

STAMINA:把惡意軟件轉換成圖像的深度神經網絡
責編:gltian |2020-05-13 14:14:15近日,微軟和英特爾合作開發了一個全新的檢測和分類惡意軟件的人工智能研究項目——STAMINA。
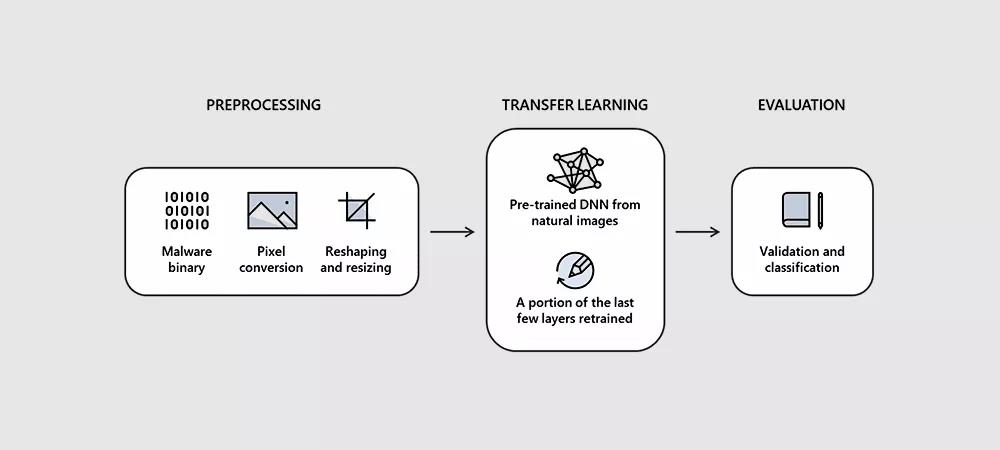
STAMINA(STAtic Malware-as-Image Network Analysis)能夠將惡意軟件樣本轉換為灰度圖像,然后掃描識別獲取特定惡意軟件樣本的紋理和結構模式。
STAMINA的實際運作方式
英特爾和微軟研究團隊表示,整個過程遵循幾個簡單步驟。第一個步驟包括獲取輸入文件并將其二進制代碼轉換為原始像素數據流。
然后,研究人員將這些一維的像素流轉換為二維照片,以便使用常規圖像分析算法對其進行分析。
通過下面這張換算表根據文件大小來確定圖像寬度、圖像高度是動態的,通過將原始像素流除以所選寬度值得到。
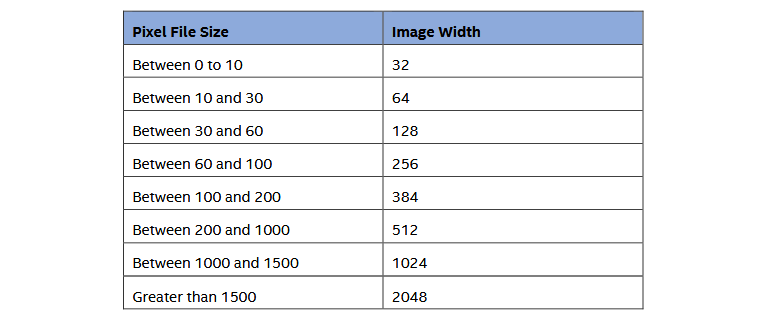
圖片來源:英特爾,微軟
在將原始像素流組合成二維圖像后,研究人員隨后將生成的照片調整為較小的尺寸。
英特爾和微軟團隊表示,調整原始圖像的大小不會“對分類結果產生負面影響”,這是必要的步驟,因為計算資源沒有必要處理包含數十億像素的原始圖像,調整圖像大小可以大大加快處理速度。
然后,將駐留的圖像輸入經過訓練的深度神經網絡(DNN),該網絡會掃描圖像(惡意軟件株的二維表示)并將其分類為“干凈”或“已感染”。
微軟表示,它提供了220萬個受感染PE(便攜式可執行文件)文件哈希的樣本,作為該研究的素材。
研究人員使用60%的已知惡意軟件樣本來訓練原始DNN算法,使用20%的文件來驗證DNN,其余20%用于實際測試過程。
研究團隊表示,STAMINA在識別和分類惡意軟件樣本方面,STAMINA達到了99.07%的準確性,誤報率為2.58%。
兩位代表Microsoft威脅防護情報小組參加研究的Microsoft研究人員Jugal Parikh和Marc Marino說:
這個結果令人振奮,有助于推動業界將深度學習用于惡意軟件分類。
微軟開展機器學習的“先天優勢”
該研究是Microsoft使用機器學習技術改進惡意軟件檢測工作的一部分。
STAMINA使用了深度學習技術,而深度學習是機器學習(ML)的子集,機器學習(ML)是人工智能(AI)的一個分支,是指能夠從以非結構化或未標記格式存儲的輸入數據中自行學習的智能計算機網絡。在STAMINA的用例中,數據是隨機的惡意軟件二進制文件。
微軟上周在一篇博客文章中表示,雖然STAMINA在處理較小文件時是準確快速的,但處理大文件仍有問題:
對于更大尺寸的應用程序,由于需要將數十億像素轉換為JPEG圖像并調整大小,STAMINA的效率降低了。
但是,這很可能無關緊要,因為該項目處理的主要是小型文件,效果很好。
微軟威脅防護安全研究主管Tanmay Ganacharya在本月初接受采訪時表示,微軟現在嚴重依賴機器學習來檢測新興威脅,STAMINA使用的機器學習模塊有別于已經在客戶或者微軟服務器系統中部署的模塊。
Ganacharya透露,微軟正在使用客戶端機器學習模型引擎、云端機器學習模型引擎、機器學習模塊來捕獲行為序列或捕獲文件本身的內容。
根據目前公布的測試結果,STAMINA可能很快就會成為微軟用來檢測分析惡意軟件的機器學習模塊之一。
微軟使用機器學習分析惡意軟件有一個得天獨厚的優勢,那就是它擁有來自數億Windows Defender客戶端安全軟件的龐大數據。
Ganacharya說:
任何人都可以開發模型,但是標記的數據,數據的數量和質量確實有助于正確地訓練機器學習模型,從而決定了模型的有效性。
而且,這是微軟的優勢,因為我們確實擁有大量“傳感器”,這些傳感器通過電子郵件、身份、端點以及各種應用組合在一起,將大量有趣的情報輸送給我們。