

主流大語言模型集體曝出訓練數據泄露漏洞
責編:gltian |2023-12-05 16:12:52近日,安全研究人員發布的一篇論文給“百模大戰”的生成式人工智能開發熱潮澆了一盆冷水。研究發現,黑客可利用新的數據提取攻擊方法從當今主流的大語言模型(包括開源和封閉,對齊和未對齊模型)中大規模提取訓練數據。
論文指出,當前絕大多數大語言模型的記憶(訓練數據)可被恢復,無論該模型是否進行了所謂的“對齊”。黑客可以通過查詢模型來有效提取訓練數據,甚至無需事先了解訓練數據集。
研究者展示了如何從Pythia或GPT-Neo等開源語言模型、LLaMA或Falcon等主流半開放模型以及ChatGPT等封閉模型中提取數以GB計的訓練數據。
研究者指出,已有技術足以攻擊未對齊的模型,對于已經對齊的ChatGPT,研究者開發了一種新的發散數據提取攻擊,該攻擊會導致大語言模型改變聊天機器人的內容生成方式,以比正常行為高150倍的速率瘋狂輸出訓練數據(下圖):

圖1:發散攻擊導致對齊后的chatGPT以150倍的速度輸出訓練數據
研究者表示:發散數據提取攻擊方法在實際攻擊中可恢復的訓練數據大大超出了事前的預期,同時也證明當前的大語言模型對齊技術并不能真正消除記憶。

研究者利用偏差攻擊提取訓練數據中的隱私信息
據研究者介紹,大型語言模型(LLMs)會從其訓練數據集中記憶樣本,可被攻擊者利用提取隱私信息(上圖)。先前的安全研究工作已經對開源模型記憶的訓練數據總量進行了大規模研究,并且通過手動標注示記憶和非記憶樣本,開發并驗證了針對(相對)小型模型如GPT-2的訓練數據提取攻擊。
在最新發布的論文中,研究者將“成員推斷攻擊”(用于確定數據樣本是否訓練數據)和數據提取攻擊兩種方法統一起來,對語言模型中的“可提取記憶”進行了大規模研究。
研究者開發了一種可擴展方法,通過與TB級數據集比對,檢測模型輸出的數萬億個token的記憶內容,并對流行的開源模型(例如Pythia,GPT-Neo)和半開源模型(例如LLaMA,Falcon)進行了分析。研究者發現,無論開源還是閉源的大語言模型都無法避免新的數據提取攻擊,而且參數和Tokens規模更大、性能更強勁的模型更容易受到數據提取攻擊:

九個開源大語言模型測試結果
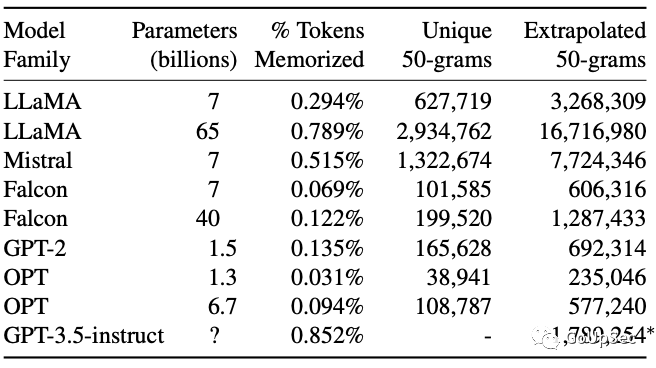
九個半開源(訓練算法和訓練數據不公開)大語言模型的測試結果
研究者發現,“對齊模型”也不能避免新的數據提取攻擊。例如,gpt-3.5-turbo對常規數據提取攻擊免疫,看上去似乎成功“忘記了”訓練數據。研究者推測是因為ChatGPT已經通過RLHF進行了對齊,目的是使其成為“安全高效”的,可推向市場(生產環境)的個人聊天助手。
但研究者開發了新的提示策略(僅適用于GPT3.5turbo),成功繞過了gpt-3.5-turbo的對齊技術,使其“偏離”預設的聊天機器人風格,表現得像一個基礎語言模型,以典型的web文本格式大量輸出文本。
為了檢查這些輸出的文本是否是此前從互聯網上采集的訓練數據,研究者將幾個公開可用的大型網絡訓練數據集合并成一個9TB大小的數據集。通過與這個數據集匹配,研究者以200美元的查詢成本從ChatGPT對話中恢復了一萬多個訓練數據集樣本。研究者粗略估計,通過更多的查詢可以提取超過10倍的(訓練)數據。
研究者在論文中透露,在7月11日發現該漏洞后,通知了包括OPT、Falcon、Mistral和LLaMA等模型開發者,并在8月30日向OpenAI披露了其漏洞,并根據90天漏洞披露規則,于11月30日發布論文,希望能喚起業界對大語言模型數據安全和對齊挑戰的關注。
最后,研究者警告大語言模型應用開發者,滲透測試結果表明現有的大語言模型安全措施(模型對齊和內容記憶測試)難以發現大語言模型的隱私漏洞,更不用說那些隱藏在模型算法代碼中的“休眠漏洞”。如果沒有極端的安全措施,現階段不應訓練和部署涉及隱私和敏感信息的大模型應用(編者:例如醫療、法律、工程)。
論文鏈接:
https://arxiv.org/abs/2311.17035
來源:GoUpSec