

MINER:一種用于REST API模糊測試的混合數據驅動方法
責編:gltian |2024-11-18 15:45:25
原文標題:MINER: A Hybrid Data-Driven Approach for REST API Fuzzing
原文作者:Chenyang Lyu;Jiacheng Xu;Shouling Ji;Xuhong Zhang;Qinying Wang;Binbin Zhao;Gaoning Pan;Wei Cao;Peng Chen;Raheem Beyah第一作者主頁:https://lyuchenyang.github.io/發表期刊:32nd USENIX Security Symposium主題類型:漏洞檢測筆記作者:宋霽洋@Web攻擊檢測與追蹤
MINER的基本框架如下圖所示,主要由5部分組成:序列模板選擇模塊、生成模塊、Fuzz模塊、收集模塊、注意力模塊。
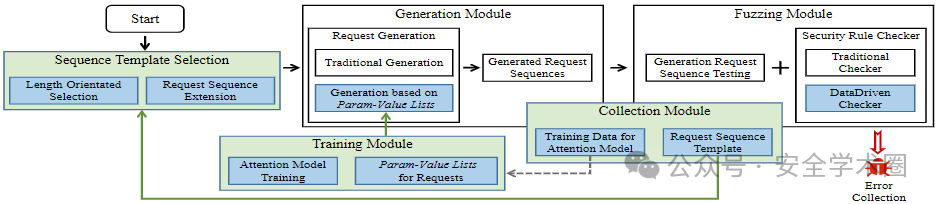
基本的工作流程就是MINER持續生成連續的請求來測試云服務的rest api。MINER如同已經存在的fuzzer一樣在編譯模塊構建請求模板來測試rest api。首先,利用序列模板選擇模塊,在概率上根據長度選擇請求序列模板,然后延展這個序列。再用生成模塊生成序列模板中的模板請求并構造能夠使用的序列。模糊測試模塊會測試生成的請求序列。收集模塊會收集歷史數據。歷史數據應是有效請求并且相關變異的參數。用參數值對,來表示變異參數以及在請求生成中使用的值。最后,周期的在訓練模塊用收集到的鍵值對來訓練一個注意力模型。用這個訓練的模型,對每一個請求模板來生成需要的鍵值對。
序列模板選擇模塊
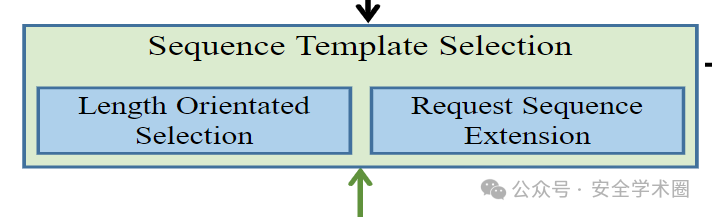
在這個組件中,MINER 基于從收集模塊收集的種子序列模板構建候選序列模板。具體來說,MINER 首先根據其長度為每個種子序列模板分配不同的選擇概率。序列模板越長,其選擇概率越大。其次,對于每個選定的序列模板,MINER 執行擴展過程以構建候選序列模板。換句話說,MINER 在所選模板的末尾添加了一個新的請求模板。基于上述設計,MINER 實現了長度定向序列構建。
生成模塊
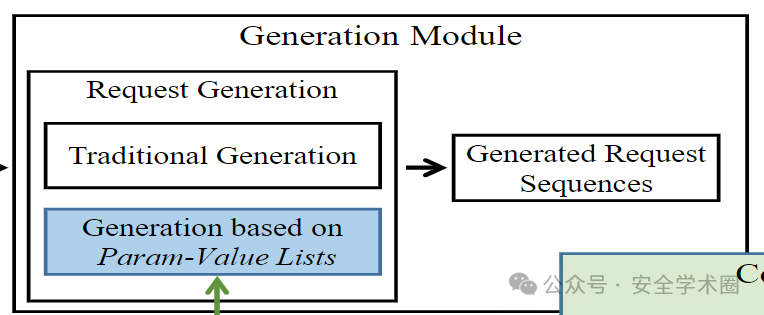
在這個部分中,MINER會在候選序列模板中生成每個請求,即MINER會為每個參數分配一個值,不包括請求中的目標對象 id。如圖3所示,MINER實現了兩種方法來生成請求。第一個是傳統的生成方法,即為每個參數隨機選擇一個替代值,第二種方法的過程如下所示。
為了生成請求,MINER 1) 為每個參數選擇默認值;2) 找到那個用于變異的鍵值對的集合,這個集合是通過注意力模型對這個模板生成的;3) 根據均勻分布從鍵值對集合中概率的選擇候選概率鍵值對;4) 根據鍵值對集合中選定的值,來調整參數。對于不在所選參數值列表中的參數,MINER 保留在請求生成中使用的默認值。通過執行上述過程,MINER 實現了基于注意力的請求生成。
在實現中,為了生成包含 n個請求的序列,MINER 使用鍵值對表的方法來生成前 n-1 個請求,并使用傳統的生成方法生成最后一個請求。原因如下,在生成前 n-1 個請求時,MINER 希望利用鍵值對表來提高生成質量。這有助于觸發目標云服務的正常執行。然后,MINER 利用傳統的生成方法生成最后一個請求,以增加觸發異常行為的概率。
Fuzz模塊

在這個組件中,MINER執行以下過程來探索獨特的錯誤。首先,MINER通過其REST API將生成的請求序列發送到云服務,并分析每個請求對應的響應。如果MINER收到了一個50×范圍內的響應,MINER認為對應的請求觸發了錯誤,并將生成的序列及其響應存儲在本地以供將來分析。其次,MINER利用每個安全規則檢查器對當前請求序列進行變異,以觸發特定的規則錯誤。特別是,我們提出了請求參數違規檢查,并實現了一個名為DataDriven Checker的新安全規則檢查器,以找到由于未定義的參數使用而導致的錯誤。
一般來說,供應商為每個請求定義特定的參數,以觸發云服務的特定行為。如果用戶向請求添加未定義的參數并將其發送到云服務,則云服務通常會忽略未定義參數的不正確使用,并根據定義的參數值執行行為。然而,由于各種情況,云服務可能會根據未定義的參數執行意外行為。
為了捕捉這種規則違規,DataDriven Checker 在生成過程中向請求添加了一個未定義的參數值對。具體來說,對于序列中的最后一個請求,MINER 隨機選擇收集模塊中收集的未定義的鍵值對。然后,MINER 將所選的鍵值對添加到序列的最后一個請求中。最后,MINER通過其REST API將新構建的請求序列發送到云服務。如果云服務在50×范圍內返回響應,MINER認為新請求觸發不正確的參數使用錯誤,并在本地存儲序列以進行進一步分析。
收集模塊

在模糊測試過程中,MINER首先收集有效的請求序列,其中所有請求都通過Fuzz 模塊中云服務的檢查。這些序列被用作序列模板選擇中的種子序列模板,以指導序列構建。其次,MINER分析來自云服務的每個生成的請求的響應,并提取在通過檢查的有效請求中使用的鍵值對。具體來說,如果一個請求在20×和50×范圍內收到響應,這意味著請求通過了檢查并觸發了云服務的某種行為,MINER會分析請求中每個參數的使用值。如果使用的值不是參數的默認值,MINER將該值視為對該參數的關鍵突變,并將其存儲為鍵值對。因此,MINER為每個有效請求收集了一個鍵值對列表,其中包含有效的突變,以幫助通過云服務的檢查。
貢獻分析
- 貢獻點1:論文針對請求序列長度不夠,無法發現云服務深層狀態問題,提出了面向長度的序列構建方法,實現了面向長度的序列構建,并利用使用過的種子作為種子的模板,來指導序列構建。
- 貢獻點2:論文針對云服務檢測通過率低的問題,提出了注意力模型生成鍵值對方法,實現了一個注意力模型,為關鍵參數提供合適的值,來提高云服務檢查的通過率。
- 貢獻點3:論文針對未定義參數造成云服務錯誤問題,提出了鍵值對模糊測試方法,實現了一個能夠生成未定義參數的工具,進行安全檢查。
代碼分析
代碼鏈接:https://github.com/puppet-meteor/MINER
簡要對其論文的代碼進行點評,點評內容如下:
- 代碼使用類庫分析,是否全為開源類庫的集成?
MINER 的代碼開發是基于RESTler的基礎上進行實現的。然而,RESTler[1]工具并沒有完全開源。其中在讀取swagger規范文件生成相應進行fuzz的api格式中,并沒有開源。
- 代碼實現難度及工作量評估
代碼實現的相關功能模塊并不是過于復雜,但是工作量偏多。因為是在RESTler的基礎上,用相關的python代碼實現自己的各個創新點模塊。
- 代碼關鍵實現的功能(模塊)
代碼主要實現的有注意力模型生成的模塊、面向長度的序列構建模塊。還有未定義參數檢測模塊。
論文點評
MINER不同于APIfuzzer[2]與TnT-Fuzzer[3]兩者。因為,大部分對REST API的模糊測試對連續的請求序列構建是不足的,如TnT-Fuzzer,只會在單一API的請求參數上進行隨機值的變異。這也導致云服務很多深度狀態難以達到。MINER的提出確實在這方面有了新的思路,但它依然有局限性。
MINER的局限性以及可能的解決方法如下所示。
- 數據集的局限:
由于在模糊測試過程中收集的訓練數據不足,很難為序列生成訓練一個注意力模型。然而,在不同場景下,如連續模糊測試和并行模糊測試,可能會有足夠的訓練數據用于序列生成。因此,利用機器學習模型為請求序列提供關鍵的變異策略可能在未來工作中還有待改進。
- Bug難以復現的局限:
由于服務器狀態的改變,一些唯一的錯誤只能在云服務的特定狀態下觸發,而在未來的分析中無法重現。這是REST API模糊測試中常見的問題。例如,一個模糊測試工具可以通過訪問一個資源來觸發錯誤,該資源是由其他請求序列幾個小時前創建的。然而,在接下來的模糊測試過程中,模糊測試工具刪除了這個資源,使錯誤無法重現。因此,如何分析相距較遠的請求序列之間的相關性以及如何重現這種錯誤可能是REST API模糊測試的一個有趣的研究方向。
參考文獻:
- [1] V. Atlidakis, P. Godefroid, and M. Polishchuk. RESTler: Stateful REST API Fuzzing. In Proceedings of the 41st International Conference on Software Engineering, pages 748–758, 2019.
- [2] APIFuzzer: HTTP API Testing Framework. https: //github.com/KissPeter/APIFuzzer.
- [3] TnT-Fuzzer: OpenAPI Fuzzer Written in Python.https://github.com/Teebytes/TnT-Fuzzer.
安全學術圈招募隊友-ing
有興趣加入學術圈的請聯系?secdr#qq.com