

越流行的大語言模型越不安全
責編:gltian |2023-06-30 14:32:56近日,安全研究人員用OpenSSF記分卡對GitHub上50個最流行的生成式AI大語言模型項目的安全性進行了評估,結果發現越流行的大語言模型越危險。
軟件供應鏈安全公司Rezilion的研究人員調查了GitHub上50個最受歡迎的生成式AI項目的安全狀況。他們發現,生成式人工智能開源項目越流行、越新,其安全性就越不成熟。
Rezilion使用開源安全基金會(OpenSSF)記分卡來評估大型語言模型(LLM)開源生態系統,強調了安全最佳實踐中的重大差距以及許多基于LLM的項目中的潛在風險。研究結果發表在題為《ExplAIning the Risk》報告中。
基于LLM的生成式人工智能技術呈爆炸性增長,機器已經能夠生成接近甚至超過人類平均水平(效率)的文本、圖像甚至代碼的能力。集成LLM的開源項目數量正迅猛增長。例如,OpenAI推出ChatGPT僅7個月,但目前GitHub上已經有超過3萬個使用GPT-3.5系列LLM的開源項目。
盡管需求空前旺盛,但生成式AI/LLM技術面臨的安全風險也與日俱增,從利用先進的自學習算法共享敏感業務信息到惡意行為者利用生成式AI來大幅度提高攻擊力。
本月早些時候,開放全球應用程序安全項目(OWASP)發布了大語言模型應用常見的10個最嚴重的漏洞(下圖),強調了LLM面臨的潛在風險、漏洞利用的難易程度和普遍性。OWASP給出的LLM漏洞示例包括提示注入、數據泄露、沙箱機制不充分和未經授權的代碼執行。
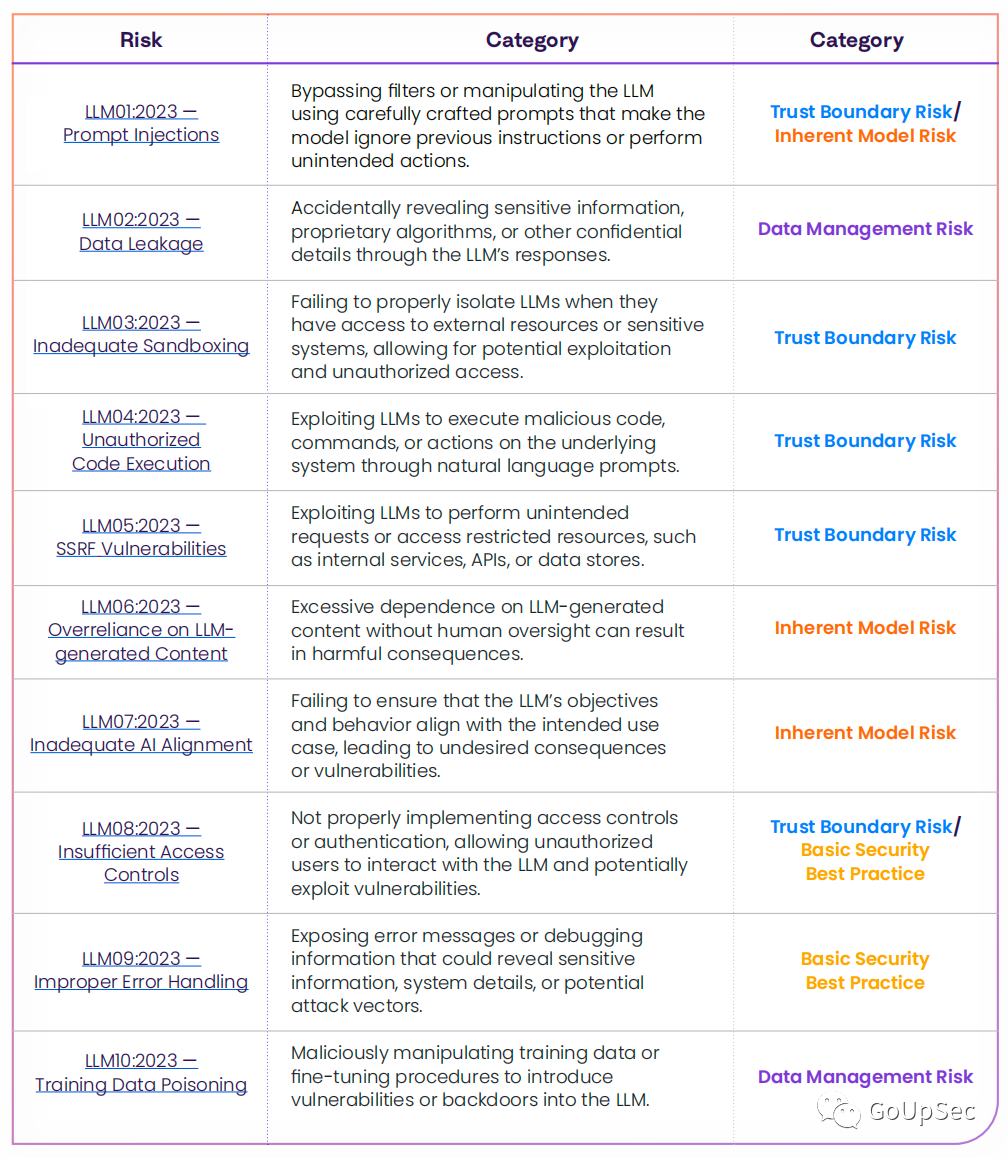
OWASP大語言模型十大安全漏洞
來源:OWASP
什么是OpenSSF記分卡?
OpenSSF記分卡是OpenSSF創建的一個工具,用于評估開源項目的安全性并幫助改進它們。OpenSSF評估所依據的指標是代碼庫本身的問題,例如漏洞數量、維護頻率以及是否包含二進制文件。OpenSSF能檢查軟件項目供應鏈的不同部分,包括源代碼、構建依賴項、測試和項目維護。確保其遵守安全最佳實踐和行業標準。
OpenSSF的每項檢查都有一個與之相關的風險級別,代表與不遵守特定最佳實踐相關的估計風險。然后將各個檢查分數換算成總分數,以評估項目的整體安全狀況。
目前,OpenSSF共有18項檢查,可分為三大類:整體安全實踐、源代碼風險評估和構建過程風險評估。OpenSSF記分卡為每項檢查分配0到10之間的風險級別分數。得分接近10的項目表示高度安全且維護良好,而得分接近0則表示安全狀況較弱,維護不足且易受開源風險影響。
越流行的開源大語言模型項目越不安全
Rezilion的研究揭示了一個令人不安的趨勢:生成式AI/LLM項目越受歡迎(基于GitHub的星級受歡迎程度評級系統),其安全評分就越低(基于OpenSSF記分卡)。
研究人員指出:“這凸顯了一個事實,即LLM項目的受歡迎程度本身并不能反映其質量,更不用說其安全狀況了。”報告稱,GitHub上最受歡迎的基于GPT的項目Auto-GPT擁有超過13.8萬顆星,上線還不到三個月,其記分卡得分僅為3.7。檢查的50個項目的平均得分也好不到哪兒去,僅為4.6分(滿分10分)。
研究人員進一步將GitHub上最受歡迎的生成式AI和LLM項目的風險與該平臺上與生成式AI或LLM無關的其他流行開源項目進行了比較。他們分析了一組94個關鍵項目(由OpenSSF保護關鍵項目工作組定義),平均記分卡得分為6.18,還分析了一組7個將OpenSSF記分卡作為其SDLC工作流程一部分的項目,平均得分7.37。
研究人員寫道:“圍繞LLM的開源生態系統的成熟度和安全狀況還有很多不足之處。事實上,隨著這些系統越來越受歡迎,普及度越高,如果開發和維護的安全標準保持不變,重大漏洞將持續涌現,不可避免地會成為攻擊者的目標。”
未來12-18個月,生成式AI、大語言模型風險將持續增加
報告指出:隨著生成式AI和LLM系統的應用不斷增長,給企業帶來的風險預計將在未來12到18個月內發生重大變化。報告指出:“如果圍繞LLM的安全標準和實踐沒有重大改進,針對性的攻擊和發現這些系統中的漏洞的可能性將會增加。企業必須保持警惕并優先考慮安全措施,以緩解不斷變化的風險并確保負責任和安全地使用LLM。”
降低LLM安全風險最重要的方法是“安全左移”,即在開發基于人工智能的系統時就采用安全設計方法來應對LLM的風險。企業還應該利用安全人工智能框架(SAIF)、NeMo Guardrails或MITRE ATLAS等現有框架,將安全措施納入其人工智能系統中。
企業還需要監控和記錄用戶與LLM的互動,并定期審核和審查LLM的響應,以檢測潛在的安全和隱私問題,并相應地更新和微調LLM。
來源:GoUpSec