

為什么不建議在自治安全中推銷機器學習
責編:gltian |2019-09-10 15:04:33網絡安全產品營銷人員可能會這么向你推薦:有個新式的先進網絡入侵設備,運用當前超智能的機器學習 (ML) 根除已知和未知入侵。這個 IDS 設備真是太聰明了,可以學習你網絡上的正常和不正常事件,只要一發現異常就會馬上通知你。或者說,這是一款可以封鎖所有惡意流量的入侵預防系統 (IPS)。這款 AI 驅動的解決方案能達到 99% 的攻擊檢測準確率。而且,連此前未知的攻擊都可以檢測哦!聽起來真是好誘人,對吧?

但,銷售說得天花亂墜,真相令人欲哭無淚。真正了解自治安全 (autonomous security) 和機器學習的人不會被市場營銷人員忽悠。主要原因有兩個:
1. 上述推銷混淆了攻擊檢測與入侵檢測。攻擊未必成功;入侵則肯定是成功的。假設你檢測到 5 個新攻擊,但只有 1 個是真實的入侵。難道你不想只專注于那個成功的入侵,而無視那 4 個失敗的攻擊嗎?
2. 采用 ML 的安全未必足夠健壯,可能在某個數據集上(很多情況下都是供應商的數據集)效果良好,而在另一個數據集上(你自己的真實網絡)表現糟糕。總之,攻擊者的任務是規避檢測,而 ML 研究已證明做到這一點并不難。
簡單講,ML 算法通常無意打敗現實中隨時準備攻擊的對手。事實上,對抗性機器學習在學術研究領域都還只處在起步階段,更不要說運用 ML 技術的實際產品了。別誤會,有些 ML 研究和研究人員很棒,但若說已達到可驅動完全自治的程度,那就是在說笑了。
自治安全的愿景是由機器檢測、響應和防護。而上面列出的兩個原因,讓 ML 于完全自治無益。總結一下就是:
- 忙于追逐攻擊(大部分攻擊都是不成功的)的完全自治系統毫無用處;預防真正的入侵才是重點。
- 不健壯的系統很容易被繞過。從部署的那一刻起,攻擊者就會不斷試錯,找出可行方法,最終仍成功入侵。
- 但我們不妨再深入探索一下網絡安全與 ML,尤其是在入侵檢測與預防語境下。
檢測率 != 真實入侵
對 ML 產品不買賬的一個關鍵因素是:這些東西常把檢測率(經常列為準確率)跟真正攻擊率混為一談。在 IDS 語境中,用戶想要識別真正的入侵。他們不想研究攻擊者是誰。他們想要在攻擊者確實成功的時候檢測出來。但不幸的是,這些愿望僅僅是愿望,不是現實。
不知道讀者有沒有注意到,文章開篇其實用了偷梁換柱的誘餌推銷手法。
先以談論入侵檢測勾起興趣,但后面卻只給出了攻擊檢測準確率。放出一個誘餌,然后偷換概念掉包。看出來沒有?
檢測入侵和檢測攻擊是不一樣的。攻擊是入侵的潛在指征,但攻擊可能成功,也可能不成功。入侵則是有人切切實實成功了。
以端口掃描(比如說用 nmap)和針對性漏洞利用為例。腳本小子用 nmap 執行端口掃描,對目標系統嘗試默認密碼,基本突破不了系統防線,但針對性攻擊就完全不一樣了。針對性攻擊成功突破系統安全防線的可能性很高。用戶都想要好鋼用在刀刃上,將有限的資源、人力和精力花在真正的入侵上。
需要理解的一個關鍵概念就是基本發生率謬誤。這也不太算得上謬誤,只是人類在即時理解統計數據上的困難。(有數學頭腦的讀者可以看看卡耐基梅隆大學 Stefan Axelsson 的論文。想惹惱銷售代表的話,問問他有沒有讀過這篇論文。)這種認知上的謬誤很常見,比如賭徒覺得自己手氣正旺的時候。他們不時贏上一把,然后就覺得自己是“贏家”了。同樣的原則可以應用到安全上——如果你的 ML 算法不時命中,你的大腦會讓你誤以為這算法真的有效。
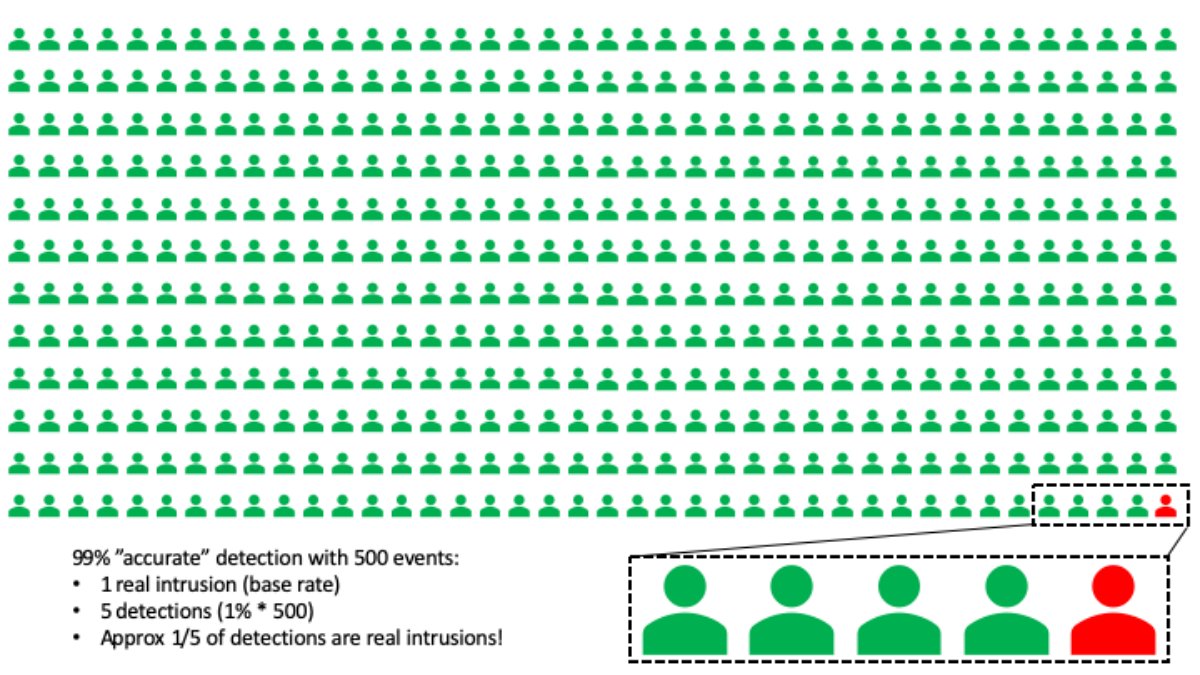
典型的基本發生率謬誤場景是這樣的:去體檢,做了項準確率 99% 的某病篩查。壞消息:檢查結果顯示你已罹患該疾病。好消息:該疾病本身相當罕見。事實上,500 個人中才會出現一例。那你真的患上該疾病的概率到底是多少呢?
謬誤就出現在這里:大多數人憑直覺會認為,既然檢查的準確率是 99%,那我就極有可能患上那病了。然而,數學對此表示反對。實際上,你罹患該疾病的概率僅 20% 左右。怎么會這樣?
可以這么想:99% 準確率的檢查意味著 100 個人里面有 1 個的檢查結果為陽性。但是我們知道,500 個人里才會出現一例病患。500 次檢查,檢測出 5 個人,但其中僅 1 例是真陽性,也就是真陽性概率僅約 20%。(如果你是數學家的話,可以用貝葉斯定理計算下精確的概率。此處用近似值是因為近似值比條件概率更好對付些。)
數字越大,謬誤越嚴重。比如說,假設真正的入侵率僅百萬分之一。99% 檢測準確率情況下,每個真正的警報伴隨有約 9,999 次誤報。誰有那么多時間去追逐這么多誤報?
這種謬誤應用到 IDS 和任何算法上,無論是不是機器學習吧,會怎么樣?如果實際成功入侵率很低,那即便 99% 準確的 IDS (如銷售所言)也會產生大量誤報。安全運營中心 (SOC) 的一條經驗法則就是,一位分析師一小時能處理 10 起事件。如果幾乎每起事件都只是攻擊(誤報)而不是真實入侵,那最好情況就是分析師被誤報淹沒,最壞情況就是分析師漸漸學會了無視 IDS。
實際上,數學分析顯示,幾乎什么誤報率都太高了。
機器學習不健壯
此處的健壯性指的是:攻擊者已預期到的情況下仍然有效嗎?從攻擊者的角度做個類比。假設,你想靠走私發家。戰戰兢兢通過安全檢查站的時候,嗶嗶嗶嗶,被逮了。那目前為止一切安好;司法部門(類比中的 IDS)成效顯著。之所以有成效,是因為你根本不知道他們到底要查什么,可能觸發了某些東西。
作為有志入行的罪犯,接下來你會怎么做呢?最自然的事情就是摸清檢查站的部署和檢查規則,然后規避檢查,對吧?換句話說,一旦你摸清防御,你就會找到繞過防御的方法。攻擊者同理。
只有在攻擊者改變攻擊方法時仍能檢測的 IDS 系統,才能算作是健壯的 IDS 系統。關鍵問題就在于:目前,ML 看起來有吸引力是因為攻擊者還沒開始嘗試騙過它。而一旦你已經部署了靠 ML 檢測的系統,攻擊者就將注意到自己無法突破,進而嘗試繞過之。
此處適用一套所謂的“沒有免費午餐理論” (NFL)。(原始論文和易讀摘要版鏈接均附在文末,可能需要點數學頭腦才能理解。)該 “沒有免費午餐” 理論講的是,不存在對每個問題都應用良好的通用模型。安全語境下,其含義就是,對任意 ML 算法,對手都可以創建一個違反假設的變種出來,讓 ML 算法表現十分糟糕。
當前安全領域 ML 研究難以證明 ML 算法的健壯性。例如:
1. Carrie Gates 和 Carol Taylor 在很多方面質疑基于 ML 的 IDS,其中健壯性(還有訓練數據質量)就是一個主要的不足之處。
2. 惡意軟件編寫者經常利用 VirusTotal (運行著很多商業反惡意軟件解決方案的系統)修改他們的惡意軟件以規避檢測。
3. 2016 年,弗吉尼亞大學的研究人員證明自己可以繞過檢測 PDF 惡意軟件的最先進機器學習算法。可以在 https://evademl.org/ 查看其結果。重點是:研究中用到的所有樣本,他們都能自動找出可繞過 ML 分類器的變種。進一步研究顯示,兩個簡單的改變,就有 47% 的概率騙過 GMail 的惡意軟件分類器。谷歌不孤單,其他基于 ML 的殺軟引擎也一樣容易被騙。
4. 目前,Lujo Bauer 帶領的卡耐基梅隆大學研究團隊已證明,可以 3D 打印出一副眼鏡,誘使最先進的人臉識別算法將識別目標認為是另一個(特定的)人。最簡單的例子:攻擊者完全可以用 3D 打印的眼鏡混過機場人臉識別安檢。雖然領域可能看起來略有差異,但道理是相通的——ML 在規避技術面前不堪一擊。
5. 在入侵檢測領域,著名人物 Vern Paxon(Bro 網絡 IDS 架構師)和 Robin Summers 發表了一篇很棒的綜述,講述入侵預防中 ML 和異常檢測所面臨的挑戰。
經驗教訓就是:攻擊者會學習你的防御,只要防御不夠健壯,他們總能繞過。
為什么對ML不買賬
基本上,以 ML 為賣點的自治安全營銷,在真專家面前都討不了好。如前文所述,原因有兩個。
1. AI 和機器學習 IDS 產品常不自知自己有多容易被繞過。即使剛部署時檢測效果驚人,那也只是曇花一現。
2. 堅實的數學分析顯示,幾乎任何誤報率——即使看起來低到不能更低的那種,在真實入侵相對(與攻擊相比)罕見的情況下都太高了。
而且,這還僅僅是個開始。還有其他技術問題本文沒有觸及,比如用來訓練的數據是否適用于你的網絡。谷歌和 AT&T 這樣的大公司算是有海量數據了,但在這方面依然問題不斷。另外,組織問題也無法回避,比如公司服務水平協議 (SLA) 是否經過調整,以便員工不用不用處理未知或奇點事件。成熟的安全運營中心一般會先摸清自身事件處理能力,然后適當調低檢測器報告閾值。
建議
首先,想清楚自己是只想要個短期解決方案,還是想要具有防規避健壯性的長期解決方案。如果只想濾掉互聯網浮渣,新型機器學習產品可能有所幫助。然而,并沒有科學共識表明這些產品扛得住攻擊者的試探和了解。
其次,認真思考自己到底想檢測什么:是想研究攻擊者,還是負責響應真正的問題?比如說,基本發生率謬誤已經告訴我們,如果公司每次的攻擊入侵率相對較低(如果確實不知道的話可以去問公司安全團隊),數學分析已揭示殘酷現實:任何方法——無論是否基于 ML,都對你沒用。
那么 ML 真正有用的地方在哪兒呢?此事尚無定論,但一般而言,ML 是基于統計的,更適合想相對提升統計準確率的場景。此處用“統計”這個詞是有所指的:你得接受存在風險的事實。例如,谷歌就在利用機器學習提升廣告點擊率上大獲成功,因為 5% 的提升都意味著百萬級(十億級?)的收益增長。但,對要為公司安全負責的你而言,5% 就夠了嗎?
ML 有所幫助的另一個方面是濾掉低級攻擊者。例如采用著名漏洞利用程序的腳本小子。這種情形下我們已經不需要健壯了,因為就沒想著對付真想騙過 ML 算法的人。
最后重申一點:正在研究 ML 的研究人員和研究項目很棒。我們需要更多更好的 ML。我們僅僅是還沒研究到普通用戶期待的那種程度而已。
應用安全(至少部分應用安全)完全自治是有可能的。原因在于:
1. 應用安全測試技術,比如模糊測試,是零誤報的。
2. 攻擊者控制不了你部署什么應用,也就談不上繞過。
至于說 ML 加持的 IDS 有沒有可能成為完全自治的網絡防御,至少現在不行。
Stefan Axelsson 的論文:
http://people.scs.carleton.ca/~soma/id-2007w/readings/axelsson-base-rate.pdf
沒有免費午餐理論:
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.390.9412&rep=rep1&type=pdf
NFL 易讀版:
Robin Summers 的 ML 面臨挑戰綜述:
https://personal.utdallas.edu/~muratk/courses/dmsec_files/oakland10-ml.pdf)