

GeekPwn大賽百萬懸賞AI黑客 CAAD攻防賽聚焦大熱對抗樣本
責編:gltian |2018-04-20 13:25:05在人類的不懈努力下,AI 越來越像人,連犯的錯誤都像。
過去幾年中,被喻為“新電力”的人工智能已經走出科幻小說,成為新一代”網紅“。

這里稱其“網紅”,并不是想貶低那些鉆研數十載的 AI 科研者。畢竟,沒有他們在人工智能這一計算機科學分支領域的不懈耕耘,就不可能有后來成百上千個的域名以 .ai 結尾的初創公司拿到巨額風險投資。
機器能思考嗎?
回顧人工智能八十年來的發展歷程,始終沒有逃離艾倫?圖靈 1950 年的那個問題:機器能思考嗎?1955 年,人工智能(artificial intelligence)一詞橫空出世。次年,十名科學家天真地預想用兩個月的時間搞清楚這個問題。
即便棋藝卓越的 AlphaGo 也不敢說自己會思考。抱歉,AlphaGo 甚至還不會說話。面對這個依舊無法回答的未解之謎,你或許可以引用另一個計算機科學家戴客斯特拉(Dijkstra)的話反問:“潛艇會游泳嗎?”
人工智能的奇點與盲點
談起人工智能,一千個人及媒體眼中就有一千種定義。毫無疑問的是,深度學習領銜的“機器學習幫”讓機器變得更聰明了。
目前,從圖像識別、語音識別、自然語言理解到機器翻譯等,深度學習一度成為人工智能領域研究的寵兒。自 2012 年,Krizhevsky 等人利用卷積神經網絡(CNN)大幅提升了計算機視覺的識別能力,一個新時代的開始。

Nick Bourdakos 在一篇博客里用好萊塢巨星卡戴珊的照片進行了簡易說明 CNN。作為圖像分類領域最先進的方法之一,CNN 通過將每一層神經網絡對應的特征累積起來進行對象識別。整個過程中,所有特征的空間關系就會丟失。
當我們把 CNN 看做是“如果有兩只眼睛、一個鼻子和一個嘴巴,它就是一張臉”的程序,就會出現以下問題:

這當然不是一張臉了,但是 CNN 就會說“這是一張臉”。有趣的地方就在于如果我們知道機器只會把“兩只眼睛、一個鼻子和一張嘴”看成一張臉,是不是就可以欺騙機器呢?
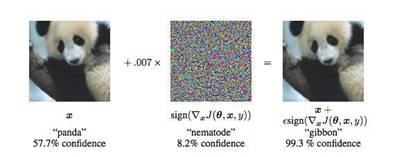
早在 2013 年,Christian Szegedy 等人發現在數據集中故意添加細微干擾形成的輸入樣本,能夠讓判別模型輸出一個錯誤結果。他們稱之為“對抗樣本”(Adversarial examples)。
通過制造對抗樣本,研究者讓機器從圖中是熊貓的可能性大約 57.7%,變為相信圖中是長臂猿的可能性高達 99.3%。這不僅僅是機器的一個錯覺,但是一個非常“確定”的錯覺。
2015 年,谷歌大腦人工智能科學家 Ian Goodfellow 等人發現模型的線性特征導致其對對抗樣本產生了脆弱性。
盡管不同模型使用的結構不同,但是因為學習了相似的函數,造成了一種模型的對抗樣本在另一個模型上也會被錯誤分類。
2016 年,Ian Goodfellow等人發現將圖像打印出來之后對抗樣本依舊具有“對抗性”,能夠讓分類器將小鳥照片識別成飛機。這讓“對抗樣本”不僅僅是紙上談兵,在現實中也會造成影響。

2017 年,麻省理工學院的Anish Athalye 等人讓 3D 打印出的真實物體也能欺騙深度網絡分類器。一個烏龜玩具被谷歌識別系統看成了來復槍。

加州大學伯克利分校的李博等研究者利用小貼紙在交通標識牌上進行一些微小的“裝飾”,就讓圖像識別系統 100% 產生錯誤判斷。試想如果這是一輛行駛中的自動駕駛汽車, 那么別有用心的人隨時都能制造一起車禍。

2018 年,谷歌大腦研究者生成了能夠同時愚弄人類和機器視覺對抗性圖像。潘多拉的魔盒已經打開,更有激進的日本研究者僅僅通過修改 1、3、5 個像素就達到欺騙 DNN 模型的成果。
拿什么防御“對抗樣本”?
機器學習模型無疑有著廣泛的攻擊面,賓夕法尼亞州立大學 Nicolas Papernot 博士說:“無論是用何種機器學習模型,也不論需要解決哪些任務,這類通用攻擊都會經常發生。”

2017 年加州大學伯克利分校博士生 Nicholas Carlini 在一篇論文中,“攻破”了 10 個不同的針對“對抗攻擊”的防御計劃。此前 Ian Goodfellow歸納可以通過對抗訓練(adversarial training)和差分隱私(differential privacy)進行防御,而迄今為止,依然沒有一種完整的解決方法能夠有效阻止“對抗樣本”攻擊。
2018 年,MIT 和 UC Berkeley 的研究者指出當下大部分對抗樣本防御方法依賴于“混淆梯度”(obfuscated gradients)現象,即通過提供錯度的梯度給攻擊者而讓基于梯度的對抗樣本失效,從而達到防御。來自 MIT 的Athalye 宣稱 ICLR(一場頂級機器學習大會)接收的論文中,八篇關于防御的論文(實際有十一篇)其中有七篇已經被他們攻破,其中不乏來自谷歌、亞馬遜及斯坦福等機構。
卡內基梅隆大學教授 Zachary Lipton 表示,對抗樣本針對所有現有的防御措施都可以避開的情況,是合理的。加州大學伯克利分校的博士后李博則認為具備更接近人類視角的機器或許會減少幻覺影響,他們正在與神經科學家、生物學家展開合作。
深度學習的先驅研究人員之一、現就職于谷歌的 Geoff Hinton 在 2017 年提出“膠囊網絡”(Capsule Networks)的概念。神經網絡需要依賴海量數據進行學習,很長時間才能認識到從不同角度觀察的對象是同一個物體。相比之下“膠囊網絡”是一種人造神經元組成的層,跟蹤物體的各個部分之間的關系讓識別更快更準確。

現有的研究結果已經證明“膠囊網絡”對對抗樣本具有“抗性”,比 CNN 的錯誤數量減少了 45%。然而“膠囊網絡”就是治療“對抗樣本”的良藥嗎?
GeekPwn 黑客大賽:百萬獎金池,鼓勵AI 黑客火力全開

為了推進 AI 安全領域的研究,通過對抗樣本推動AI的不斷成長,率先關注 AI 安全的世界黑客大賽 GeekPwn(極棒)聯合谷歌大腦、加州大學伯克利分校 EECS 頂級專家創辦了首屆 CAAD 對抗樣本攻防賽(Competition on Adversarial Attacks and Defenses),官網地址 caad.geekpwn.org。
2018 年,CAAD 將聚焦機器學習圖像識別領域的安全攻防對抗研究,特設非定向對抗攻擊、定向對抗攻擊、對抗攻擊的防御三個挑戰類別。官方報名通道及詳細規則將于五月開啟公布,獲勝選演示及頒獎會在八月 GeekPwn 拉斯維加斯站舉行。本次大賽設立了15萬美元的總獎金池,鼓勵廣大 AI 研究者加入到安全對抗的領域中,做未來的安全守護者。
自 2016 年以來,GeekPwn 黑客大賽注意到人工智能存在的潛在安全隱患,陸續推出了 AI PWN、PWN AI、“AI 仿聲驗聲攻防賽”等區別于傳統的黑客攻防挑戰的前沿比賽項目。2018年GeekPwn大賽非命題的項目報名也已同步開啟,總獎金池500萬人民幣,選手可以自由選擇挑戰對象,任意 AI 產品、服務甚至是 AI 框架;亦或使用 AI 技術作為工具進行黑客破解或者利用。詳細的參賽指引可查閱官網www.geekpwn.org。
在歷屆極棒比賽中,“AI PWN”選手曾利用 3D 打印機和深度學習算法寫出足以騙過專業筆跡鑒定師的仿真字跡;“PWN AI”選手通過 CNN 算法兩分鐘破解谷歌 reCAPTCHA 圖形驗證碼;多組參加了“AI 仿聲驗聲攻防賽”的團隊僅僅通過 20 分鐘的音頻就能生成足以突破AI聲紋鎖的語音片段……

為更深層次挖掘AI服務安全的未來價值,GeekPwn也在策劃全新的“數據追蹤挑戰賽”。能夠多維度將不同來源的數據關聯并得出準確結果是一種先進的技術。例如,通過爆破地點的數據、匿名舉報電話以及社交媒體等信息結合追蹤炸彈制造者;對歷史記錄、海量數據充分分析之后發現金融騙局;通過分析大量代碼,找到編程者等等。數據追蹤挑戰賽挑戰要求選手通過主辦方提供的數據集運用 AI 等工具進行分析研究,并最終完成指定目標。
當越來越多的研究者關注 AI 安全領域并投入精力研究,未來 AI 發展才能更加穩健、更好地提供服務、創造價值。

關注GeekPwn獲取更多比賽信息