

網(wǎng)絡(luò)釣魚技術(shù)之HTML走私
責(zé)編:gltian |2021-06-22 10:58:27
前言
今天介紹一種走私技術(shù),HTML Smuggling,這不是一種特別新的攻擊方法,但是它確實在越來越多的攻擊場景中出現(xiàn),其中就包括網(wǎng)絡(luò)釣魚。接下來我們就來了解一下HTML走私的來龍去脈以及它在釣魚中是怎樣被利用的吧。
HTML走私介紹
什么是HTML走私?HTML走私是指,瀏覽器根據(jù)HTML文件的內(nèi)容在主機上創(chuàng)建惡意文件,而不是直接轉(zhuǎn)發(fā)/下載惡意軟件的一種技術(shù)。HTML走私可以通過在HTML頁面中將惡意文件隱藏為編碼后的“string”來繞過外圍安全性檢查和在線檢測。
大多數(shù)周邊/在線安全檢測方法都是通過匹配文件中的某些特定模式。但在HTML走私的情況下,惡意文件被嵌在瀏覽器中,所以檢測這樣隱藏的代碼是困難的。而且由于代碼中的混淆,甚至檢測HTML走私這種情況本身也很困難。
利用方法
在去年也就是2020年的網(wǎng)絡(luò)釣魚調(diào)查中,我遇到了兩種本質(zhì)上不同的HTML走私方式。這兩種方案都將數(shù)據(jù)存儲在HTML文件中,并且提供了無需向服務(wù)器發(fā)送額外請求就可以“下載”數(shù)據(jù)的方法。此外,這兩種方案都是基于HTML5的下載屬性(雖然不是強制性的但是有好處)。
Javascript Blob
先介紹第一種方案,基于JavaScript Blob,也是我經(jīng)常看到的方案。Blob對象表示一個不可變、原始數(shù)據(jù)的類文件對象。它的數(shù)據(jù)可以按照文本或二進制的格式進行讀取,也可以轉(zhuǎn)換為ReadableStream來讀取。借助Blob,我們可以將我們的惡意文件存儲在HTML代碼中,然后將其置入瀏覽器中,而不是直接向Web服務(wù)器發(fā)送文件上傳請求。
我們可以通過下面兩個鏈接來創(chuàng)建我們的HTML頁面:
https://gist.github.com/darmie/e39373ee0a0f62715f3d2381bc1f0974
要存儲文件,首先,需要將文件編碼為base64,可以在PowerShell中使用一下代碼來實現(xiàn):
$base64string = [Convert]::ToBase64String([IO.File]::ReadAllBytes($FileName))
然后替換下面html文件中<>所指的值。fileName變量表示你希望在默認情況下下載文件的名稱。base64_encoded_file變量存儲base64編碼后的文件。
<html>
<body>
<script>
var fileName = <>
var base64_encoded_file = <>
function _base64ToArrayBuffer(base64,mimeType) {
var binary_string = window.atob(base64);
var len = binary_string.length;
var bytes = new Uint8Array( len );
for (var i = 0; i < len; i++) {
bytes[i] = binary_string.charCodeAt(i);
}
return URL.createObjectURL(new Blob([bytes], {type: mimeType}))
}
var url = _base64ToArrayBuffer(base64_encoded_file,'octet/stream')
const link = document.createElement('a');
document.body.appendChild(link);
link.href = url;
link.download = fileName;
link.innerText = 'Download';
</script>
</body>
</html>
現(xiàn)在只要我們點擊上面的鏈接,就會開始下載步驟。
DataURL
實現(xiàn)HTML走私的另一種方案是使用DataURL。這種解決方案就不需要使用JavaScript了。使用DataURL進行HTML走私的目標就是將較小的文件嵌入HTML文件中。
雖然上面強調(diào)了小文件,但是實際上,限制也不是很嚴格。DataURL的最大長度由瀏覽器中的最大URL長度決定。比如,在Opera中,這個大小是65535個字符,雖然這個字節(jié)數(shù)對于轉(zhuǎn)移1080p的電影來說是遠遠不夠的,但是用來反彈shell已經(jīng)足夠了。
這種方法比第一種基于JS Blob的要簡單得多。先看一下語法:
data:?:前綴;
[<mediatype>]:可選項,是一個MIME類型的字符串,比如我們最常見的image/jpeg表示JPEG圖像,如果缺省,默認值為text/plain;charset=US-ASCII;
[;base64]:可選項,如果數(shù)據(jù)是base64編碼的,那么就用;base64標記
,:將數(shù)據(jù)與控制信息分開;
<data>:數(shù)據(jù)本身。
<html>
<body>
<a href="data:text/x-powershell;base64,aXBjb25maWcNCmhvc3RuYW1l"
download="test.ps1">
Download
</a>
</body>
</html>
這是一個簡單的HTML例子,加載該頁面的時候會顯示一個download按鈕。我們點擊下載,瀏覽器就會將test.ps1文件保存到我們的電腦上。而寫入的內(nèi)容自然就是aXBjb25maWcNCmhvc3RuYW1l?base64解碼后的內(nèi)容。
發(fā)現(xiàn)了一個比較有意思的事情。當(dāng)講將<a>標簽中的download去掉后,也就是變成了下面的樣子:
<html>
<body>
<a href="data:text/x-powershell;base64,aXBjb25maWcNCmhvc3RuYW1l" >
Download
</a>
</body>
</html>
我們重新在Chrome瀏覽器中打開并嘗試下載,這個時候發(fā)現(xiàn),這個按鈕已經(jīng)失效了,點擊不會有任何反應(yīng)。但是用Firefox打開,依舊可以下載文件,只不過firefox會創(chuàng)建一個隨機的文件名,并且保存的文件不會有后綴:
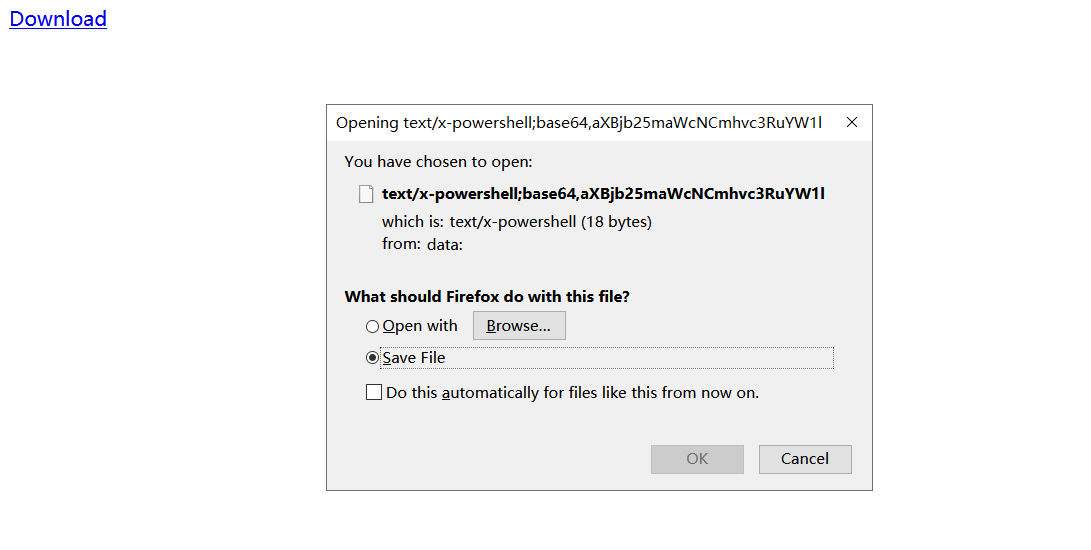
綜上,我們可以將DataURL和JS Blob相結(jié)合來添加一個函數(shù),當(dāng)然我們可以不適用任何腳本,但是和上面的例子中的問題一樣,顯然會更到更多的限制。
為什么攻擊者會使用HTML走私?
HTML走私是釣魚攻擊一個很好的補充。在HTML走私的幫助下,攻擊者可以逃避一些檢測和記錄機制。在這種方式下,文件被“注入”到HTML文檔中,而絕大多數(shù)的安全解決方案根本不會去檢測。
當(dāng)然HTML走私也有一些缺點。首先,它需要用戶交互,雖然瀏覽器會自動處理惡意文件,但是下載到用戶主機還是需要用戶同意,除非配置了未經(jīng)用戶確認的自動下載。而且即使文件被下載了,還是需要將其執(zhí)行。
利用HTML走私來釣魚
上面介紹了兩種常見的HTML走私方法,回到文章的主題,如何利用HTML走私來進行釣魚呢?這里介紹兩種比較常見的方法。首先,第一種是讓電子郵件包含一個指向外部網(wǎng)頁的鏈接,而該指向的網(wǎng)頁使用了HTML走私技術(shù)。這是比較常見的郵件釣魚方式。另一種方法是,在電子郵件中添加一個HTML附件,該HTML文件走私了惡意代碼,這種情況下,用戶打開的就是本地的HTML文件,不需要訪問外部站點。
在這兩種情況下,好處是惡意內(nèi)容很難被檢測到,因為惡意代碼隱藏在HTML內(nèi)容中。通過這種方式,可以繞過很多道安全防御。
正常文件下載
首先,我們來看一下正常的文件下載步驟是怎樣的。在下圖的例子中,用戶訪問一個網(wǎng)站,然后下載一個exe文件:
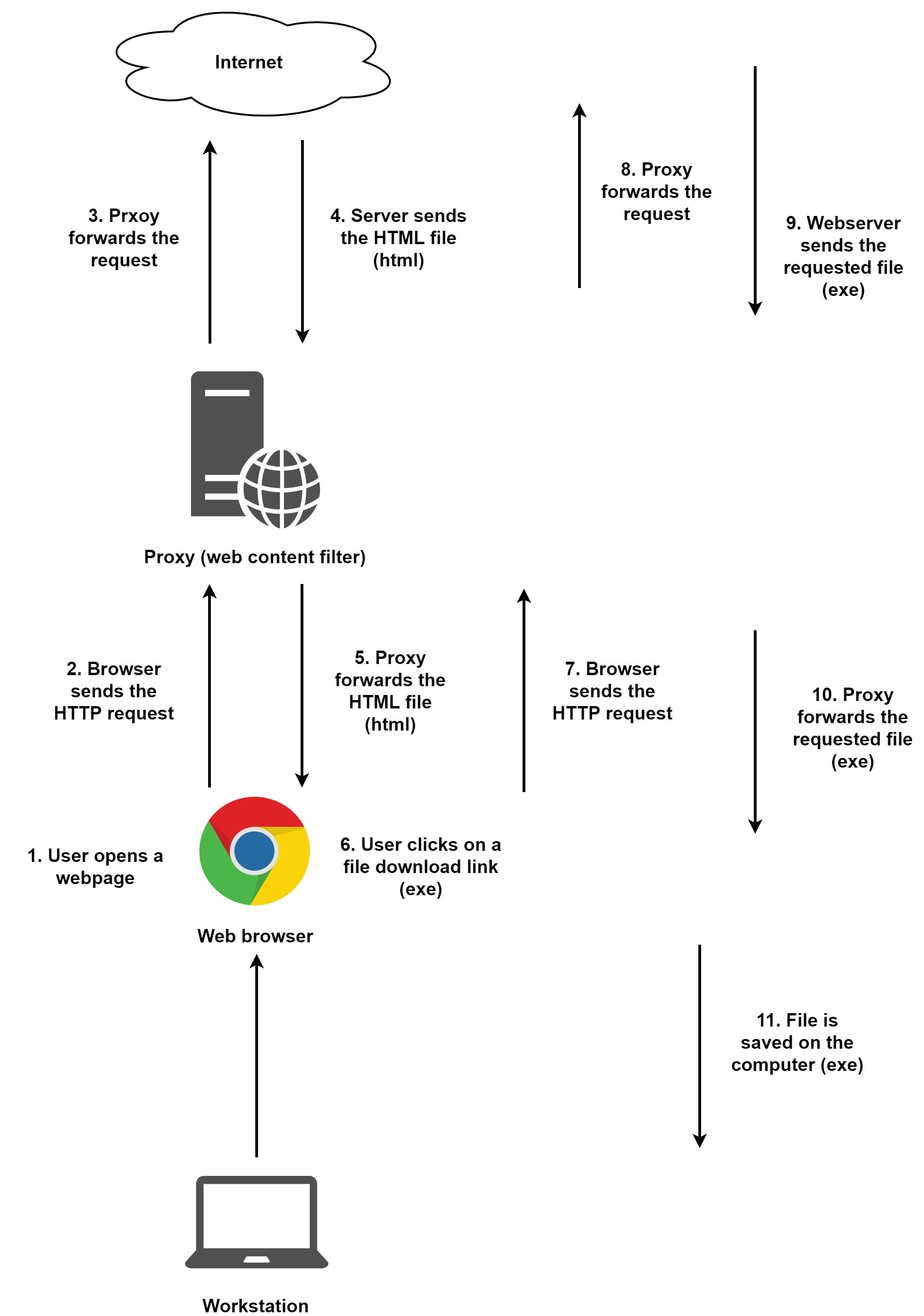
1 . 首先,用戶打開一個正常的網(wǎng)站。這個網(wǎng)站可以是用戶自己輸入的,也可以從包含鏈接的釣魚郵件中獲得。
2 . 瀏覽器向網(wǎng)站發(fā)送HTTP請求。如果存在代理,那么這個流量就會走代理。
3 . 代理會檢查瀏覽器請求的URL。因為許多的代理都有檢查域信譽的能力,如果代理認為請求的域是惡意的,那么Proxy不會進行后續(xù)的請求,通信將在這一步就停止;反之,代理會將請求轉(zhuǎn)發(fā)給Web服務(wù)器。
4 . Web服務(wù)器返回請求的資源給代理,在本例中,Web服務(wù)器返回的就是一個普通的HTML頁面。
5 . 代理檢查Web服務(wù)器的響應(yīng)。在這一步會進行各種過濾。代理可以阻止用戶下載一些類型的文件。此外,代理可以有一個內(nèi)置的沙箱來測試文件是否安全,而HTML文件通常不會再沙箱中進行測試就被允許通過代理轉(zhuǎn)發(fā)給用戶。
6 . 頁面通過代理轉(zhuǎn)發(fā)給瀏覽器。此時判斷文件可信度的角色就變成了用戶,用戶可以決定瀏覽器中顯示的某個文件是否安全,如果用戶信任,就可以進行文件下載,在本例中,該文件是一個exe文件。
7 . 瀏覽器向Web服務(wù)器發(fā)送文件下載請求。
8 . 代理的處理和之前相同,這一步?jīng)]什么區(qū)別。
9 . Web服務(wù)器將請求的exe文件發(fā)送給代理。
10 . 當(dāng)代理獲得該exe文件時候,它會對其進行綜合性評估。如果設(shè)置了網(wǎng)絡(luò)中禁止下載exe文件,那么顯然,exe下載請求在這一步就結(jié)束了,文件將無法到達用戶的機器。代理還會檢查文件是否是已知的惡意文件。此外,它還可以決定是不是要將文件放到沙箱中進行測試。這里有一個關(guān)鍵點,當(dāng)代理知道這個文件是一個可執(zhí)行文件時候,它可以決定是不是要繼續(xù)轉(zhuǎn)發(fā)。而且,網(wǎng)絡(luò)分路器(Network Taps)可以檢測到這個exe文件,如果它們認為該文件是惡意的,也可以阻止用戶下載該文件。
11 . 如果一切順利,那么文件就到達了它的最終目的地——用戶的電腦。
在上面的步驟中,最重要的一步就是第10步。這一步有普通文件下載和HTML走私下載的最大區(qū)別。在正常下載的情況下,exe文件易于檢測和評估(比如檢查散列,沙箱執(zhí)行檢查,收集頭文件信息來判斷等等)。而在HTML走私的情況下,文件不會以一種未編碼的方式在網(wǎng)絡(luò)上傳播,它總是會被嵌入到另一個HTML文件中。
通過e-mail中的外部鏈接
首先,先介紹一種很常見的走私技巧。在這種情況下,攻擊者會將事先準備好的鏈接放入電子郵件中。該鏈接會指向包含走私文件的外部鏈接。在這種情況下,惡意的內(nèi)容不會通過電子郵件的網(wǎng)關(guān),而是以隱藏的形式,通過代理被用戶訪問。
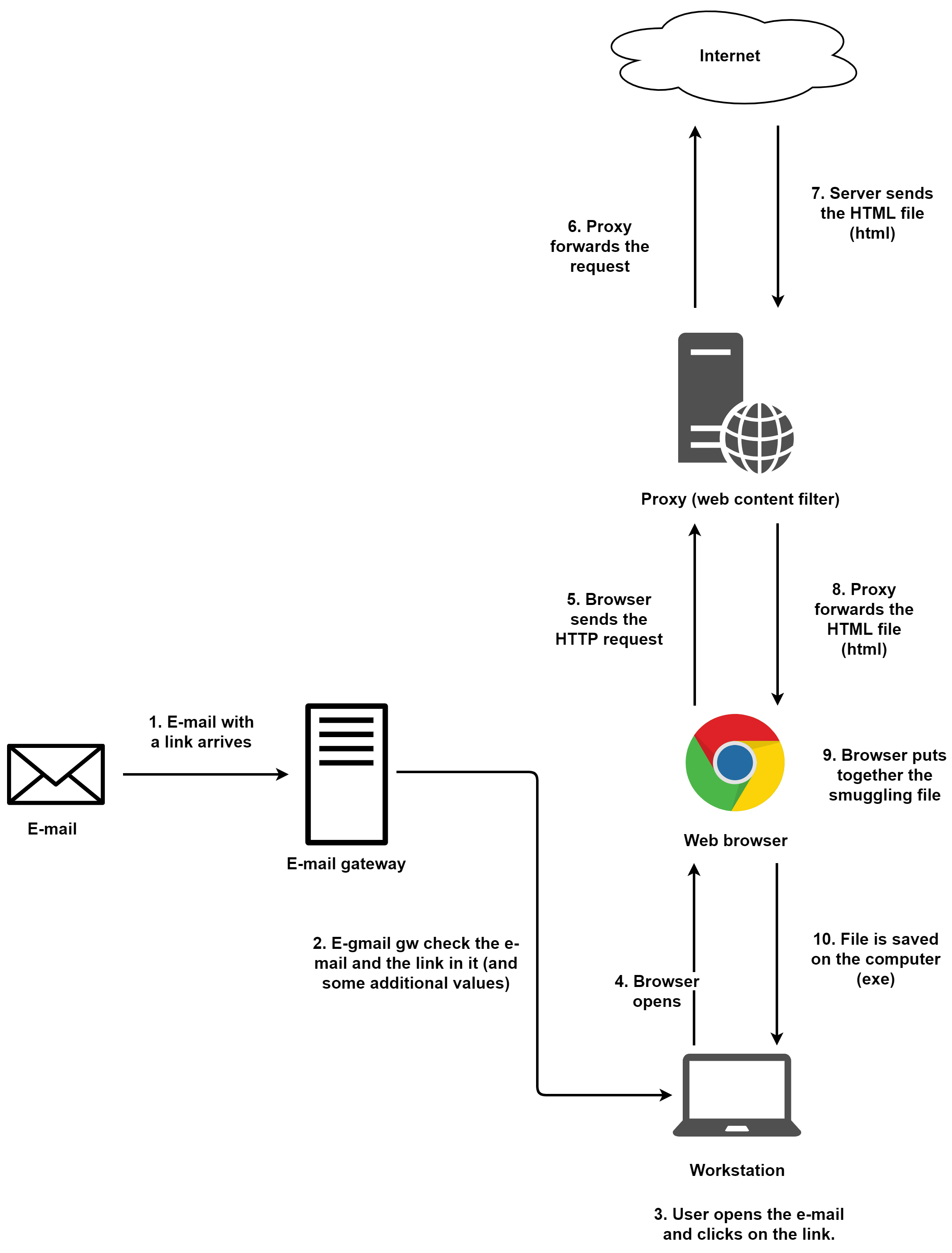
1 . 有一個帶著外部鏈接的e-mail向目標用戶發(fā)送。
2 . 郵件網(wǎng)關(guān)對郵件進行檢查。在這一步有很多種檢查方法,但在本例的場景下,我們就認為郵件網(wǎng)關(guān)并不會阻攔該郵件,因為這里沒有包含什么惡意文件。
3 . 用戶點擊郵件中的鏈接。
4 . 默認瀏覽器啟動。
5 . 瀏覽器向存儲(或是生成)HTML文檔的外部站點發(fā)送HTTP請求。
6 . 代理會進行一些必要的檢查,但是如果該URL并沒有被加入黑名單,那么該請求就會被轉(zhuǎn)發(fā)到該站點所對應(yīng)的服務(wù)器。
7 . 服務(wù)器返回HTML頁面以及隱藏在其中的exe文件。exe文件是以字符串的形式存儲在文檔中,此時它已經(jīng)變成了HTML內(nèi)容的一部分。
8 . 代理會檢查響應(yīng)內(nèi)容。在本例中,響應(yīng)只是一個HTML文件,代理不會去攔截HTML文件。而且,HTML文件在絕大多數(shù)情況下不會被轉(zhuǎn)發(fā)到沙箱中執(zhí)行檢查。因而,隱藏在HTML文檔中的惡意內(nèi)容幾乎不會在這里被檢測到。當(dāng)然通過其他的檢測技術(shù),它們也可能能識別到HTML走私技術(shù)(但是這里指的也只是HTML走私這件事本身,而不是隱藏在HTML中的惡意文件)。現(xiàn)在我們就認為代理沒有識別出這個情況,將響應(yīng)HTML頁面轉(zhuǎn)發(fā)給瀏覽器。
9 . 瀏覽器重新拼接嵌入在HTML頁面中的字符串,然后啟動下載進程。
10 . 最后惡意exe文件被存儲到用戶的電腦上。
我們可以看到,在這種情況下,e-mail的安全檢查機制并不能起到太大的作用。因為電子郵件本身不是惡意的,其中的鏈接可以是合法的鏈接。
代理當(dāng)然可以查看HTML文件,但是很少有安全性檢測方案會對HTML文件進行徹底地處理。大多數(shù)情況下,這些文件都是被允許通過代理的。IDS解決方案還傾向于依賴檢測文件擴展名或是magic bytes(主要是通過分析文件的第一個字節(jié)來判斷文件的類型),因此文件中的編碼字符串很難被它們捕獲。但是其實我們可以創(chuàng)建一個模式匹配解決方案來檢測一些隱藏在HTML中的東西。這在后面會提到。
通過電子郵件中的HTML附件
這種方法是指包含走私的HTML文件被附加到了電子郵件中。
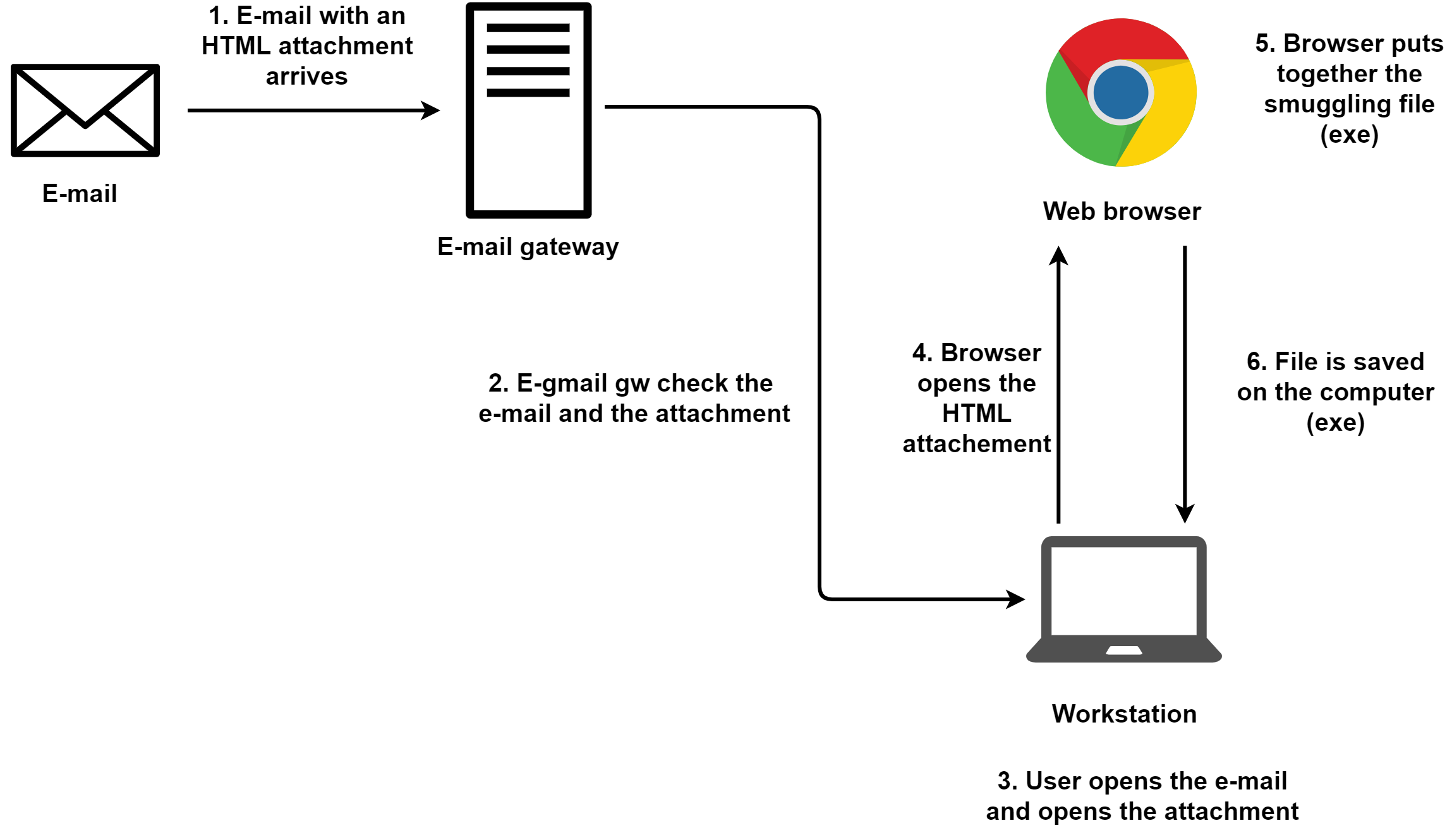
1 . 郵件網(wǎng)關(guān)收到一份帶有HTML附件的電子郵件。
2 . 郵件網(wǎng)關(guān)會對電子郵件中附帶的HTML進行檢查。如果檢查未通過,那么郵件網(wǎng)關(guān)會阻擊電子郵件的后續(xù)轉(zhuǎn)發(fā)或者選擇刪除附件。但是,現(xiàn)在還沒有聽說過什么電子郵件安全解決方案能夠通過靜態(tài)分析或者動態(tài)分析來檢測HTML走私(即使是在HTML走私的是惡意代碼。)
3 . 用戶打開HTML附件。
4 . 瀏覽器打開并加載HTML文檔。
5 . 瀏覽器處理HTML文件的內(nèi)容,處理被走私的文件并將其提供給用戶下載。
6 . 文件被保存到計算機上。當(dāng)然,在這一步,要么需要用戶的批準,要么需要瀏覽器設(shè)置了自動下載,就是未經(jīng)確認的下載。
這種方法相比上一種的好處就在于,它不需要通過任何代理。而且,網(wǎng)絡(luò)上的IDS/IPS安全檢查通常不會去檢查電子郵件,所以,如果攻擊者能夠成功欺騙電子郵件網(wǎng)關(guān),那么在網(wǎng)絡(luò)上就沒有其他的難處了。
防御與檢測
在這一小節(jié)中我們來探討一下如何防御與檢測HTML走私。
在發(fā)生了HTML走私的情況下,我們可以有兩種檢測方式,我們要么就關(guān)注HTML走私技術(shù)本身,要么可以嘗試捕獲隱藏在HTML文檔中的惡意代碼。
防御方法
這里介紹幾種防御方法。
1. 禁止JavaScript執(zhí)行
雖然對于HTML走私?jīng)]有什么萬能的防御辦法。禁用JavaScript看起來是一種可行的方案,畢竟一種HTML走私技術(shù)就是基于JavaScript Blob的,但是,在企業(yè)環(huán)境中禁用JS肯定會帶來很多問題。當(dāng)然,如果在你遇到的顯示場景中,禁用JS是可行的,那么也可以嘗試這種方法,那么在這個時候,你只需要用模式匹配去識別DataURL是不是存在HTML走私情況就好。
2. 禁止郵件中的HTML附件
HTML走私的一種類型是使用HTML文件作為附件。不幸的是,這在很多場景中都是常見的,實際上,現(xiàn)在有很多帶有HTML附件的合法的、與業(yè)務(wù)相關(guān)的電子郵件在增加。另一方面,不法分子也利用HTML附件來進行釣魚。
如果你能在不影響業(yè)務(wù)的情況下阻止帶有HTML附件的郵件,那么對于利用郵件中帶有的HTML來進行釣魚的路就被堵住了。那此時我們只需要關(guān)注郵件中附帶的鏈接了。
我們可以看到,前面這兩種防御方法都無法同時覆蓋所有的HTML走私情況。在最好的情況下,我們可以使用這兩種方案來防住部分HTML走私;在最壞的情況下,我們甚至都不能使用這些防御解決方案,因為這些方案在大多數(shù)現(xiàn)在企業(yè)環(huán)境中是不適用的。
3. Windows應(yīng)用程序防護(Microsoft Defender Application Guard)
Microsoft Defender Application Guard是Windows提供的一種安全解決方案,主要用于隔離各種試圖使用來自不可信源資源的應(yīng)用程序,后面簡稱MDAG。MDAG有兩種不同的形式。第一種是Application Guard for Edge,它主要是用來隔離企業(yè)定義的不受信任(或不特別受信任)的站點,在企業(yè)的員工瀏覽Internet時保護公司。Application Guard通過在一個啟用了Hyper-V的隔離容器中打開站點來實現(xiàn)這一點。而且,它還與Firefox和Chrome瀏覽器兼容。
另一個版本是Application Guard for Office。它能夠保護可信資源不受不可信資源的攻擊。它也是通過在一個容器中打開不受信任的Word、Excel、PowerPoint文檔來實現(xiàn)。當(dāng)然,這也和HTML走私無關(guān),所以就不繼續(xù)討論了。
Application Guard for Edge
我們已經(jīng)知道,Application Guard for Edge主要是通過在隔離的虛擬環(huán)境中打開不受信任的鏈接來保護我們的系統(tǒng)。如此一來,一個未知的URL,或者說是一個惡意的URL就不會對主機造成危害了。下載的惡意文件會被隔離存儲在隔離的環(huán)境中,而不會直接與宿主機接觸。
如果一個鏈接在電子郵件中到達,并且給定的URL并不在Application Guard的白名單中,那么它就會在一個隔離的Edge中被打開。因為對于該URL的訪問是在隔離的環(huán)境中進行的,那么每個文件下載行為也都是在這個隔離的環(huán)境中進行的,因此被走私的惡意文件不會對主機造成真實傷害。
當(dāng)然,這個解決方案也并不是十全十美的。它也有一些缺點:
1 . 為了使Edge能發(fā)揮作用,你需要使用白名單和untrust來標記一切網(wǎng)站。這在大公司中,意味著相關(guān)的管理員需要承受巨大的負載。因為用戶會不斷地進行異常請求。
2 . 雖然Application Guard能夠防住以鏈接形式附在電子郵件中的HTML走私請求,但是它無法防御以電子郵件附件形式傳遞的HTML走私。這些附件到達用戶主機后,會作為本地文件在瀏覽器中打開,因此,這些文件不會被當(dāng)作不受信任的域來處理,不會在隔離的Edge容器中打開這些HTML文件,也就不會觸發(fā)Application Guard。因此通過電子郵件附件進行的HTML走私在這種情況下依然可以成功。
3 . 會影響用戶訪問站點的速度,因為需要啟動容器。
檢測方法
1. 模式匹配
如果HTML文件中沒有利用JS來走私,而是僅僅使用了DataURL,在這種情況下,我們可以使用模式匹配(比如匹配data:)來判斷是不是發(fā)生了HTML走私。我們可以實用IDS或是簡單的YARA工具來檢測,比如github上的開源工具LaikaBOSS就是一款可用的檢測工具。
KaikaBOSS對于下載的文件(HTML文件),甚至是電子郵件附帶的文件,都非常有效。它可以檢測大量的數(shù)據(jù),伸縮性很好,所以即使在大型環(huán)境中,也同樣可以派上用場。
如果使用了JavaScript,那么可能代碼是被混淆過的,此時模式匹配可能就不太有效果了。我們只能用其他的方法來檢測混淆的代碼。
2. 檢測瀏覽器是否通過網(wǎng)絡(luò)下載文件
在使用了HTML走私的場景下,被下載的文件是在瀏覽器中創(chuàng)建的,而在一般的下載場景中,我們可以看到,是需要我們向Web服務(wù)器發(fā)起請求,然后Web服務(wù)器傳送給我們的,而且還會經(jīng)過代理,經(jīng)由代理檢查文件的安全性。因此我們還可以通過關(guān)注普通文件下載和基于HTML文件創(chuàng)建下載文件之間的區(qū)別來鑒別HTML走私。因此我們可以通過查看代理日志、觀察是否有瀏覽器進行在主機上創(chuàng)建文件等方式來查看是不是發(fā)生了HTML走私。
這種方式的缺點在于:
1 . 許多流量在默認情況下不會通過代理。比如,一些公司會配置它們的網(wǎng)絡(luò),使其內(nèi)部網(wǎng)站無法通過代理訪問。這個時候,如果通過瀏覽器生成了一個文件,但是沒有代理日志。這種情況經(jīng)常發(fā)生,不應(yīng)該基于這種情況創(chuàng)建警報。
2 . 在一些情況下,用戶可以繞過代理,也不會產(chǎn)生代理日志。
3 . 可以在瀏覽器中打開本地文件,然后保存為新文件,這也是瀏覽器創(chuàng)建的文件,同樣沒有代理日志。
如果用戶是在上面的情況下進行合法行為,我們都不應(yīng)該進行攔截,因此難點就在于我們很難區(qū)分這是不是一種走私情況。
3. 沙箱執(zhí)行
您可以將HTML文件發(fā)送到沙箱,然后使用沙箱中的瀏覽器打開它。不是通過互聯(lián)網(wǎng)訪問的HTML文件除了一些臨時文件之外,不應(yīng)該在機器上創(chuàng)建任何文件。理論上,如果在沒有網(wǎng)絡(luò)訪問的情況下,HTML文件在沙箱中創(chuàng)建了文件,那么沙箱應(yīng)該要發(fā)出一個警報來提醒用戶。
但是,經(jīng)驗表明,HTML文件通常不會放到沙箱中打開。它們可以通過靜態(tài)分析進行檢查(如LaikaBoss),也可以動態(tài)分析進行檢查,但是動態(tài)分析將花費更多的時間,并且會顯著降低網(wǎng)絡(luò)速度。
但是沙箱這個解決方案在大多數(shù)的情況下不是特別友好,因為在轉(zhuǎn)發(fā)給用戶之前打開每個HTML文件負載也挺大的。而且,如果惡意文件是需要用戶點擊下載的,那么這種方式也行不通,只有在頁面配置了自動下載的情況下,我們才能通過沙箱來檢測。所以總體來說,這也不是一個特別好的方法。
4. 使用Zone.Identifier
另一種方式是使用取證分析中可能會使用的技術(shù)——Zone.Identifier來區(qū)分是不是發(fā)生了HTML走私。
由HTML走私創(chuàng)建的文件的Zone.Identifier是這樣的(在新版Edge、Chrome和Firefox測試過):
[ZoneTransfer]
ZoneId=3
HostUrl=about:internet
而正常下載的文件的Zone.Identifier則是(這在不同的瀏覽器之間存在區(qū)別):
[ZoneTransfer]
ZoneId=3
ReferrerUrl=https://www.sans.org/security-resources/posters/windows-forensic-analysis/170/download
HostUrl=https://www.sans.org/security-resources/posters/windows-forensic-analysis/170/download
這種方法的局限就在于,它只能在Windows(NTFS)上這樣做。因此這種方式也不是完全可靠的。
5. Chrome組件
Chrome會存儲下載文件的來源,如果源是JavaScript Blob或是DataURL,那么這些信息就會作為源顯示。
當(dāng)我們打開一個本地的HTML被走私文件:

當(dāng)然上面的信息不會告訴我們該被走私的惡意文件是從哪里下載的。
當(dāng)我們訪問遠程的走私HTML文件時,我們就可以看到相應(yīng)的惡意文件下載URL了,但是也僅僅是在走私文件是使用了JS Blob時能看到,在使用DataURL時則不會顯示遠程鏈接:

這種情況相比前面的幾種方法看起來更加實用。在遠程訪問,并使用了JS Blob的情況下,我們甚至能看到惡意文件的真實來源,如果攻擊者使用了DataURL,我們還可以利用這個信息重新生成文件,這在一些場景下可能也是有用的。
總結(jié)
總體來說,目前想要完全檢測和防御HTML走私是一件比較困難的事情。當(dāng)然,上面介紹的方法也只是相對簡單地介紹了HTML走私下的釣魚事情,在現(xiàn)實攻擊場景中,可能會遇到更復(fù)雜的情況。
來源:安全客
- ISC.AI 2025正式啟動:AI與安全協(xié)同進化,開啟數(shù)智未來
- 360安全云聯(lián)運商座談會圓滿落幕 數(shù)十家企業(yè)獲“聯(lián)營聯(lián)運”認證!
- 280萬人健康數(shù)據(jù)被盜,兩家大型醫(yī)療集團賠償超4700萬元
- 推動數(shù)據(jù)要素安全流通的機制與技術(shù)
- RSAC 2025前瞻:Agentic AI將成為行業(yè)新風(fēng)向
- 因被黑致使個人信息泄露,企業(yè)賠償員工超5000萬元
- UTG-Q-017:“短平快”體系下的高級竊密組織
- 算力并網(wǎng)可信交易技術(shù)與應(yīng)用白皮書
- 美國美中委員會發(fā)布DeepSeek調(diào)查報告
- 2024年中國網(wǎng)絡(luò)與信息法治建設(shè)回顧