

對抗重編程攻擊
責編:gltian |2021-12-03 10:57:05
前言
我們知道深度學習模型容易受到對抗樣本攻擊,比如在計算機視覺領域,對圖像精心設計的擾動可能會導致模型出錯。雖然現在對抗樣本的研究非常火,但是模型面臨的攻擊不止有對抗樣本攻擊。
Goodfellow(是的,就是GAN之父)團隊又設計了一種新的攻擊范式,叫做adversarial reprogramming,中文可以叫做對抗重編程。這種攻擊范式的目標是對目標模型重新編程,以執行攻擊者選定的任務,這種攻擊的危害的潛在后果包括竊取MLaaS的計算資源、將人工智能驅動的智能助手當做間諜或垃圾郵件機器人等等,可以重用預訓練好的模型來實現攻擊者的對抗任務,既然在原理上已經說明這是可行的,那么之后會發展出什么攻擊場景、危害行為都是有可能的。
對抗重編程
先來看看整個對抗重編程的流程
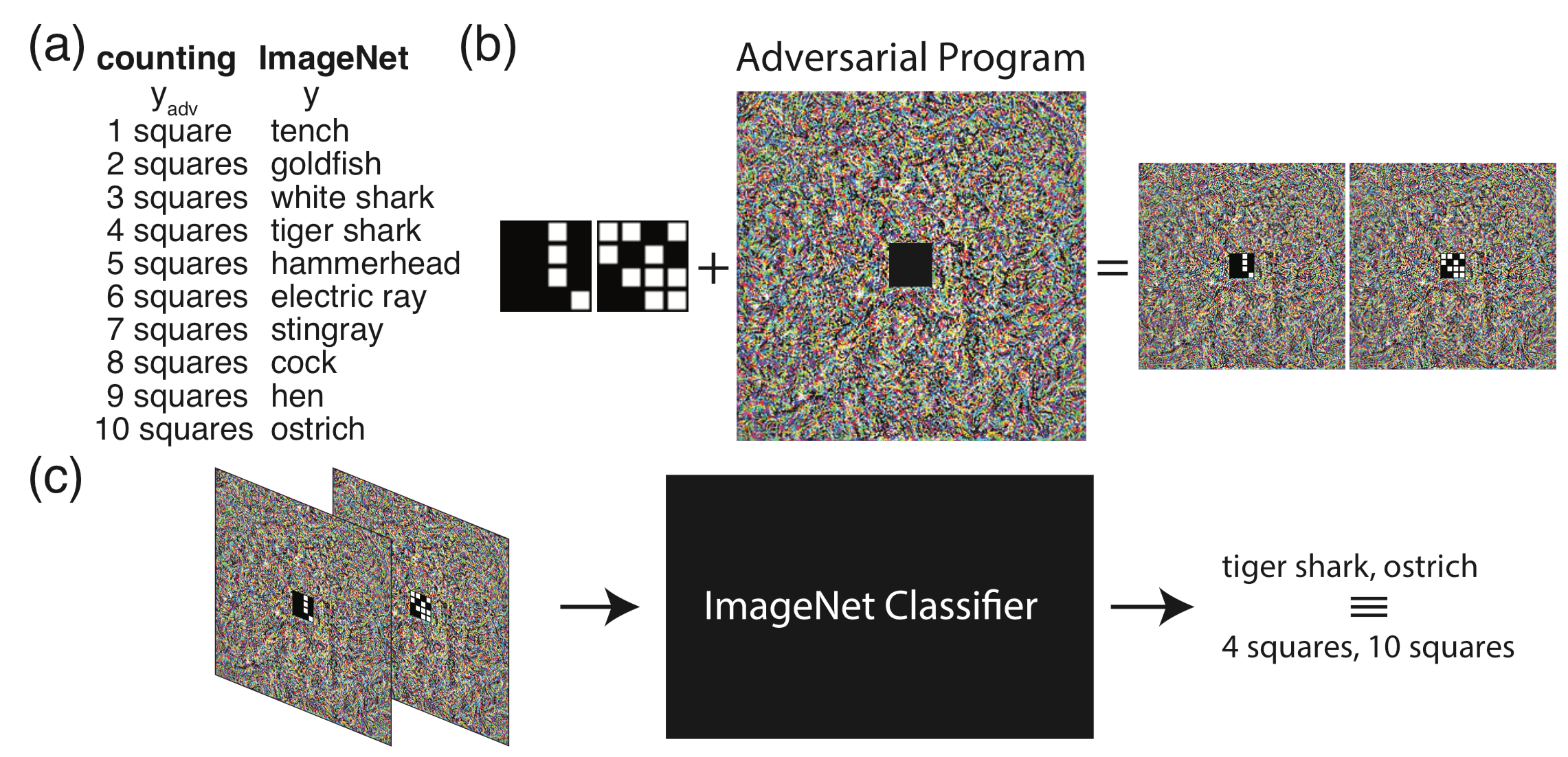
在a中,我們將imagenet任務的輸出標簽映射到對抗任務的標簽,這里我們給定的對抗任務是計算小圖像中的格子數量,所以對抗任務的標簽為1~10;在b中,將對抗任務的小圖像嵌入到對抗程序的中間,從而得到對抗圖像。在c中,當把對抗圖像輸入分類器時,分類器此時會輸出標簽tiger shark,ostrich等,不過由于有hf函數的存在,他們會被映射到對應的4,10等。經過這一套流程,我們對一個在imagenet上訓練的分類模型進行了對抗重編程攻擊,使它的任務變為數格子。
原理
我們設一個經過訓練的模型,其原本的任務是,給定輸入x,會得到輸出f(x)
現在有一個攻擊者,其對抗任務是對于給定的輸入x~,會得到輸出g(x~),這里x~和x不一定需要是同域的。
這看起來是不可行的,但是攻擊者通過學習對抗重編程函數hf(.;θ)和hg(.;θ)來實現這兩個任務之間的映射。
hf(.;θ)用于將輸入從x~所在的域轉換到x所在的域,也就是說,經過hf的處理后得到的hf(x~;θ)對于f而言是有效的輸入;而hg則將f的輸出f(h(x~;θ))映射會g(x~)的輸出。這里對抗程序的參數θ會被調整以滿足:
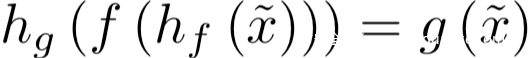
這里為了簡單起見,我們將x~定義為小圖像,g為處理小圖像的函數,x為大圖像,f為處理大圖像的函數。hf函數的作用則是在大圖像的中心進行修改,hg則是在輸出標簽之間一個簡單的硬編碼的映射函數。事實上,hf (hg)可以是任何一致的轉換,在兩個任務的輸入(輸出)格式之間轉換,并讓模型執行對抗任務。
在整個攻擊中,我們將對抗程序定義為:
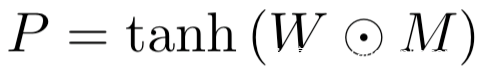
其中
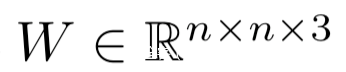
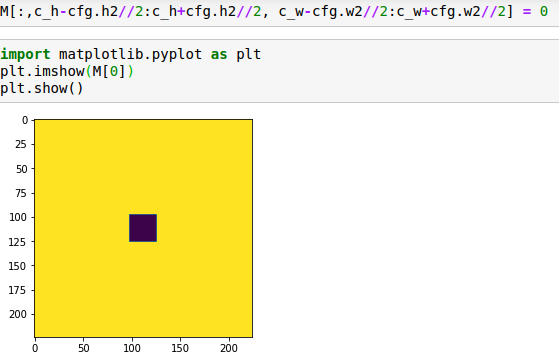
是需要學習的對抗程序參數,n是imagenet圖像的寬,M是掩碼矩陣,對于對抗任務對應的對抗數據的圖像位置的值為0,否則為1
上面的式子中我們用了tanh,這是為了將對抗擾動限定在(-1,1)范圍內,這與目標模型訓練分類的重縮放后的ImageNet圖像相同
設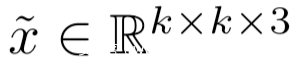
是我們執行對抗任務所用的樣本,其中k<n
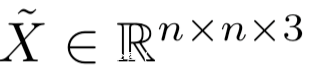
則是和Imagenet圖像同樣大小的圖像,x~被放置在了通過M定義的合適的區域。
所以對應的對抗圖像為:
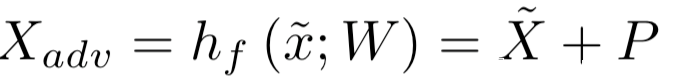
設P (y|X)為目標模型給定輸入圖像X,ImageNet圖像的標簽y∈{1,…, 1000}。我們定義一個硬編碼的映射函數hg (yadv),它將一個標簽從一個對抗任務yadv映射到一組ImageNet標簽。例如,如果一個對抗任務有10個不同的類(yadv∈{1,…10},hg(·)可以定義為將ImageNet的前10個類、任何其他10個類或多個ImageNet類映射給對抗標簽。
因此,我們的對抗目標是使P (hg (yadv)|Xadv)的概率最大化。我們把最優化問題設為
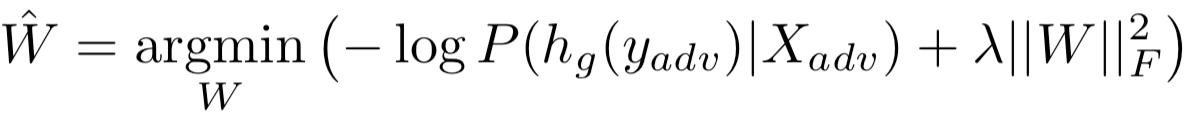
其中λ是權重范數懲罰項的系數,以減少過擬合。用Adam優化器優化損失。
注意,優化之后,對抗程序對于攻擊者而言有最小的對抗損失,因為它只需要計算Xadv,并將得到的ImageNet標簽映射到正確的類標簽。換句話說,在推理過程中,攻擊者只需要存儲程序并將其添加到數據中,從而將大部分計算留給目標模型。
這里還有一種需要注意的是,這種攻擊方式必須要利用目標模型的非線性行為,這和傳統的對抗樣本的攻擊不同,它們是基于對模型的線性逼近,從而造成高的錯誤率。假設存在一個線性模型,它接收輸入x~以及連接到單個向量x的θ :
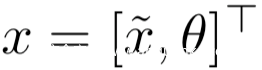
假設線性模型的權重分為兩部分,即:
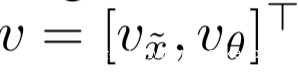
則模型的輸出為:

從上式可以看到,對抗程序θ對偏置起作用,但是卻沒用應用于x~的權重。
因此,對抗程序θ可以使模型始終輸出一類或另一類,但不能改變輸入x的處理方式。為了實現對抗性重編程,模型必須存在x?和θ之間的非線性相互作用。而非線性的深度學習模型恰好滿足這一點。
實驗分析
這里為了驗證對抗重編程是可行的,設計了三種對抗任務,分別是數格子、MNIST分類和CIFAR10分類
數格子:
正如在對抗重編程的流程圖中看到的一樣,生成了尺寸為36 × 36 × 3的圖像(x?),其中包括9 × 9個帶有黑色框架的白色方塊。每個正方形可以出現在圖像中的16個不同的位置,正方形的數量從1到10。這些方塊被隨機放置在網格點上。我們將這些圖像嵌入到一個對抗程序,得到的圖像(Xadv)大小為299 × 299 × 3,中間的方格為36 × 36 × 3。我們為每個ImageNet模型訓練一個對抗程序,使前10個ImageNet標簽代表每幅圖像中的正方形數量。注意,在ImageNet中使用的標簽與新的對抗性任務的標簽沒有關系。例如,“White shark”與圖像中的3個方塊數無關,而“Ostrich”與10個方塊一點也不相似。
MNIST分類:
與數格子任務類似,將大小為28 × 28 × 3的MNIST數字嵌入到對抗程序中,我們將前10個ImageNet標簽分配給MNIST數字,并為每個ImageNet模型訓練一個對抗程序。下圖是應用于每個網絡的對抗程序的示例。

CIFAR-10分類:
CIFAR10的處理也與MNIST類似,一些對抗圖像的實例如下

我們也可以很直觀地看到三個任務對于每個模型訓練后生成的對抗程序

實驗結果總結在表格里了:

表中第二類是數格子、第三列是MNIST分類,第四列是CIFAR10分類,可以看出對抗重編程的攻擊效果還是非常好的。
復現
為了直觀的理解,會在解釋代碼的同時打印出對應的變量
相關配置文件
這里的h1,w1是大圖像,即imagenet圖像的尺寸,h2,w2是對抗任務所用的小圖像的尺寸。
初始化掩碼,即前面提到的M

使用imagenet標簽的前10個作為對抗任務的標簽

最關鍵的是compute_loss函數以及forward函數
compute_loss函數如下

正如前面提到的,這里的損失由兩項組成,第一項是正常訓練損失,第二項是權重懲罰項,這里用的是l2范數,lmd是系數,已經在配置文件中定義了
forward函數如下
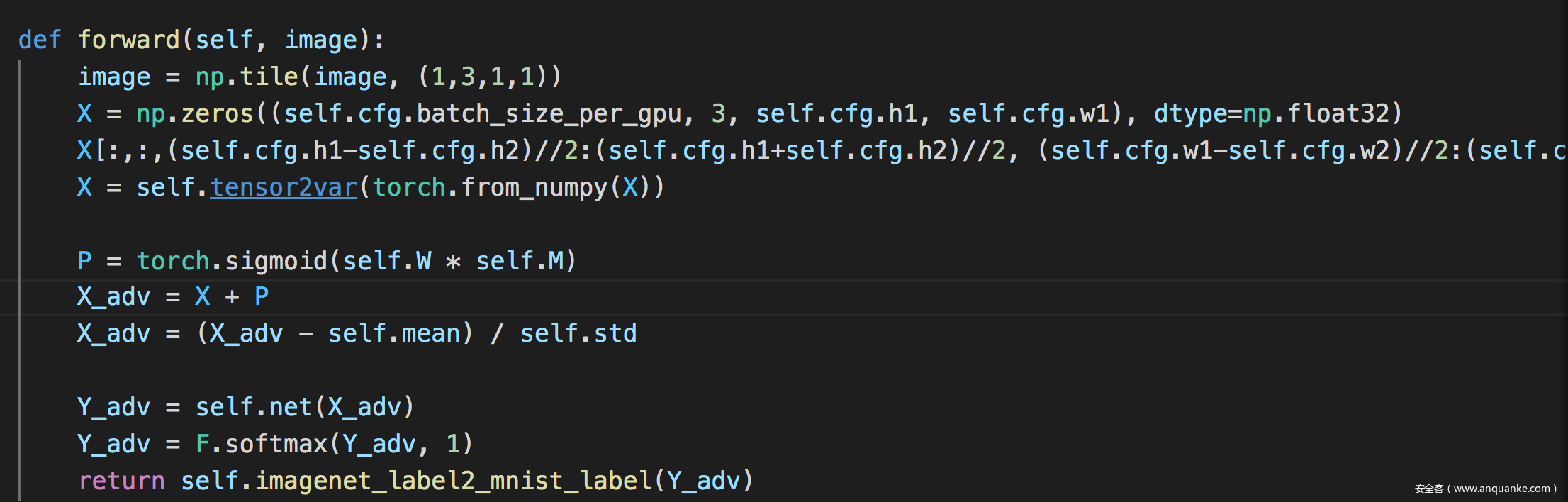
為了方便理解,我們一步步打印出看看
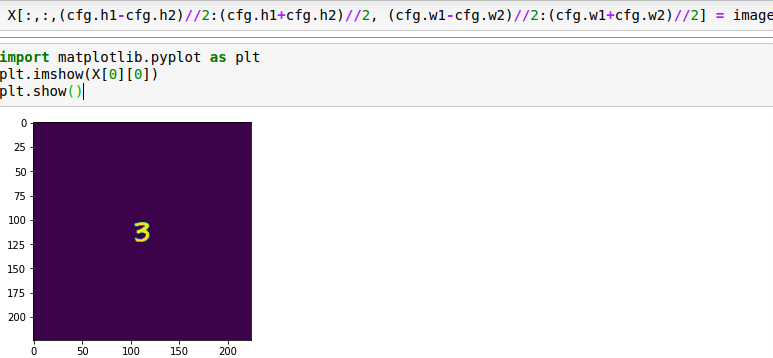
首先是image,也是論文中提到的x~

論文中的X通過代碼實現的:
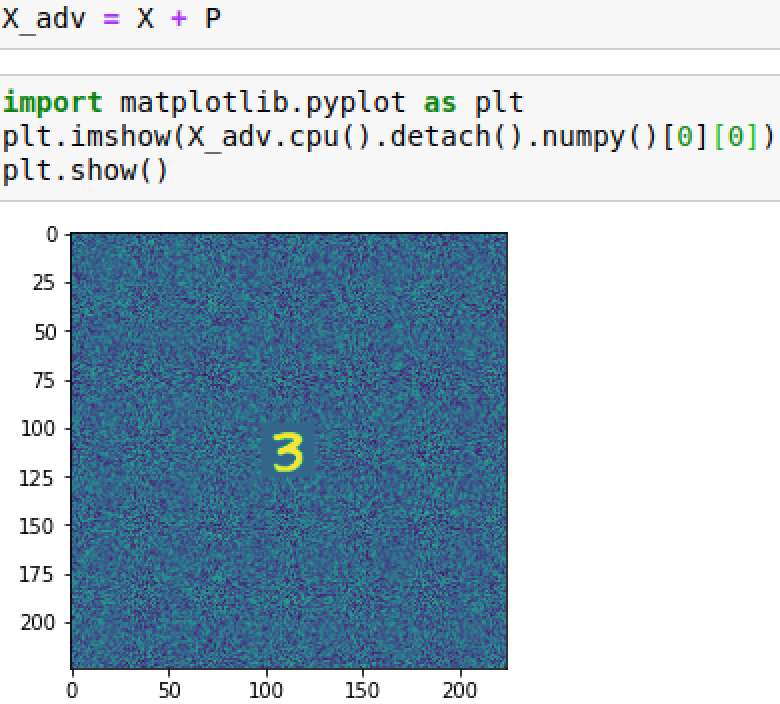
在目標模型上生成的對抗程序,即P

X+P得到對抗圖像
訓練函數
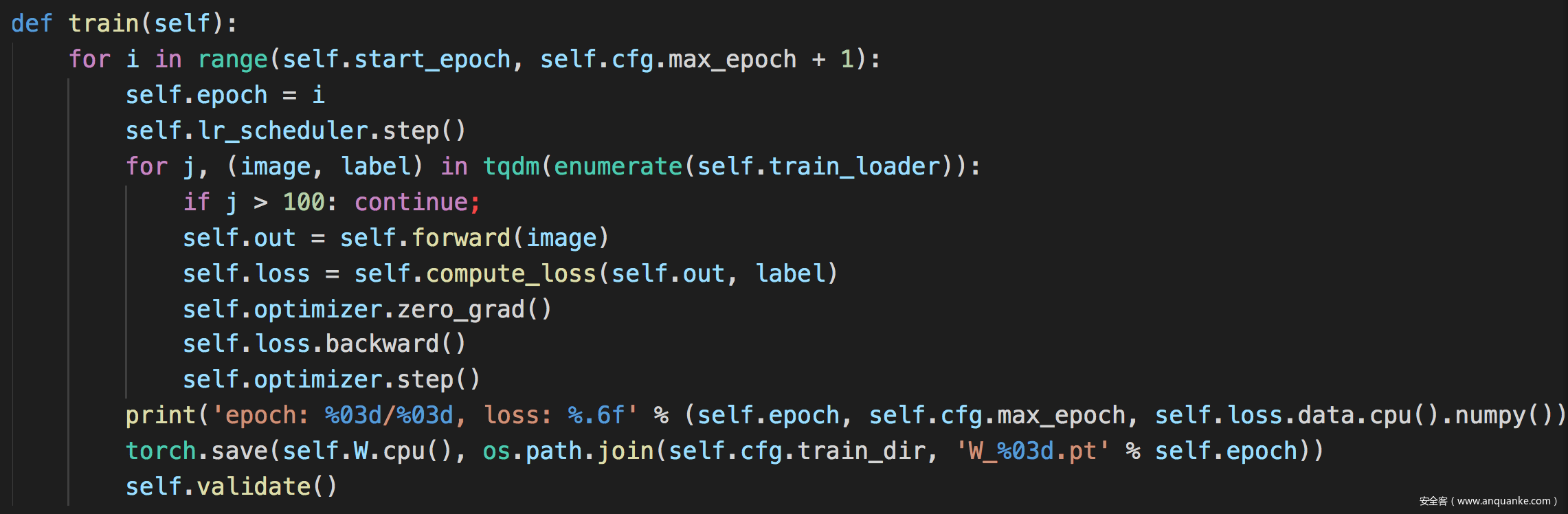
可以看到self.out是由self.forward返回的,這里就是訓練部分。
訓練過程運行如圖

我們先來看看在原模型上進行測試時的效果
![]()
然后是在訓練后的模型上測試的效果
![]()
可以看到確實成功率提高了不少。
這里的對抗重編程攻擊針對的還只是計算機視覺的分類任務,在其他領域的也有研究人員進行了分析,包括參考文獻中的2.3對自然語言處理中的應用進行了研究。此外還有研究人員詳細分析了對抗重編程可以成功進行攻擊的條件以及背后的原因,詳見參考文獻4.
此外,通過本文的介紹,師傅們應該隱隱約約看出來,這種攻擊范式有對抗樣本、后門攻擊、UAP的影子,這方面的結合點還是很有意思的。
參考
1.Elsayed G F, Goodfellow I, Sohl-Dickstein J. Adversarial reprogramming of neural networks[J]. arXiv preprint arXiv:1806.11146, 2018.
2.Neekhara P, Hussain S, Dubnov S, et al. Adversarial reprogramming of text classification neural networks[J]. arXiv preprint arXiv:1809.01829, 2018.
3.Hambardzumyan K, Khachatrian H, May J. Warp: Word-level adversarial reprogramming[J]. arXiv preprint arXiv:2101.00121, 2021.
4.Zheng Y, Feng X, Xia Z, et al. Why Adversarial Reprogramming Works, When It Fails, and How to Tell the Difference[J]. arXiv preprint arXiv:2108.11673, 2021.
轉載自安全客:https://www.anquanke.com/post/id/259831
上一篇:谷歌云平臺工作負載攻擊方法分析
下一篇:淺析正則表達式性能問題