

簡析全球AI監管的現狀、影響與未來展望
責編:gltian |2024-04-24 15:29:21AI是一個經常與機器學習(ML)或大型語言模型(LLM)等術語混淆的寬泛術語。圍繞著新興AI技術及其影響的潛力和興奮中,行業領導者、政府組織和企業正在討論監管干預措施,例如《歐盟人工智能法案》、美國紐約州AI法(限制使用自動化就業決策工具)以及全球正在制定的其他30余項AI相關提案。目前亟需制定相關法規,解決生成的數據的使用、濫用和道德挑戰。法規的實施將對教育、數據隱私、生命科學和研究等各個領域產生深遠影響。
對AI影響力的分析揭示了強調法規、法案和法律影響的關鍵主題。分析目標是通過對比現狀與預期的未來,從而評估對有影響力的法規的必要性,并提高對法規如何積極改善AI領域的普遍認識。
全球監管干預的類型
目前,我國、歐盟、英國和美國各自制定了監管要求,以應對不斷變化的AI環境。最近,《歐盟人工智能法案》為風險管理框架的發展進一步奠定了基礎。而中國采取了不同的方式,采納了三種不同的監管措施,分別符合國家、地區和地方的觀點,其中最新的深度合成規定于2023年正式生效。盡管其他國家也曾嘗試制定和實施不同的監管規定,但許多國家并未能跟上ML和AI工具及算法發展的步伐。
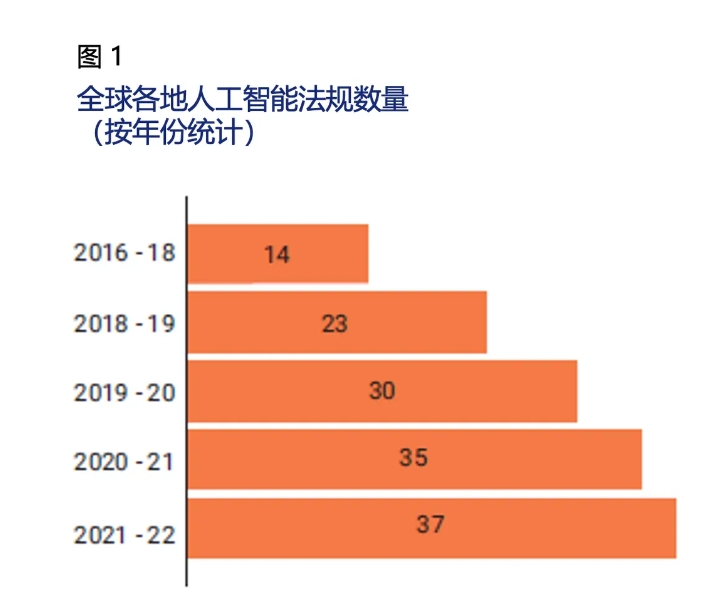
圖1描繪了包含“人工智能”字樣的法律法規年度增長情況。在過去幾年中,127個國家的立法機構通過了37項涉及AI的法律,突顯出AI在監管討論中的重要性。
世界各國包括加拿大、中國、西班牙、英國和美國,已起草了針對AI相關的法案,頒布了AI法案或者通過了AI法規,以期解決在這一快速發展的知識領域中出現的道德問題(例如,數據偏差、特定地區或國家的數據來源)。其中一些地區采取行業方式監管AI(即專門針對數據隱私或特定內容),而其他地區,如中國和美國,在實施法律時側重于多個領域(如透明度、偏見和數據保護)。從理解AI和ML模型及算法的工作原理開始,起草這些法規還有改進空間。
了解AI和ML模型

基于算法的AI和ML模型依賴于多種輸入,其中主要輸入是數據。數據用于已知的AI和ML模型生成訓練數據集,以得出某一特定結果或效果。大多數模型解釋數據,并就解決與特定問題相關的問題提供建議。圖2描繪了開發AI模型的步驟。
深度神經網絡、邏輯回歸和線性回歸、決策樹、K近鄰算法(k-Nearest Neighbor,KNN)、隨機森林(Random Forest)和樸素貝葉斯(Naive Bayes)是當前流行的一些算法模型。這些模型通常按照它們可以在企業中或通過系統應用的位置進行分類。
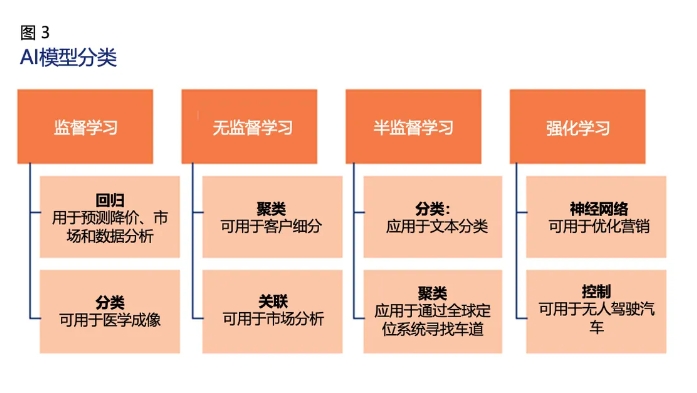
圖3描繪了AI模型的分類及其應用領域。
任何基于AI的ML模型都可以通過支持ML數據集的統計方法學習。AI模型分為以下四類:
- 監督學習:涉及從有標簽的數據集或經驗收集的數據中學習。
- 半監督學習:涉及到兩組數據——一組是有標簽的數據,另一組是無標簽的數據。
- 無監督學習:允許機器使用未標記的數據學習。
- 強化學習:基于一系列關于學習目標的積極或消極結果。
AI監管會帶來哪些影響?
討論與公平、真實性以及內容限制(這些是最主要的監管考量因素)相關的問題是政府的職責。許多現行的AI法案和法規對大型語言模型、生成式AI聊天機器人以及自然語言處理算法產生了深遠的影響。全球范圍內的IT專業人士和組織需要審視監管的當前和未來的影響,以了解哪些領域可能需要進一步的監管干預。
近期法規的影響
除了規定的指導原則和禁令之外,現行法規并未深入探究其實際影響(比如在涉及兒童時如何促進道德實踐,或者如何對AI模型進行編程,以根據以人為中心的價值觀做出決策)。歐盟旨在根據各類應用對公眾造成的風險程度進行分類。中國AI法案建議通過設計一種監管型大型語言模型,增加或創建過濾機制(如審查算法并提供用戶和兒童保護措施的管理系統),旨在刪除無依據的、非專有的和不受歡迎的信息。這兩種做法與美國法規制定形成鮮明對比,美國更常見的做法是,提出通過監管手段指導如何設計或使用AI的原則。
目前所有的監管干預措施都是由政府和監管機構實施的,他們有強烈的驅動力管理某些風險領域。這些領域是根據風險類型(由AI和ML產生)以及對監管所作出的具體響應的預期結果確定的。圖4描繪了監管干預所管理的四個風險領域。

ML和AI法規及法案的最佳結果將符合人類價值觀,防止不道德原則,并有能力說明是如何做出決策的。
AI法規的預期影響
在追求設立確保AI領域公平監管的過程中,存在隱性和顯性兩種期望的影響:
1.?非受控數據的影響——有必要保護數據的生成位置、目的、原始來源及其所有者/作者的引用。有些法規(如歐盟人工智能法案、中國AI相關規定)規定了這一需求,但其他法規沒有規定。需要強制監管要求,以提供必要的保障。
2. 與道德和人類考量因素相關的影響和偏見——法規應強制組織審查其AI模型中現有算法中存在的偏差類型(例如,由未經驗證的數據源驅動的以特定人群為中心的數據),并對此類算法進行改進。監管要求應當明確列出算法應避免的偏差類型(例如,以特定人群為中心的偏差、由未經驗證的數據源驅動的偏差)。通過使用不同類型數據集訓練算法,以防止產生偏差。
3. 易訪問的隱私和敏感信息的影響——多部數據隱私法規已經解決了潛在的安全風險(例如歐盟人工智能法案、中國AI相關法規);然而,法規需要強制要求AI組織提供數據清理、數據清洗、和加密個人可識別信息(PII)的能力。
4. 對兒童教育的影響——監管機構和領先的AI組織需要共同努力設計兒童適宜的特定AI過濾模型,減輕偏見并激發兒童的好奇心,從而幫助他們從答案中學習,而不是像生成式AI簡單地為問題提供簡單的答案。
5. 對研究與創新的影響——AI模型可以根據研究論文的重點、領域、時間線及創新準備(即快速實現想法的能力),幫助從研究論文中提煉出有意義的見解。未來,AI模型可能能夠通過按主題設計研發模型或根據現有的按主題研究生成創新模型的方式,彌合研究與創新之間的鴻溝。監管機構需要意識到AI的潛力,制定或更新監管法案和法規,以確保在數據和創新AI模型效果方面建立信任。
6. 對生命科學(包括藥物研發)的影響——目前,有一些AI算法可以加快識別潛在藥物成分,這些成分可能對于某些威脅生命的疾病的藥物配方至關重要。還有一些模型能夠模擬醫生會診,準確率接近70%-80%。監管機構的關鍵是通過定期對這些模型進行審計來實現信任和數據準確性。這一過程與法定審計或現場檢查非常相似。
7. 對未來互聯設備的影響——世界是復雜且相互連接的。智能手表數據(用于測量健康數據)可以位于與智能家居設備使用相同電子郵件地址共享的同一云服務上。由于數據、用戶和設備之間不可避免的相互連接,監管機構必須開始將主要設備和輔助設備上的所有AI軟件視為設備本身的擴展,并提供監管干預(通過監管AI模型或針對偏見和隱私問題的額外過濾器)。
AI監管的未來是什么?
為了確保當前和未來AI法規的有效性,亟待解決以下問題:
- 監管機構對AI模型的類型和應用的知識培訓與意識提升;
- 根據風險考慮數據、算法和模型在世界各地的適用性;提供多層次的自我監管方法,不僅由監管機構推動,并且根據行業、公眾和組織的反饋,不斷實現反饋和改進;
- 建立監管機構聯盟,這些機構共同探討當前監管法律中存在的差距(如AI模型中的數據透明度和決策),并研討如何在短期、中期和長期填補這些差距;
- 監管機構與行業團體就AI的影響進行持續和定期的協調,并共同探討挑戰與解決方案。政府、州或地方監管機構可能會與致力于開發和實施ML和AI工具的組織、企業和顧問會面,從而達成一致。
結論
對AI和ML的監管干預的未來似乎是一條漫長且曲折的道路。如果行業從業者和監管機構組建聯盟或參與聯合項目,持續監測并改進現有法規,將有助于明確確定和實施AI工具的護欄。
來源:安全牛