

如何實現機器學習模型的敏感數據遺忘?
責編:gltian |2023-07-24 14:19:24一.??概述
隨著機器學習方法越來越多地應用于網絡安全領域的數據分析中,如果模型無意中從訓練數據中捕獲了敏感信息,則在一定程度上存在隱私泄露的風險。由于訓練數據會長期存在于模型參數中,如果向模型輸入一些具有誘導性質的數據,則有可能直接輸出訓練樣本[1]。同時,當敏感數據意外進入模型訓練,從數據保護的角度出發,如何使模型遺忘這些敏感數據或特征并保證模型效果成了亟待解決的問題。
本文介紹了一種基于模型參數的封閉式更新來實現數據遺忘的方法,這一工作來自2023年Network and Distributed System Security (NDSS) Symposium的一篇論文[3],無論模型的損失函數是否為凸函數,這一方法均可以實現顯著的特征和標簽數據遺忘的效果。
二.? 常見的模型數據遺忘方法
目前常用的機器學習數據遺忘方法包括以下幾種:可以在刪除數據后重新訓練,這一方法要求保留原始數據且從頭訓練較為昂貴。當需要改動的數據并非獨立存在,或者存在大量數據需要被脫敏時,通過刪除數據來重新訓練模型的方法難度也較大。另有研究通過部分逆轉機器學習的學習過程[2],并在此過程中刪除已學習的數據點,從而滿足減少隱私泄露的需求。然而這一方法的計算效率通常較低,且對模型準確性產生一定的影響,所以在實際操作時可行性較低。
此外,研究人員也提出了分片法,通過將數據分割成獨立的分區,基于每個分區訓練子模型并聚合成最終模型。在分片法中,可以通過僅重新訓練受影響的子模型來實現數據點的遺忘,同時其余子模型保持不變。這一方法的缺點在于,當需要改變多個數據點時,重新訓練的效率會迅速下降,隨著需要刪除的數據點數量增加,所有子模型需要被重新訓練的概率也顯著提高。例如,當分片數量為20時,移除150個數據點就需要對所有分片進行更新,即隨著受影響數據點的數據增加,分片法相對于再訓練的運行效率優勢逐漸消失。其次,相對于移除受影響的特征和標簽而言,移除整個數據點會降低再訓練模型的性能。
三.??設計思路
為了解決這一問題,本文介紹的方法從解決特征和標簽中隱私問題的角度出發,將移除數據點轉化為模型的封閉式參數更新,從而實現在訓練數據中的任意位置校正特征和標簽,如圖1所示。
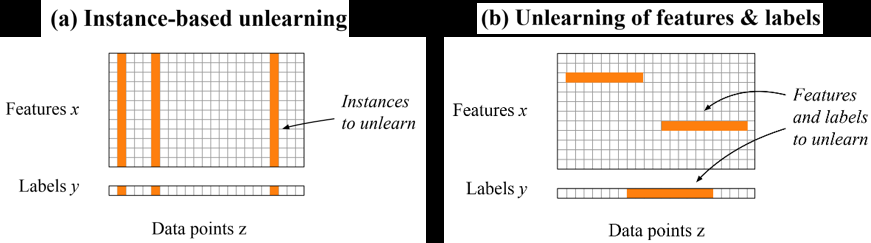
當隱私問題涉及多個數據點,但僅限于特定的特征和標簽時,使用這一方法比刪除數據點更加有效。此外,該方法具有較高的靈活性,不僅可以用于修改特征和標簽,也可以用于刪除數據點替代現有方法。
該方法是基于影響函數(influence function)進行模型參數更新的,這一函數應用廣泛,可以用來衡量樣本對模型參數的影響程度,即描述樣本的重要性。使用影響函數可以在不改變模型的情況下,獲得與原模型相似性的度量結果。
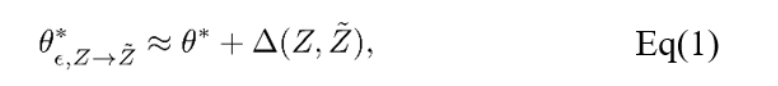
常用的對數據點或者特征的修改包括:數據點的修改、特征的修改和特征的刪除。其中,特征的刪除會改變模型輸入的維數。由于對于一大類機器學習模型而言,將需要刪除的特征的值設置為零并再次訓練,和將特征刪除的訓練結果是等價的,因此該方法選擇將特征的刪除改為將其值設置為零。該方法實現了兩種更新的方式:一階更新和二階更新。思路是尋找到能夠疊加到新模型用于數據遺忘的更新。第一種方式是基于損失函數的梯度,因此可以被應用于任何損失可導的模型,其中τ為遺忘速率。
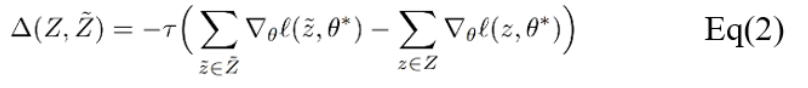
第二種方式包含二階導數,因此限制了這一方式只能應用于具有可逆Hessian矩陣的損失函數。從技術上講,在常見的機器學習模型中應用二階導數更新十分簡單,但對于大型模型來說,逆Hessian矩陣通常較難計算。
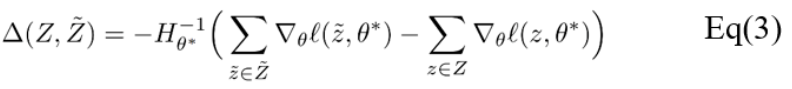
對于具有少量參數的模型,可以預先計算逆Hessian矩陣并存儲,隨后每次進行數據遺忘操作僅僅涉及簡單的矩陣向量乘法,因此計算效率非常高。例如在測試中,已證明從具有大約2000個參數的線性模型中去除特征可以在一秒鐘內完成。對于深度神經網絡這類復雜模型而言,由于Hessian矩陣較大難以存儲,因此可以使用近似逆Hessian矩陣替代。在測試結果中,對具有330萬參數的遞歸神經網絡進行二階更新,所需時間不到30秒。
四.? 樣例展示
對于測試的實例,這一工作均以三個指標來對本文提出的方法進行效果分析:(1)數據遺忘的效果,(2)保證模型的質量,(3)比重新訓練效率更高。為了將該方法與已有的機器學習模型的數據遺忘方法進行比較,本工作選取再訓練、分片等方法作為基線。
4.1
敏感特征遺忘
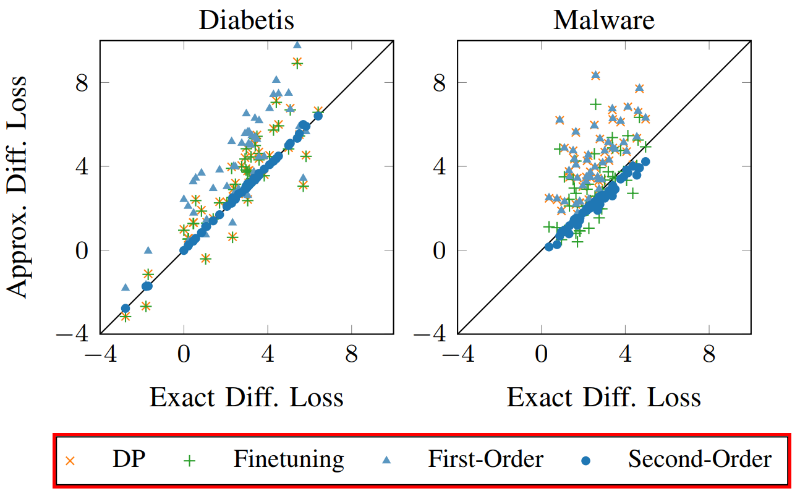
該方法首先應用于在真實數據集上訓練的邏輯回歸模型,包括垃圾郵件過濾、Android惡意軟件檢測、糖尿病預測等。對于特征維度較多的數據集,比如電子郵件和Android應用數據集,該方法分別選取與個人姓名相關的維度和Android應用中提取的URL作為敏感特征,并從模型中移除整個特征維度。對于特征維度較少的數據集,該方法選擇替換選定的特征值,例如對于糖尿病數據集,可以對個體的年齡、體重指數和性別等特征值進行調整,而非直接刪除。圖2中展示了分別移除或替換100個特征時糖尿病和惡意軟件數據集的效果。我們觀察到,二階更新非常接近再訓練,因為這些點靠近對角線。相比之下,其他方法不能總是適應分布的變化,從而導致更大的差異。
4.2
無意識記憶的遺忘
已有研究展示部分語言學習模型能夠形成對訓練數據中稀有輸入的記憶,并在應用過程中準確地展示這些輸入數據[4]。如果這類無意識記憶中包含隱私等敏感信息,則存在隱私泄露問題。由于語言模型為非凸損失函數,無法從理論上驗證數據遺忘效果。此外,因為模型優化的過程存在不確定性且可能陷入局部最小值,所有難以與重新訓練的模型進行比較。基于以上限制,這一工作選擇使用暴露度量(exposure matric)來評估數據遺忘的效果。
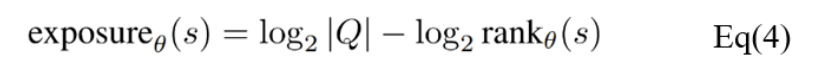
其中s是一個序列,Q是給定字母表的情況下,具有相同長度的可能序列的集合。暴露度量能夠描述序列s相對于由模型生成的相同長度的所有可能序列的可能性。如表1所示,對于所有序列長度,一階和二階更新方法的暴露值均接近0,即不可能提取出敏感序列。

五.? 結論
通過在不同場景下應用這一數據遺忘方法,證明了該策略具有高效準確的優勢。對于損失函數為凸函數的邏輯回歸和支持向量機等,可以從理論上保證從模型中移除特征和標簽。經過在實際操作中的驗證,該方法與其他數據遺忘的方法相比,具有更高的效率和相似的準確度,且只需要一小部分的訓練數據,適用于原始數據不可用的情況。
與此同時,這一工作中的數據遺忘方法的效率隨著受影響特征和標簽的數量增加而降低,目前可以有效地處理數百個敏感特征和數千個標簽的隱私泄露問題,但是較難在數百萬個數據點上實現,具有一定的局限性。此外,對于深度學習的神經網絡等損失函數并非凸函數的模型而言,該方法無法從理論上保證在非凸損失函數的模型中實現數據遺忘功能,但可以通過其他方式對數據遺忘的功效進行度量。應用于生成式語言模型時,能夠在保留模型功能的基礎上消除無意識的記憶,從而避免敏感數據泄露的問題。
參考文獻
[1]?X. Ling?et al., Extracting Training Data from Large Language Models, in USENIX Security Symposium, 2021.
[2] L.Bourtoule et al., “Machine unlearning”, in IEEE Symposium on Security and Privacy (S&P), 2021.
[3] Alexander Warnecke et al., “Machine Unlearning of Features and Labels”, in NDSS 2023.
[4] N. Carlini et al., “The secret sharer: Evaluating and testing unintended memorization in neural networks,” in USENIX Security Symposium, 2019, pp. 267–284