實際上不需要100%的匹配度才會懷疑,因此僅僅是仿造原始程序對于第三方公開庫代碼的特殊定制改動,也足以將公眾的疑點轉移。而近年來類似自動補丁代碼搜索生成的方案也可能被用來在一份最終代碼中包含有二方甚至多方原始代碼的特征和片段。
基于開發者溯源的定點滲透
既然在未來可能存在準確將代碼與自然人對應的技術,那么這種技術也完全可能被黑色產業利用。可能的憂患包括強針對性的社會工程,結合特定開發者歷史代碼缺陷的漏洞挖掘利用,聯動第三方泄漏人員信息的深層滲透,等等。這方面暫不做聯想展開。
〇. 沒有總結
作為一場旨在定義“軟件供應鏈安全”威脅的宣言,阿里安全“功守道”大賽將在后續給出詳細的分解和總結,其意義價值也許會在一段時間之后才能被挖掘。
但是威脅的現狀不容樂觀,威脅的發展不會靜待;這一篇隨筆僅僅挑選六個側面做摘錄分析,可即將到來的趨勢一定只會進入更加發散的境地,因此這里,沒有總結。