

機器學習在數據安全感知系統的應用
責編:gltian |2022-04-06 13:37:41我們生活在一個信息泛濫的世界,越來越難去跟蹤信息,或者手動為他人策劃信息;幸運的是,現代數據科學可以對大量的信息進行分類,并將與我們相關的信息呈現出來。
機器學習算法依靠在數據中觀察到的用戶知識和模式,對我們可能喜歡或感興趣的內容做出推斷和建議。隨著機器學習技術越來越容易被開發人員使用,有一股力量促使公司利用這些算法來改進他們的產品和用戶的體驗。
在全息網御研發實踐中,我們以安全視角深入分析流動數據在各個行業的業務共性,抽象出以流動數據為核心的OnFire數據安全風險感知系統平臺,通過結合運用AI智能機器學習,實時構建“ 用戶-設備-應用-數據 ”四個維度的關聯分析,實現了為流動數據建立評估監測、預警/告警、溯源審計的聯動機制提供依據,從而感知數據安全風險,并形成可視、可控、可追溯的數字空間安全態勢感知和防護體系。
用戶和實體行為的分析方法(User and Entity Behavior Analysis, UEBA)是基于實體行為的網絡風險分析,是利用統計和機器學習等算法的自適應分析,是基于大數據安全分析的網絡異常行為檢測與安全態勢感知 。以下我們從算法和架構兩個方面描述這些算法在OnFire系統中的應用。
一、概述
OnFire系統是由三部分組成:網絡流量采集系統(HoloFlow),實體行為分析系統(HoloML)和管理系統(HoloVision)。網絡流量采集器會從網絡關鍵設備節點,通常從匯聚交換機處,接受并處理網絡原始流量,生成網絡中設備、應用、數據(文件和網頁)以及用戶的網絡行為日志,并保存于數據倉庫。
分析平臺將這些日志映射為四類實體行為,分別是:用戶實體、設備實體、應用實體和數據實體。然后根據實體間的行為邏輯關系、時序關系以及地理位置關系等,生成動態關聯的網絡全息圖。同時,利用數理統計、機器學習等算法為每個實體畫像構建正常行為基線。最后再通過實體的正常行為畫像識別比對出異常行為,并提醒管理員及時對異常行為追蹤溯源。
OnFire系統的層級結構共分為5層,如圖-1:

日志收集層:收集多種網絡協議數據,支持第三方日志信息的導入。
匯聚層:完成數據清洗,數據轉換,數據聚合工作,并提取用戶、設備、應用和數據實體信息。
畫像層:根據實體的歷史信息,利用數理統計、機器學習等算法為每個實體畫像,建立正常行為基線,并將其可視化展現。
異常行為檢測層:計算實體每個行為與正常行為畫像的差別,從而識別異常行為,并將其可視化展示。
展示層:為安全系統分析員提供友好、可用的人機接口,便于事后的追蹤溯源。
二、實體行為分析
1. 行為畫像
在畫像層中,我們按用戶、數據、應用和設備四個維度分析和挖掘實體行為以掌握實體間的相互關系,識別出正常行為模式并建立實體間的正常行為基線,運用到的是無監督的機器學習算法。在隨后的檢測層中,系統將計算正常行為基線與當前行為之間的差異,從而判斷此行為是否異常。
通常,特征工程(feature engineering)會從實體行為中提取特征,將這些特征作為學習算法的輸入來識別實體行為的模式。平臺使用多種算法來識別正常行為的模式,下面簡要介紹兩種:
(1)核密度估算
核密度估計(Kernel Density Estimation)為實體行為特征構建密度的估算函數。在我們的UEBA解決方案中,我們使用非參數密度估計算法(nonparametric estimation),因為這不需要那么嚴格的假設條件,而核密度估算是常用方法之一。
在計算數據密度分布估算函數時,算法使用高斯核來創建數據的直方圖,而不是用矩形對數據進行分箱。也就是說在每個分箱的中心繪制高斯分布,這種方法可以平滑直方圖,并得到對特征空間中每個點的數據密度的連續估計。對于異常檢測通常方法是估算每個數據點的密度,并將密度最小點稱之為異常。
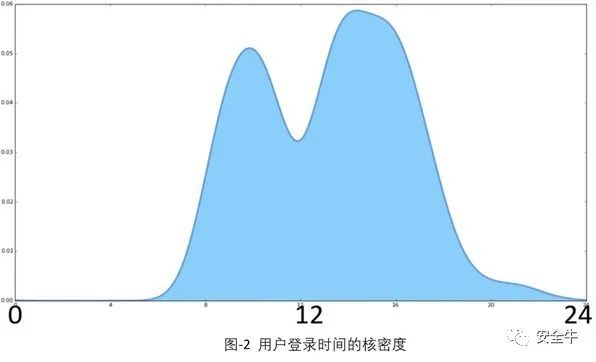
如圖-2顯示一天中的登錄行為:X軸是時間,y軸是登錄概率,從該圖可以看出高密度時段為6到20。如果有人在0到6之間登錄,則表現為行為異常。
(2)特征工程
在OnFire系統中,大多數活動是時間依賴性的。對于時序數據,我們從三個方向提取數據特征:時間、統計和頻譜。時間類特征包括:不同的時間粒度、自相關性、離峰值距離、正負轉向點等。統計類特征包括:移動均值、標準差、趨勢量度、季節性、周期性、序列相關性、偏度、峰度和自相似性等。頻譜類特征包括:FFT平均系數、 最大頻率、中位數頻率、頻譜中心以及頻譜延展度等。
2. 行為異常分析
OnFire 系統的行為異常分析包括兩類:基于靜態規則以及基于統計和機器學習算法,下面將重點對系統使用的統計類算法和機器學習類算法進行介紹。
(1)統計類算法
統計類算法常用于一維或二維的數據,計算成本低,無需人工設置門限。適用于對重要指標的行為異常報警。比如用戶的商業文件下載量,服務器文件下載量等。
指數加權移動平均法 (EWMA) 是一種常用統計方法,對用戶和實體行為的某個維度數據,對其每天的聚合值分別給予不同的權數,按不同權數求得移動平均值,并以最后的移動平均值為基礎,確定預測值的方法 。在EWMA中,各數值的加權系數隨時間呈指數式遞減,越靠近當前時刻的數值加權系數就越大。
EWMA 的表達式如下:
(1)〖EWMA〗_t= 〖λY〗_t+ (1-λ)EWMA_(t-1)? ? ? for t=1,2,…,n
(2)? s_ewma^2=? λ/(2-λ) s^2
(3)? UCL=〖EWMA〗_0+〖ks〗_ewma
其中:
〖EWMA〗_t :為t時的指數加權移動平均值。
Y_t:t時刻的實際數據。
k, λ 均為常量,其中0<λ≤1 決定歷史數據對當前數據影響程度。
s:EWMA 統計值的方差
UCL:控制圖的上限值
在實體行為分析系統中,指數加權移動平均法被用于單一維度的行為數據異常檢測。比如用戶每天下載文件量,根據工作性質不同,會有較平穩的基線和浮動區間。如果某天下載量遠遠大于UCL,則可視為下載文件行為異常。
(2)機器學習類算法
實體行為分析系統使用孤獨森林算法(iForest)和聚類算法(Clustering Algorithm)實現用戶組內外的行為異常分析。從而可以完成賬號失陷分析和主機失陷分析功能。其基于的假設:同組用戶的行為方式具有更高相似性。其實現原理:通過比較管理員提供的用戶群組信息,并基于聚類分析模塊依據用戶行為數據計算出的群組信息,從而找出那些偏離群組的用戶。
針對管理員輸入個群組個數不同,聚類分析系統選擇使用異常檢測算法或者聚類算法。如果管理員輸入一個群組,那么系統選擇異常檢測算法,計算離群用戶。如果管理員輸入兩個或兩個以上群組,系統將使用聚類算法對用戶進行分組(群組數等于管理員輸入的群組數);然后將計算得到的群組關系與管理員輸入的群組關系進行對比,從而得到離群用戶。
① 數據
用戶網絡行為信息以天為計算單位,根據全息的特殊能力,這里的用戶包括了同一個用戶使用的所有設備,所有應用及所有文件/數據的綜合信息,而不是僅根據一個用戶的某一個應用或用戶的某一臺設備所收集的信息。
A. 全局網絡流量信息
a)用戶訪問網絡的流量
b)用戶訪問應用個數
B.內部服務應用信息
a)用戶訪問某個應用服務的流量數
b)用戶訪問某個應用服務的網頁數
C.文件類型及敏感類型信息
a)對于所有文件類型,用戶使用的每種類型的文件個數
b)對于所有文件敏感類型,用戶使用每種敏感類型的文件個數
②異常檢測算法
當管理員選擇一個群組或網段時,使用異常檢測算法計算出離群行為,目前應用孤獨森林算法。
孤獨森林算法適用于發現分布稀疏且離密度高的群體較遠的離群點。在特征空間里,分布稀疏的區域表示事件發生在該區域的概率很低,因而可以認為落在這些區域里的數據是異常的。
③聚類算法
當管理員選擇N(N>=2)個的群組或網段時,根據用戶行為數據使用聚類算法計算出N個新的群組。目前應用了K-Mean,分層聚類,混合高斯算法,系統默認選擇K-Mean算法。
④群組關系比較算法
將聚類算法計算出的群組關系,與管理員選擇的群組關系進行對比,從而得到哪些用戶的行為偏離原來的群組關系。

實體行為分析系統(HoloML系統)采用Event-Driven架構,如圖-3所示。管理員通過HoloVision創建并管理分析任務。HoloML接受來自HoloVision的分析請求事件,啟動智能分析任務,并將分析結果保存在數據倉庫里。在通過Pub/Sub通道通知HoloVision任務執行情況,HoloVision讀取數據倉庫中的分析結果,并展現給管理員。